文章目录
第8章 一种全新的读取数据方式 Dataset API
8.1 Dataset API简介
Dataset API可以用简单复用的方式构建复杂的Input Pipeline。例如:一个图片模型的Pipeline可能会聚合在一个分布式文件系统中的多个文件,对每个图片进行随机扰动(random perturbations),接着将随机选中的图片合并到一个training batch中。一个文本模型的Pipeline可能涉及到:从原始文本数据中抽取特征,并通过一个转换(Transformation)将不同的长度序列batch在一起。Dataset API可以很方便地以不同的数据格式处理大量的数据,以及处理复杂的转换。
Dataset API是TensorFlow 1.3版本中引入的一个新的模块,主要用于数据读取,构建输入数据的pipeline等。之前,在TensorFlow中读取数据一般有两种方法:
使用placeholder读内存中的数据
使用queue读硬盘中的数据
Dataset API同时支持从内存和硬盘的读取,相比之前的两种方法在语法上更加简洁易懂。
此外,如果想要使用TensorFlow新出的Eager模式,就必须要使用Dataset API来读取数据。
Dataset API的导入,在TensorFlow 1.3中,Dataset API是放在contrib包中的:
tf.contrib.data.Dataset,而在TensorFlow 1.4中,Dataset API已经从contrib包中移除,变成了核心API的一员:tf.data.Dataset
8.2 Dataset API 架构
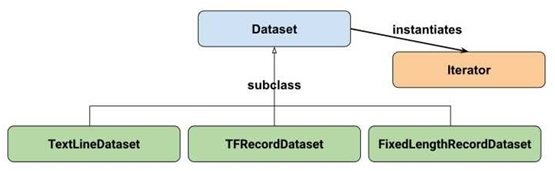
图1 Dataset API架构图
Dataset API引入了两个新的抽象类到Tensorflow中:
tf.data.Dataset
表示一串元素(elements),其中每个元素包含了一或多个Tensor对象。例如:在一个图片pipeline中,一个元素可以是单个训练样本,它们带有一个表示图片数据的tensors和一个label组成的pair。有两种不同的方式创建一个dataset:
(1)创建一个source (例如:Dataset.from_tensor_slices()), 从一或多个tf.Tensor对象中构建一个dataset
(2)应用一个transformation(例如:Dataset.batch()),从一或多个tf.contrib.data.Dataset对象上构建一个dataset
tf.data.Iterator
它提供了主要的方式来从一个dataset中抽取元素。通过Iterator.get_next() 返回的该操作会yields出Datasets中的下一个元素,作为输入pipeline和模型间的接口使用。最简单的iterator是一个“one-shot iterator”,它与一个指定的Dataset相关联,通过它来进行迭代。对于更复杂的使用,Iterator.initializer操作可以使用不同的datasets重新初始化(reinitialize)和参数化(parameterize)一个iterator ,例如,在同一个程序中通过training data和validation data迭代多次。
以下为生成Dataset的常用方法:
(1)tf.data.Dataset.from_tensor_slices()
利用tf.data.Dataset.from_tensor_slices()从一或多个tf.Tensor对象中构建一个dataset,
其tf.Tensor对象中包括数组、矩阵、字典、元组等,具体实例如下:
import numpy as np
arry1=np.array([1.0, 2.0, 3.0, 4.0, 5.0])
dataset = tf.data.Dataset.from_tensor_slices(arry1)
#生成实例
iterator = dataset.make_one_shot_iterator()
#从iterator里取出一个元素
one_element = iterator.get_next()
with tf.Session() as sess:
for i in range(len(arry1)):
print(sess.run(one_element))
运行结果为:1,2,3,4,5
(2)Dataset的转换(transformations)
支持任何结构的datasets当使用Dataset.map(),Dataset.flat_map(),以及Dataset.filter()
Dataset支持一类特殊的操作:Transformation。一个Dataset通过Transformation变成一个新的Dataset。通常我们可以通过Transformation完成数据变换,常用的Transformation有:
map()、flat_map()、filter()、filter()、shuffle()、repeat()、tf.py_func()等等。以下是一些简单示例:
import numpy as np
a1=np.array([1.0, 2.0, 3.0, 4.0, 5.0])
dataset = tf.data.Dataset.from_tensor_slices(a1)
dataset = dataset.map(lambda x: x * 2) # 2.0, 3.0, 4.0, 5.0, 6.0
iterator = dataset.make_one_shot_iterator()
#从iterator里取出一个元素
one_element = iterator.get_next()
with tf.Session() as sess:
for i in range(len(a1)):
print(sess.run(one_element))
flat_map()、filter()等的使用
#然后将它们的内容顺序连接成一个单一的“扁平”数据集
#跳过第一行(标题行)
#滤除以“#”开头的行(注释)
filenames = ["/var/data/file1.txt", "/var/data/file2.txt"]
