文章目录
第6章 函数
6.1 问题:如何实现代码共享
这个这个代码块取一个名称,可以直接分享给其他人使用,如果在这个代码块中加上一些功能说明就完美。下节将介绍该功能的代码实现。
6.2 创建和调用函数
根据上节的一个具体需求,我们用一个函数来完成。具体代码如下:
(1)创建函数
|
1 2 3 4 5 6 7 8 9 |
#定义一个函数 def sum_1n(): #定义一个存放累加数的变量 j=0 #用range(1,11)生成1到10连续10个自然数,不包括11这个数。 for i in range(1,11): j+=i #把累加结果作为返回值 return j |
定义函数,要主要以下几点:
①定义函数的关键是def
②def 空格后 是函数名称,函数的命名规则与变量的规则一样。
③函数名后紧跟着是一对小括号(),这个不能少,小括号后面是冒号:
④冒号下面的语句将统一缩进4格
⑤最后用return语句 返回这个函数的执行结果,return一般是这个函数最后执行的语句,一般放在最后。当然,还有特殊情况,后续将介绍。
(2)调用这个函数,就可得到结果
|
1 |
sum_1n() #结果:55 |
(3)修改这个函数
如果把这个自然数固定为10,就失去灵活性了。如果把截止的这个自然数,作为参数传给函数,这样这个函数就可实现累加的任何一个自然数了。为此,我们稍加修改即可。
|
1 2 3 4 5 6 7 8 9 |
#定义一个函数,累加截止自然数为n,作为参数传给这个函数 def sum_1n(n): #定义一个存放累加数的变量 j=0 #用range(1,n+1)生成1到n连续n个自然数 for i in range(1,n+1): j+=i #把累加结果作为返回值 return j |
调用这个函数
|
1 2 3 |
sum_1n(10) #55 sum_1n(100) #5050 sum_1n(1000) #500500 |
(4)加上函数的帮助信息
这个函数到底起啥作用呢?我们可以在函数定义后,加上加一句功能说明或帮助信息,使用这样函数的人,一看这个说明就知道这个函数的功能,功能说明内容放在三个双引号""" """里。查看这个函数功能说明或帮助信息,无需打开这个函数,只要函数名.__doc__便可看到,非常方便。
|
1 2 3 4 5 6 7 8 9 10 |
#定义一个函数,累加截止自然数为n,作为参数传给这个函数 def sum_1n(n): """该函数的参数为自然数n,其功能为累加从1到n的n个连续自然数""" #定义一个存放累加数的变量 j=0 #用range(1,n+1)生成1到n连续n个自然数 for i in range(1,n+1): j+=i #把累加结果作为返回值 return j |
函数的功能说明或帮助信息,需放在函数的第一句。
查看函数功能说明或其帮助信息。
|
1 |
sum_1n.__doc__ # '该函数的参数为自然数n,其功能为累加从1到n的n个连续自然数' |
(5)优化函数
我们可以进一步优化这个函数,为便于大家的理解,使用了for循环。实际上,实现累加可以直接使用Python的内置函数sum即可,优化后的代码如下:
|
1 2 3 4 |
#定义一个函数,累加截止自然数为n,作为参数传给这个函数 def sum_1n(n): """该函数的参数为自然数n,其功能为累加从1到n的n个连续自然数""" return sum(range(1,n+1)) |
6.3 传递参数
在调用函数sum_1n(n)时,传入一个参数n,这是传入单个参数。Python支持更多格式的传入方式,可以传入多个参数、传入任意个参数等。接下来将介绍函数参数的一些定义及传入方式。
6.3.1 形参与实参
在定义函数时,如果需要传入参数,在括号里需要指明,如sum_1n(n)中n,这类参数就称为形式参数,简称为形参。
在调用函数或执行函数时,函数括号里的参数,如sum_1n(100)中的100,就是实际参数,简称为实参。
在具体使用时,有时人们为简便起见,不分形参和实参,有些参考资料上统称为参数。
函数定义中可以没有参数、一个参数或多个参数。如果有多个参数,在调用函数时也可能要多个实参。向函数传入实参的方式有很多,可以依据函数定义时的位置和顺序确定的位置参数;可以使用关键字实参;也可以使用列表和字典作为实参等。接下来将介绍这些内容。
6.3.2 位置参数
位置参数顾名思义就是跟函数定义时参数位置有关的参数,位置参数必须按定义函数时形参的顺序保持一致。
位置参数是必备参数,调用函数时根据函数定义的形参位置来传递实参。为了更好说明这个原理,还是以函数sum_1n为例。
假设现在修改一下要求,把从1开始累积,改为任何小于n的一个数(如m<n)累积,那么,m也需要作为参数。为此,修改一些函数sum_1n。
