文章目录
第2章 概率与信息论
本章讨论概率论和信息论,概率论是用于表示不确定性陈述的数学框架,即它是对事物不确定性的度量。
在人工智能领域,我们主要以两种方式来使用概率论。首先,概率法则告诉我们AI系统应该如何推理,所以我们设计一些算法来计算或者近似由概率论导出的表达式。其次,我们可以用概率和统计从理论上分析我们提出的AI系统的行为。
计算机科学的许多分支处理的对象都是完全确定的实体,但机器学习却大量使用概率论。实际上如果你了解机器学习的工作原理你就会觉得这个很正常。因为机器学习大部分时候处理的都是不确定量或随机量。
概率论和信息论是众多科学学科和工程学科的基础,也是机器学习、深度学习的重要基础。
如果你对概率论和信息论很熟悉了,可以跳过这章。如果你觉得这些内容还不够,还想进一步了解相关知识,可以参考相关专业教材。
2.1为何要概率、信息论
机器学习、深度学习需要借助概率、信息论?
要回答这个问题,我觉得至少应该了解以下两个问题:
(1)概率、信息论的主要任务;
(2)机器学习、深度学习与概率、信息论有哪些因缘。
概率研究对象不是预习知道或确定的事情,而是预习不确定或随机事件。研究这些不确定或随机事件背后规律或规则。或许有人会说,这些不确定或随机事件有啥好研究?他们本来就不确定或随机的,飘忽不定、不可捉摸。表面上看起来确实如此,有句话说得好:偶然中有必然,必然中有偶然。就拿我们比较熟悉微积分来说吧,如果单看有限的几步,很多问题都杂乱无章,还难处理,但是一旦加上一个无穷大(∞)这个“照妖镜”,其背后规律立显、原来难处理的也好处理了。概率研究的对象也类似。如大数定律、各种分布等等。
信息论主要研究对一个信号包含信息的多少进行量化。它的基本思想是一个不太可能的事件居然发生了,其提供的信息量要比一个非常可能发生的事件更多。这个看起来,也好像与我们的直觉相矛盾。
说起机器学习、深度学习与概率、信息论的因缘可就多了:
(1)被建模系统内在的随机性。例如一个假想的纸牌游戏,在这个游戏中我们假设纸牌被真正混洗成了随机顺序。
(2不完全观测。即使是确定的系统,当我们不能观测到所有驱动系统行为的所有变量或因素时,该系统也会呈现随机性。
(3)不完全建模。例如,假设我们制作了一个机器人,它可以准确地观察周围每一个对象的位置。 在对这些对象将来的位置进行预测时,如果机器人采用的是离散化的空间,那么离散化的方法将使得机器人无法确定对象们的精确位置:因为每个对象都可能处于它被观测到的离散单元的任何一个角落。也就是说,当不完全建模时,我们不能明确的确定结果,这个时候的不确定,就需要借助概率来处理。
由此看来,概率、信息论很重要,机器学习、深度学习确实很需要它们。后续我们可以看到很多实例,见证概率、信息论在机器学习、深度学习中是如何发挥它们作用的。
2.2样本空间与随机变量
样本空间
样本空间是一个实验或随机试验所有可能结果的集合,而随机试验中的每个可能结果称为样本点。例如,如果抛掷一枚硬币,那么样本空间就是集合{正面,反面}。如果投掷一个骰子,那么样本空间就是 {1,2,3,4,5,6}。
随机变量
随机变量,顾名思义,就是“其值随机而定”的变量,一个随机试验有许多可能结果,到底出现哪个预先是不知道的,其结果只有等到试验完成后,才能确定。如掷骰子,掷出的点数X是一个随机变量,它可以取1,2,3,4,5,6中的任何一个,到底是哪一个,要等掷了骰子以后才知道。因此,随机变量又是试验结果的函数,它为每一个试验结果分配一个值。比如,在一次扔硬币事件中,如果把获得的背面的次数作为随机变量X,则X可以取两个值,分别是0和1。如果随机变量X的取值是有限的或者是可数无穷尽的值,如:

2.3概率分布
概率分布用来描述随机变量(含随机向量)在每一个可能取到的状态的可能性大小。概率分布的有不同方式,这取决于随机变量是离散的还是连续的。
对于随机变量X,其概率分布通常记为P(X=x),或X ~P(x),表示X服从概率分布P(x)。
概率分布描述了取单点值的可能性或概率,但在实际应用中,我们并不关心取某一值的概率,特别是对连续型随机变量,它在某点的概率都是0,这个后续章节将介绍。因此,我们通常比较关心随机变量落在某一区间的概率,为此,引入分布函数的概念。

2.3.1 离散型随机变量


例如,设X的概率分布由例1给出,则
F(2)=P(X≤2)=P(X=0)+P(X=l)=0.04+0.32=0.36
常见的离散随机变量的分布有:
(1)两点分布
若随机变量X只可能取0和1两个值,且它的分布列为P(X=1)=p,P(X = 0) = l − P 其中(0 < P < 1),则称X服从参数为p的两点分布,记作X~B(1, p)。其分布函数为

(2)二项分布
二项分布是最重要的离散概率分布之一,由瑞士数学家雅各布•伯努利(Jokab Bernoulli)所发展,一般用二项分布来计算概率的前提是,每次抽出样品后再放回去,并且只能有两种试验结果,比如黑球或红球,正品或次品等。二项分布指出,随机一次试验出现的概率如果为p,那么在n次试验中出现k次的概率为:
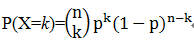
假设随机变量X满足二项分布,且知道n,p,k等参数,我们如何求出各种情况的概率值呢?方法比较多,这里介绍一种非常简单的方法,利用Python的scipy库可以非常简单,直接利用这个统计接口stats即可,具体如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import numpy as np import matplotlib.pyplot as plt import math from scipy import stats %matplotlib inline n = 20 p = 0.3 k = np.arange(0,41) #定义二项分布 binomial = stats.binom.pmf(k,n,p) #二项分布可视化 plt.plot(k, binomial, 'o-') plt.title('binomial:n=%i,p=%.2f'%(n,p),fontsize=15) plt.xlabel('number of success') plt.ylabel('probalility of success', fontsize=15) plt.grid(True) plt.show() |
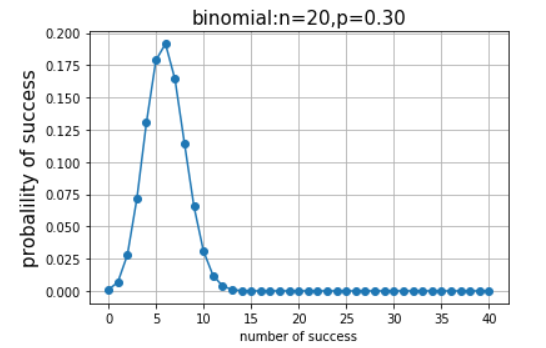
(3)泊松(Poisson)分布
若随机变量X所有可能取值为0,1,2,…,它取各个值的概率为:

这里介绍了离散型随机变量的分布情况,如果X是连续型随机变量,其分布函数通常通过密度函数来描述,具体请看下一节
2.3.2 连续型随机变量
与离散型随机变量不同,连续型随机变量采用概率密度函数来描述变量的概率分布。如果一个函数f(x)是密度函数,满足以下三个性质,我们就称f(x)为概率密度函数。


图2-1 概率密度函数
对连续型随机变量在任意一点的概率处处为0。
假设有任意小的实数∆x,由于{X=x}⊂{x-∆x<X≤x},由式(2.1)分布函数的定义可得:

这个连续分布被称之为正态分布,或者高斯分布。其密度函数的曲线呈对称钟形,因此又被称之为钟形曲线,其中μ是平均值,σ是标准差(何为平均值、标准差后续我们会介绍)。正态分布是一种理想分布。
正态分布如何用Python实现呢?同样,我们可以借助其scipy库中stats来实现,非常方便。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
import numpy as np import matplotlib.pyplot as plt from scipy import stats %matplotlib inline #平均值或期望值 mu=0 #标准差 sigma1=1 sigma2=2 #随机变量的取值 x=np.arange(-6,6,0.1) y1=stats.norm.pdf(x,0,1) #定义正态分布的密度函数 y2=stats.norm.pdf(x,0,2) #定义正态分布的密度函数 plt.plot(x,y1,label='sigma is 1') plt.plot(x,y2,label='sigma is 2') plt.title('normal $\mu$=%.1f,$\sigma$=%.1f or %.1f '%(mu,sigma1,sigma2)) plt.xlabel('x') plt.ylabel('probability density') plt.legend(loc='upper left') plt.show() |

正态分布的取值可以从负无穷到正无穷。这里我们为便于可视化,只取把X数据定义在[-6,6]之间,用stats.norm.pdf得到正态分布的概率密度函数。另外从图形可以看出,上面两图的均值u都是0,只是标准差(σ)不同,这就导致图像的离散程度不同,标准差大的更分散,个中原因,我们在介绍随机变量的数字特征时将进一步说明。
2.4边缘概率
对于多维随机变量,如二维随机变量(X,Y),假设其联合概率分布为F(x,y),我们经常遇到求其中一个随机变量的概率分布的情况。这种定义在子集上的概率分布称为边缘概率分布。
例如,假设有两个离散的随机变量X,Y,且知道P(X,Y),那么我们可以通过下面求和的方法,得到边缘概率P(X):
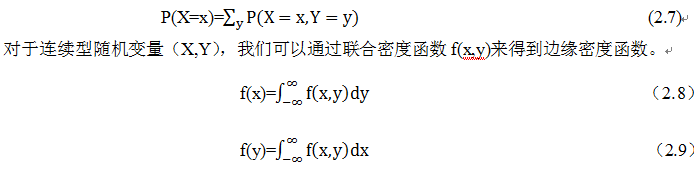
边缘概率如何计算呢?这里我们通过一个实例来说明。假设有两个离散型随机变量X,Y,其联合分布概率如下:
表1.1:X与Y的联合分布

如果我们要求P(Y=0)的边缘概率,根据式(2.7)可得:
P(Y=0)=P(X=1,Y=0)+P(X=2,Y=0)=0.05+0.28=0.33
2.5条件概率
上一节我们介绍了边缘概率,它是值多维随机变量一个子集(或分量)上的概率分布。对于含多个随机变量的事件中,经常遇到求某个事件在其它事件发生的概率,例如,在表1.1的分布中,假设我们要求当Y=0的条件下,求X=1的概率?这种概率叫作条件概率。条件概率如何求?我们先看一般情况。
设有两个随机变量X,Y,我们将把X=x,Y=y发生的条件概率记为P(Y=y|X=x),那么这个条件概率可以通过以下公式计算:

其中P(Y=0)是一个边缘概率,其值为:P(X=1,Y=0)+P(X=2,Y=0)=0.05+0.28=0.33
而P(X=1,Y=0)=0.05.故P(X=1|Y=0)=0.05/0.33=5/33
2.6条件概率的链式法则
条件概率的链式法则,又称为乘法法则,把式(2.10)变形,可得到条件概率的乘法法则:
P(X,Y)=P(X)xP(Y|X) (2.11)
根据式(2.11)可以推广到多维随机变量,如:
P(X,Y,Z)=P(Y,Z)xP(X|Y,Z)
而P(Y,Z)=P(Z)xP(Y|Z)
由此可得:P(X,Y,Z)=P(X|Y,Z)x P(Y|Z)xP(Z) (2.12)
更多维的情况,以此类推。
2.7独立性及条件独立性
两个随机变量X,Y,如果它们的概率分布可以表示为两个因子的乘积,并一个因子只含x,另一个因子只含y,那么我们就称这两个随机变量互相独立。这句话可能不好理解,我们换一种方式的来表达。或许更好理解。
如果对 ∀x∈X,y∈Y,P(X=x,Y=y)=P(X=x)P(Y=y) 成立,那么随机变量X,Y互相独立。
在机器学习中,随机变量为互相独立的情况非常普遍,一旦互相独立,联合分布的计算就变得非常简单。
这是不带条件的随机变量的独立性定义,如果两个随机变量带有条件,如P(X,Y|Z),它的独立性如何定义呢?这个与上面的定义类似。具体定义如下:
如果对∀x∈X,y∈Y,z∈Z,P(X=x,Y=y|Z=z)=P(X=x|Z=z)P(Y=y|Z=z) 成立
那么随机变量X,Y在给定随机变量Z时是条件独立的。
为便于表达,如果随机变量X,Y互相独立,又可记为X⊥Y,如果随机变量X,Y在给定时互相独立,则可记为X⊥Y|Z。
以上主要介绍离散型随机变量的独立性和条件独立性,如果是连续型随机变量,我们只要把概率换成随机变量的密度函数即可。

2.8期望、方差、协方差
在机器学习、深度学习中经常需要分析随机变量的数据特征及随机变量间的关系等,对于这些指标的衡量在概率统计中有相关的内容,如用来衡量随机变量的取值大小的期望(Expectation)值或平均值、衡量随机变量数据离散程度的方差(Variance)、揭示随机向量间关系的协调方差(Convariance)等。
这些衡量指标的定义及公式就是本节主要内容。
首先我们看随机变量的数学期望的定义:
对离散型随机变量X,设其分布律为:


期望有一些重要性质,具体如下:
设a,b为一个常数,X和Y是两个随机变量。则有:
(1)E(a)=a
(2)E(aX)=aE(X)
(3)E(aX+bY)=aE(X)+bE(Y) (2.19)
(4)当X和Y相互独立时,则有:
E(XY)=E(X)E(Y) (2.20)
数学期望也常称为均值,即随机变量取值的平均值之意,当然这个平均,是指以概率为权的加权平均。期望值可大致描述数据的大小,但无法描述数据的离散程度,这里我们介绍一种刻画随机变量在其中心位置附近离散程度的数字特征,即方差。如何定义方差?
假设随机向量X有均值E(X)=a。试验中,X取的值当然不一定恰好是a,可能会有所偏离。偏离的量X-a本身也是一个随机变量。如果我们用X-a来刻画随机变量X的离散程度,当然不能取X-a的均值,因E(X-a)=0 ,说明正负偏离抵消了,当然我们可以取|X-a|这样可以防止正负抵消的情况,但绝对值在实际运算时很不方便。人们就考虑另一种方法,先对X-a平方以便消去符号,然后再取平均得
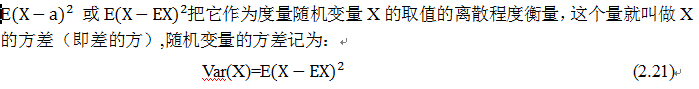
方差的平方根被称为标准差。
对于多维随机向量,如二维随机向量(X,Y)如何刻画这些分量间的关系?显然均值、方差都无能为力。这里我们引入协方差的定义,我们知道方差是X-EX乘以X-EX的均值,如果我们把其中一个换成Y-EY,就得到E(X-EX)(Y-EY),其形式接近方差,又有X,Y两者的参与,由此得出协方差的定义,随机变量X,Y的协方差,记为:Cov(X,Y)
Cov(X,Y) = E(X-EX)(Y-EY) (2.22)
协方差的另一种表达方式:
Cov(X,Y) = E(XY)-EX×EY (2.23)
方差可以用来衡量随机变量与均值的偏离程度或随机变量取值的离散度,而协方差则可衡量随机变量间的相关性强度,如果X与Y独立,那么它们的协方差为0。注意反之,并不一定成立,独立性比协方差为0的条件更强。不过如果随机变量X、Y都是正态分布,此时独立和协方差为0是一个概念。
当协方差为正时,表示随机变量X、Y为正相关;如果协方差为负,表示随机变量X、Y为负相关。
为了更好的衡量随机变量间的相关性,我们一般使用相关系数来衡量,相关系数将每个变量的贡献进行归一化,使其只衡量变量的相关性而不受各变量尺寸大小的影响,相关系统的计算公式如下:

求随机变量的方差、协方差、相关系统等,使用Python的numpy相关的函数,如用numpy.var求方差,numpy.cov求协方差,使用numpy.corrcoef求相关系数,比较简单,这里就不展开来说。
在机器学习中多维随机向量,通常以矩阵的方式出现,所以求随机变量间的线性相关性,就转换为求矩阵中列或行的线性相关性。这里我们举一个简单实例,来说明如果分析向量间的线性相关性并可视化结果。这个例子中使用的随机向量(或特征值)共有三个,一个是气温(temp),一个体感温度(atemp),一个是标签(label)说明共享单车每日出租量,以下是这三个特征的部分数据:
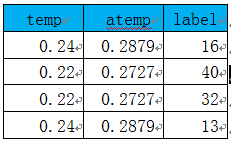
这里使用Python中数据分析库pandas及画图库matplotlib 、sns等。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
###探索特征间分布、相关性等 import pandas as pd import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline data_pd=data1.toPandas() sns.set(style='whitegrid',context='notebook') cols=['temp','atemp','label'] sns.pairplot(data_pd[cols],size=2.5) plt.show() |

从以上图可以看出,特征temp与atemp是线性相关的,其分布接近正态分布。
2.9贝叶斯定理
贝叶斯定理是概率论中的一个定理,它跟随机变量的条件概率以及边缘概率分布有关。在有些关于概率的解释中,贝叶斯定理(贝叶斯公式)能够告知我们如何利用新证据修改已有的看法。这个名称来自于托马斯•贝叶斯。
通常,事件A在事件B(发生)的条件下的概率,与事件B在事件A(发生)的条件下的概率是不一样的;然而,这两者是有确定的关系的,贝叶斯定理就是这种关系的陈述。贝叶斯公式的一个用途在于通过已知的三个概率函数推出第四个。
贝叶斯公式为:

2.10信息论
信息论是应用数学的一个分支,主要研究的是对信号所含信息的多少进行量化。它的基本想法是一个不太可能的事件居然发生了,要比一个非常可能的事件发生能提供更多的信息。本节主要介绍度量信息的几种常用指标,如信息量、信息熵、条件熵、互信息、交叉熵等。
2.10.1 信息量
1948年克劳德•香农(Claude Shannon)发表的论文“通信的数学理论”是世界上首次将通讯过程建立了数学模型的论文,这篇论文和1949年发表的另一篇论文一起奠定了现代信息论的基础。信息量是信息论中度量信息多少的一个物理量。它从量上反应具有确定概率的事件发生时所传递的信息。香农把信息看作是“一种消除不确定性”的量,而概率正好是表示随机事件发生的可能性大小的一个量,因此,可以用概率来定量地描述信息。
在实际运用中,信息量常用概率的负对数来表示,即,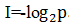 。为此,可能有不少人会问,为何用对数,前面还要带上负号?
。为此,可能有不少人会问,为何用对数,前面还要带上负号?
用对数表示是为了计算方便。因为直接用概率表示,在求多条信息总共包含的信息量时,要用乘法,而对数可以变求积为求和。另外,随机事件的概率总是小于1,而真实小于1的对数为负的,概率的对数之前冠以负号,其值便成为正数。所以通过消去不确定性,获取的信息量总是正的。
2.10.2 信息熵
信息熵(entropy)又简称为熵,是对随机变量不确定性的度量。熵的概念由鲁道夫•克劳修斯(Rudolf Clausius)于1850年提出,并应用在热力学中。1948年,克劳德•艾尔伍德•香农(Claude Elwood Shannon)第一次将熵的概念引入信息论中,因此它又称为香农熵。
用熵来评价整个随机变量X平均的信息量,而平均最好的量度就是随机变量的期望,即熵的定义如下:

我们利用Python具体实现以下概率p与H(X)的关系:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import numpy as np import matplotlib.pyplot as plt %matplotlib inline #定义概率列表 p=np.arange(0,1.05,0.05) HX=[] for i in p: if i==0 or i==1: HX.append(0) else: HX.append(-i*np.log2(i)-(1-i)*np.log2(1-i)) plt.plot(P,HX,label='entropy') plt.xlabel('p') plt.ylabel('H(X)') plt.show() |

从这个图形可以看出,当概率为0或1时,H(X)为0,说明此时随机变量没有不确定性,当p=0.5时,随机变量的不确定性最大,即信息量最大。H(X)此时取最大值。
2.10.3 条件熵
设二维随机变量(X,Y),其联合概率分布为:
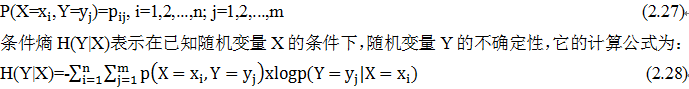
注意,这个条件熵,不是指随机变量X在给定某个数的情况下,另一个变量的熵是多少,变量的不确定性是多少?而是期望!因为条件熵中X也是一个变量,意思是在一个变量X的条件下(变量X的每个值都会取),另一个变量Y熵对X的期望。
条件熵比熵多了一些背景知识,按理说条件熵的不确定性小于熵的不确定,即H(Y|X)≤H(Y),事实也是如此,下面这个定理有力地说明了这一点。
定理:对二维随机变量(X,Y),条件熵H(Y|X)和信息熵H(Y)满足如下关系:
H(Y|X)≤H(Y) (2.29)
2.10.4 互信息
互信息(mutual information)又称为信息增益,用来评价一个事件的出现对于另一个事件的出现所贡献的信息量。记为:
I(X,Y)=H(Y)-H(Y|X) (2.30)
在决策树的特征选择中,信息增益为主要依据。在给定训练数据集D,假设数据集由n维特征构成,构建决策树时,一个核心问题就是选择哪个特征来划分数据集,使得划分后的纯度最大,一般而言,信息增益越大,意味着使用使用某属性a来划分所得“纯度提升”越大。因此,我们常用信息增益来进行决策树划分属性。
2.10.5 相对熵
相对熵(relative entropy),所谓相对,一般是在两个随机变量之间来说,又被称为KL散度(Kullback–Leibler divergence,KLD),这里我们假设 p(x) 和 q(x) 是 X 取值的两个概率分布,如p(x)表示X的真实分布,q(x)表示X的训练分布或预测分布。则 p 对 q 的相对熵为:

相对熵有些重要性质:
(1)相对熵不是传统意义上的距离,它没有对称性,即
KL(p(x)||q(x))≠KL(q(x)||p(x))
(2)当预测分布q(x)与真实分布p(x)完全相等时,相对熵为0;
(3)如果两个分别差异越大,那么相对熵也越大;反之,如果两个分布差异越小,相对熵也越小。
(4)相对熵满足非负性,即 KL(p(x)||q(x))≥0
2.10.5 交叉熵
交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。

Pingback引用通告: Python与人工智能 – 飞谷云人工智能