dataset = tf.data.Dataset.from_tensor_slices(filenames)
dataset = dataset.flat_map(
lambda filename: (
tf.data.TextLineDataset(filename)
.skip(1)
.filter(lambda line: tf.not_equal(tf.substr(line, 0, 1), "#"))))
batch()、shuffle()、repeat()
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.shuffle(buffer_size=10000)
dataset = dataset.batch(32)
dataset = dataset.repeat(4)
(3)tf.data.TextLineDataset()
很多数据集是一个或多个文本文件。tf.contrib.data.TextLineDataset提供了一种简单的方式来提取这些文件的每一行。给定一个或多个文件名,TextLineDataset会对这些文件的每行生成一个值为字符串的元素。TextLineDataset也可以接受tf.Tensor作为filenames,所以你可以传递一个tf.placeholder(tf.string)作为参数。这个函数的输入是一个文件的列表,输出是一个dataset。dataset中的每一个元素就对应了文件中的一行。可以使用这个函数来读入CSV文件
dataset = tf.data.TextLineDataset(filenames)
默认下,TextLineDataset生成每个文件中的每一行,这可能不是你所需要的,例如文件中有标题行,或包含注释。可以使用Dataset.skip()和Dataset.filter()来剔除这些行。为了对每个文件都各自应用这些变换,使用Dataset.flat_map()来对每个文件创建一个嵌套的Dataset。
dataset = tf.contrib.data.Dataset.from_tensor_slices(filenames)
# Use <code>Dataset.flat_map()</code> to transform each file as a separate nested dataset,
# and then concatenate their contents sequentially into a single "flat" dataset.
# * Skip the first line (header row).
# * Filter out lines beginning with "#" (comments).
dataset = dataset.flat_map(
lambda filename: (
tf.contrib.data.TextLineDataset(filename)
.skip(1)
.filter(lambda line: tf.not_equal(tf.substr(line, 0, 1), "#"))))
(4)tf.data.FixedLengthRecordDataset():
这个函数的输入是一个文件的列表和一个record_bytes,之后dataset的每一个元素就是文件中固定字节数record_bytes的内容。通常用来读取以二进制形式保存的文件,如CIFAR10数据集就是这种形式。
(5)tf.data.TFRecordDataset():
TFRecord是一种面向记录的二进制文件,很多TensorFlow应用使用它作为训练数据。tf.contrib.data.TFRecordDataset能够使TFRecord文件作为输入管道的输入流。
dataset = tf.data.TFRecordDataset(filenames)
传递给TFRecordDataset的参数filenames可以是字符串,字符串列表或tf.Tensor类型的字符串。因此,如果有两组文件分别作为训练和验证,可以使用tf.placeholder(tf.string)来表示文件名,使用适当的文件名来初始化一个迭代器。
dataset = tf.data.TFRecordDataset(filenames)
iterator = dataset.make_initializable_iterator()
training_filenames = ["/var/data/file1.tfrecord", "/var/data/file2.tfrecord"]
with tf.Session() as sess:
sess.run(iterator.initializer, feed_dict={filenames: training_filenames})
# Initialize <code>iterator</code> with validation data.
validation_filenames = ["/var/data/validation1.tfrecord", ...]
sess.run(iterator.initializer, feed_dict={filenames: validation_filenames})
8.3 使用Dataset Tensor实例
以上我们通过一个实例来介绍Dataset API的具体使用,实例内容用MNIST数据集为原数据,使用卷积神经网络,对手写0-9十个数字进行识别。
环境配置信息为:Python3.6,Tensorflow1.3,使用CPU
具体步骤如下:
定义获取、预处理数据集的代码
加载数据
创建Dataset Tensor
创建卷积神经网络
训练及评估模型
8.3.1.导入需要的库
import struct
import numpy as np
import tensorflow as tf
8.3.2.定义一个把标签变为热编码(one-hot)的函数
"""Convert class labels from scalars to one-hot vectors."""
