利用RNN生成中文语句实例
本实例使用2014人民日报上的一些新闻(约28万条,60M),使用PyTorch提供的nn.rnn模型,根据提示字符串预测给定长度的语句。
数据下载
提取码:6l9e
3.3.1 模型架构
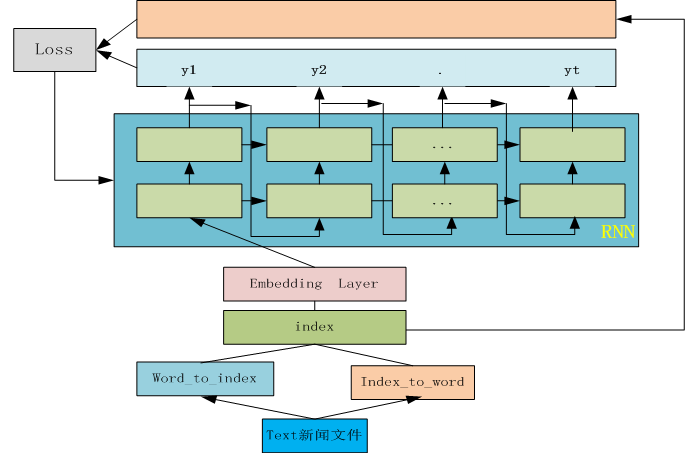
图1-13 RNN实例模型架构图
3.3.2 导入需要的模块
|
1 2 3 4 5 6 |
import argparse import torch from torch import nn import numpy as np from torch import nn, optim from torch.utils.data import DataLoader |
3.3.3 定义预处理函数
使用torch.utils.data生成可迭代的数据集。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
class Dataset(torch.utils.data.Dataset): def __init__(self,args,): self.args = args self.words = self.load_words() self.uniq_words = self.get_uniq_words() self.index_to_word = {index: word for index, word in enumerate(self.uniq_words)} self.word_to_index = {word: index for index, word in enumerate(self.uniq_words)} self.words_indexes = [self.word_to_index[w] for w in self.words] def load_words(self): """加载人民日报新闻数据集""" with open(r'D:\python-script\py\data\people_news-03.txt',encoding='UTF-8') as f: corpus_chars = f.read() #删除一些标点符合,回车符等 corpus_chars = corpus_chars.replace('。', '').replace('\r', '').replace(",", '').replace(",", '').replace("?", '').replace("!", '') corpus_chars = corpus_chars.replace("、", '').replace('\n', '').replace('\ufeff', '') corpus_chars = corpus_chars[0:15000] return corpus_chars def get_uniq_words(self): idx_to_char = list(set(self.words)) return idx_to_char def __len__(self): return len(self.words_indexes) - self.args.sequence_length def __getitem__(self, index): return ( torch.tensor(self.words_indexes[index:index+self.args.sequence_length]), torch.tensor(self.words_indexes[index+1:index+self.args.sequence_length+1]), ) |
3.3.4 定义模型
根据图1-13构建模型,以Embedding为输入层,隐含节点数为256,共两层。为何使用Embedding层作为输入层,而不使用One-hot编码作为输入层?Embedding输入层,除可以有效压缩维度空间外(与以one-hot编码为输入层),更重要的是Embedding层在整个迭代过程中参与学习。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
class Model(nn.Module): def __init__(self, dataset): super(Model, self).__init__() self.input_size = 128 self.hidden_size=256 self.embedding_dim = 128 self.num_layers = 2 n_vocab = len(dataset.uniq_words) self.embedding = nn.Embedding( num_embeddings=n_vocab, embedding_dim=self.embedding_dim, ) self.rnn = nn.RNN( input_size=self.input_size, hidden_size=self.hidden_size, num_layers=self.num_layers, ) self.fc = nn.Linear(self.hidden_size, n_vocab) def forward(self, x, prev_state): embed = self.embedding(x) output,state = self.rnn(embed, prev_state) logits = self.fc(output) return logits,state def init_state(self, sequence_length): return (torch.zeros(self.num_layers, sequence_length, self.hidden_size)) |
3.3.5 定义训练模型函数
为便于管理,这里参数传入采用argparse方式。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
def train(dataset, model, args): model.train() dataloader = DataLoader( dataset, batch_size=args.batch_size, ) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) for epoch in range(args.max_epochs): state = model.init_state(args.sequence_length) for batch, (x, y) in enumerate(dataloader): optimizer.zero_grad() y_pred, state = model(x, state) loss = criterion(y_pred.transpose(1, 2), y) state = state.detach() loss.backward() optimizer.step() print({ 'epoch': epoch, 'batch': batch, 'loss': loss.item() }) def predict(dataset, model, text, next_words=20): #words = text.split(' ') words = list(text) model.eval() state= model.init_state(len(words)) for i in range(0, next_words): x = torch.tensor([[dataset.word_to_index[w] for w in words[i:]]]) y_pred, state = model(x, state) last_word_logits = y_pred[0][-1] p = torch.nn.functional.softmax(last_word_logits, dim=0).detach().numpy() word_index = np.random.choice(len(last_word_logits), p=p) words.append(dataset.index_to_word[word_index]) return "".join(words) |
3.3.6 设置参数
这里参数设置运行环境为jupyter notebook ,如果在命令行运行需要做一些改动。
|
1 2 3 4 5 |
parser = argparse.ArgumentParser(description='rnn') parser.add_argument('--max-epochs', type=int, default=20) parser.add_argument('--batch-size', type=int, default=256) parser.add_argument('--sequence-length', type=int, default=20) args = parser.parse_args([]) |
3.3.7 运行模型
|
1 2 3 4 |
dataset = Dataset(args) model = Model(dataset) train(dataset, model, args) print(predict(dataset, model, text='坚持破除')) |
3.3.8 练习
1.把Emedding层改为One-hot层
2.目前学习率为固定,把固定改为动态(如与迭代次数相关关联),查看损失值的变化
3.修改学习率及迭代次数等,比较损失值的变化。
4.使用LSTM或GRU模型
5.使用GPT或BERT模型