|
1 2 3 4 |
#定义一个函数,累加m至自然数n之间的所有自然数 def sum_1n(m,n): """该函数的参数为自然数m、n,其功能为累加从m到n的所有自然数""" return sum(range(m,n+1)) |
定义函数sum_1n时,指明了两个参数:m和n(如果多个参数,需要用逗号分隔),在调用函数sum_1n时,实参需要输入两个,而且这两个实参的位置及顺序必须与形参保持一致,如:
|
1 2 3 4 |
#累加1到10的所有自然数 sum_1n(1,10) #55 #累加10到20的所有自然数 sum_1n(10,20) #165 |
其中1,10或10,20就是位置实参。位置实参的顺序很重要,如果顺序不正确,可能报错或出现异常情况。
6.3.3 关键字参数
为此,我们把函数sum_1n的形参改成有一定含义的单词,调用是直接给这些单词赋值即可。
|
1 2 3 4 |
#定义一个函数,累加start至自然数end之间的所有自然数 def sum_1n(start,end): """该函数的参数为自然数start、end,其功能为累加从start到end的所有自然数""" return sum(range(start,end+1)) |
调用函数时,说明参数名并赋给对应值即可,无需考虑它们的位置或次序。当然,实参名称必须与形参名称一致,否则将报错。
|
1 2 |
sum_1n(start=1,end=10) #55 sum_1n(end=20,start=10) #165 |
6.3.4 默认值
使用默认值,修改一下函数sum_1n(start,end):
|
1 2 3 4 |
#定义一个函数,累加start至自然数end之间的所有自然数 def sum_1n(end,start=1): """该函数的参数为自然数start、end,其功能为累加从start到end的所有自然数""" return sum(range(start,end+1)) |
调用函数
|
1 2 3 4 |
#重新指定start的值 sum_1n(start=10,end=100) #不指定start的值,则start将使用默认值 sum_1n(end=100) |
6.4 返回值
在Python中,在函数体内用return语句为函数指定返回值,返回值可以是一个或多个,类型可以是任何类型。如果没有return语句,则返回None值,即返回空值。不管return语句在函数体的什么位置,执行完return语句后,就会立即结束函数的执行。下面介绍函数返回值的情况。
(1)返回一个值
上节介绍的函数sum_1n,只返回一个值。如:
|
1 |
sum_1n(start=10,end=100) #5005 |
(2)返回多个值
把函数sum_1n的返回值改一下,同时返回所有数的累加、偶数累加。
|
1 2 3 |
def sum_1n(start,end): """该函数的参数为自然数start、end,其功能为累加从start到end的所有自然数及偶数之和""" return sum(range(start,end+1)),sum([i for i in range(start,end+1) if i%2==0]) |
调用函数
|
1 2 3 4 5 |
sum_1n(start=10,end=100) #返回(5005, 2530) #把返回值,分别赋给两个变量 a,b=sum_1n(start=10,end=100) print("返回所有数之和:{},偶数之和:{}".format(a,b)) #返回所有数之和:5005,偶数之和:2530 |
(3)返回空值
在函数体中不使用return语句,不过可以用print语句把结果显示出来。
|
1 2 3 4 |
#定义一个函数,累加start至自然数end之间的所有自然数 def sum_1n(end,start=1): """该函数的参数为自然数start、end,其功能为累加从start到end的所有自然数""" print("累加结果:",sum(range(start,end+1))) |
调用函数
|
1 2 |
a=sum_1n(10) #打印:累加结果: 55 type(a) # NoneType |
6.5 传递任意数量的参数
前面我们介绍了Python支持的几种参数类型,如位置参数、关键字参数和默认值参数,适当使用这些参数,可大大提高Python函数的灵活性。此外,Python还支持列表或元组参数,即用列表或元组作为实参传入函数。例如:
|
1 2 3 4 5 6 7 8 9 10 11 |