num_labels = labels_dense.shape[0]
index_offset = np.arange(num_labels) * num_classes
labels_one_hot = np.zeros((num_labels, num_classes))
labels_one_hot.flat[index_offset + labels_dense.ravel()] = 1
return labels_one_hot
8.3.3.定义加载数据函数
"""Load MNIST data from path"""
labels_path = os.path.join(path, '%s-labels-idx1-ubyte' % kind)
images_path = os.path.join(path, '%s-images-idx3-ubyte' % kind)
with open(labels_path, 'rb') as lbpath:
magic, n = struct.unpack('>II',lbpath.read(8))
labels = np.fromfile(lbpath, dtype=np.uint8)
labels=dense_to_one_hot(labels)
with open(images_path, 'rb') as imgpath:
magic, num, rows, cols = struct.unpack(">IIII",imgpath.read(16))
images = np.fromfile(imgpath, dtype=np.uint8).reshape(len(labels), 784)
#images = np.fromfile(imgpath, dtype=np.float32).reshape(len(labels), 784)
return images, labels
8.3.4 加载数据
%matplotlib inline
X_train, y_train = load_mnist('./data/mnist/', kind='train')
print('Rows: %d, columns: %d' % (X_train.shape[0], X_train.shape[1]))
print('Rows: %d, columns: %d' % ( y_train.shape[0], y_train.shape[1]))
X_test, y_test = load_mnist('./data/mnist/', kind='t10k')
print('Rows: %d, columns: %d' % (X_test.shape[0], X_test.shape[1]))
运行结果:
Rows: 60000, columns: 784
Rows: 60000, columns: 10
Rows: 10000, columns: 784
8.3.5 定义参数
learning_rate = 0.001
num_steps = 2000
batch_size = 128
display_step = 100
# Network Parameters
n_input = 784 # MNIST data input (img shape: 28*28)
n_classes = 10 # MNIST total classes (0-9 digits)
dropout = 0.75 # Dropout, probability to keep units
8.3.6 创建Dataset Tensor
# Create a dataset tensor from the images and the labels
dataset = tf.contrib.data.Dataset.from_tensor_slices(
(X_train.astype(np.float32),y_train.astype(np.float32)))
# Create batches of data
dataset = dataset.batch(batch_size)
# Create an iterator, to go over the dataset
iterator = dataset.make_initializable_iterator()
# It is better to use 2 placeholders, to avoid to load all data into memory,
# and avoid the 2Gb restriction length of a tensor.
_data = tf.placeholder(tf.float32, [None, n_input])
_labels = tf.placeholder(tf.float32, [None, n_classes])
# Initialize the iterator
sess.run(iterator.initializer, feed_dict={_data: X_train.astype(np.float32),
_labels: y_train.astype(np.float32)})
# Neural Net Input
X, Y = iterator.get_next()
8.3.7 创建卷积神经网络模型
def conv_net(x, n_classes, dropout, reuse, is_training):
# Define a scope for reusing the variables
with tf.variable_scope('ConvNet', reuse=reuse):
# MNIST data input is a 1-D vector of 784 features (28*28 pixels)
# Reshape to match picture format [Height x Width x Channel]
# Tensor input become 4-D: [Batch Size, Height, Width, Channel]
x = tf.reshape(x, shape=[-1, 28, 28, 1])
# Convolution Layer with 32 filters and a kernel size of 5
conv1 = tf.layers.conv2d(x, 32, 5, activation=tf.nn.relu)
# Max Pooling (down-sampling) with strides of 2 and kernel size of 2
conv1 = tf.layers.max_pooling2d(conv1, 2, 2)
# Convolution Layer with 32 filters and a kernel size of 5
conv2 = tf.layers.conv2d(conv1, 64, 3, activation=tf.nn.relu)
# Max Pooling (down-sampling) with strides of 2 and kernel size of 2
conv2 = tf.layers.max_pooling2d(conv2, 2, 2)
# Flatten the data to a 1-D vector for the fully connected layer
fc1 = tf.contrib.layers.flatten(conv2)
# Fully connected layer (in contrib folder for now)
fc1 = tf.layers.dense(fc1, 1024)
# Apply Dropout (if is_training is False, dropout is not applied)
fc1 = tf.layers.dropout(fc1, rate=dropout, training=is_training)
# Output layer, class prediction
out = tf.layers.dense(fc1, n_classes)
# Because 'softmax_cross_entropy_with_logits' already apply softmax,
# we only apply softmax to testing network
out = tf.nn.softmax(out) if not is_training else out
return out
8.3.8 训练及评估模型
# need to create 2 distinct computation graphs that share the same weights.
# Create a graph for training
logits_train = conv_net(X, n_classes, dropout, reuse=False, is_training=True)
# Create another graph for testing that reuse the same weights, but has
# different behavior for 'dropout' (not applied).
logits_test = conv_net(X, n_classes, dropout, reuse=True, is_training=False)
# Define loss and optimizer (with train logits, for dropout to take effect)
loss_op = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(
logits=logits_train, labels=Y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
train_op = optimizer.minimize(loss_op)
# Evaluate model (with test logits, for dropout to be disabled)
correct_pred = tf.equal(tf.argmax(logits_test, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Initialize the variables (i.e. assign their default value)
init = tf.global_variables_initializer()
sess.run(init)
for step in range(1, num_steps + 1):
try:
# Run optimization
sess.run(train_op)
except tf.errors.OutOfRangeError:
# Reload the iterator when it reaches the end of the dataset
sess.run(iterator.initializer,
feed_dict={_data: X_train.astype(np.float32),
_labels: y_train.astype(np.float32)})
sess.run(train_op)
if step % display_step == 0 or step == 1:
# Calculate batch loss and accuracy
# (note that this consume a new batch of data)
loss, acc = sess.run([loss_op, accuracy])
print("Step " + str(step) + ", Minibatch Loss= " + \
"{:.4f}".format(loss) + ", Training Accuracy= " + \
"{:.3f}".format(acc))
print("Optimization Finished!")
运行结果如下:
Step 1, Minibatch Loss= 182.4177, Training Accuracy= 0.258
Step 100, Minibatch Loss= 0.6034, Training Accuracy= 0.891
Step 200, Minibatch Loss= 0.4140, Training Accuracy= 0.930
Step 300, Minibatch Loss= 0.0813, Training Accuracy= 0.977
Step 400, Minibatch Loss= 0.1380, Training Accuracy= 0.969
Step 500, Minibatch Loss= 0.1193, Training Accuracy= 0.945
Step 600, Minibatch Loss= 0.3291, Training Accuracy= 0.953
Step 700, Minibatch Loss= 0.2158, Training Accuracy= 0.969
Step 800, Minibatch Loss= 0.1293, Training Accuracy= 0.977
Step 900, Minibatch Loss= 0.1323, Training Accuracy= 0.977
Step 1000, Minibatch Loss= 0.2017, Training Accuracy= 0.961
Step 1100, Minibatch Loss= 0.1555, Training Accuracy= 0.961
Step 1200, Minibatch Loss= 0.0744, Training Accuracy= 0.992
Step 1300, Minibatch Loss= 0.1331, Training Accuracy= 0.969
Step 1400, Minibatch Loss= 0.1279, Training Accuracy= 0.977
Step 1500, Minibatch Loss= 0.0733, Training Accuracy= 0.984
Step 1600, Minibatch Loss= 0.1529, Training Accuracy= 0.969
Step 1700, Minibatch Loss= 0.1223, Training Accuracy= 0.977
Step 1800, Minibatch Loss= 0.0503, Training Accuracy= 0.992
Step 1900, Minibatch Loss= 0.1077, Training Accuracy= 0.977
Step 2000, Minibatch Loss= 0.0344, Training Accuracy= 0.992
Optimization Finished!
参考博客:
https://www.leiphone.com/news/201711/zV7yM5W1dFrzs8W5.html
http://d0evi1.com/tensorflow/datasets/
Very nicce article, totally what I needed.
Pingback引用通告: TensorFlow读写数据 – 闪念基因
Pingback引用通告: TensorFlow读写数据 – 技术成就梦想
博客大好,让人忘不了!
Pingback引用通告: Python与人工智能 – 飞谷云人工智能