#定义一个函数 def calc_sum(lst): sum=0 for i in lst: sum+=i return sum #实参以列表格式传入 calc_sum([1,4,5]) #10 calc_sum([-1,1,10,20]) #30 #实参以元组格式传入 calc_sum((-1,1,10,20)) #30 |
6.5.1 传递任意数量的实参
要实现输入任意数量的实参,只要在形参前加一个*号即可,比如函数calc_sum(lst)改为calc_sum(*lst)。形参加上*号后,在函数内部,把任意多个参数封装在lst这个元组中,因此,函数代码完全不变。但是,调用该函数时,可以传入任意个参数,包括0个参数,示例如下:
|
1 2 3 4 5 6 7 8 9 10 11 |
#定义一个函数,接受任意数量的参数 def calc_sum(*a1): sum=0 for i in a1: sum+=i return sum #调用函数 calc_sum(-1,1,0,20,30) #50 calc_sum(-10,0,10,-20,20,-30,30,100) #100 calc_sum() #0 |
通过这种方式传入任意多个实参,就和我们的预期一样了。
6.5.2 传递位置参数及任意数量的实参
位置参数可以和支持任意数量的实参一起使用,不过,如果遇到不同类型的实参时,必须在函数定义中,将接纳任意数量的实参的形参放在最后。Python先匹配位置实参和关键字实参,然后再将剩下的实参归为最后的实参里。例如:
#定义一个函数,把位置参数b和任意数量参数w累加。
|
1 2 3 4 5 6 7 8 9 10 |
#定义一个函数,size为位置参数、numb任意数量参数 #打印任意参数的和,在结果前放置size个'-'符号 def calc_add(size,*numb): sum=0 for i in numb: sum+=i print('-'*size+"输出结果为:"+str(sum)) #调用函数 calc_add(4,1,2,3,4) #----输出结果为:10 |
根据函数calc_add的定义,Python把调用函数的实参中,把第一个数4存储在size中,把剩下的所有值存储在元组numb中。
6.5.3 传递任务数量的关键字实参
Python支持采用关键字实参,而且也可以是任意数量,只要在定义函数时在对应的形参前加上两个*号即可(如**user_info)。把任意多个关键字参数封装在user_info这个字典中。对应的形参在函数内部将以字典的方式存储,调用函数需要采用 arg1=value1,arg2=value2 的形式。例如:
|
1 2 3 |
def customer(**user_info): for key,value in user_info.items(): print("{} is {}".format(key,value)) |
调用函数
|
1 |
customer(height=180,weight=70,age=30) |
运行结果
height is 180
weight is 70
age is 30
如果出现多种类型参数的情况,如既有位置形参,又有表示任意数量参数和任意数量的关键字形参的函数。如格式为customer(fargs, *args, **kwargs) 的函数。其中*args与**kwargs的都是python中的可变参数。 *args表示可传入任何多个无名实参, **kwargs表示可传入任意多个关键字实参,它本质上是一个dict。示例如下:
|
1 2 3 4 |
def customer(name,*subj_score,**user_info): print("{}".format(name),end=",") print("各科成绩{}".format(subj_score),end=",") print("身份信息:{}".format(user_info),end=",") |
调用函数
|
1 2 |
customer("高峰",100,90,80,height=180,weight=70,age=30) #高峰,各科成绩(100, 90, 80),身份信息:{'height': 180, 'weight': 70, 'age': 30}, |
当函数中有多种类型参数时,需注意以下问题:
①注意顺序,如果同时出现,fargs在前,*args必在**args之前。
②*args 相当于一个不定长的元组。
③**args 相当于一个不定长的字典。
6.6 函数装饰器
python装饰器不过就是一个针对嵌套函数的语法糖,它的作用就是在函数调用方法不变的情况下,增强原函数的功能,就像一根信号线加上(或装饰)一个插头就可充电一样。
装饰器何时使用?它有哪些神奇功能呢?
我们来看这样一个场景:
假如我原来写好一个函数fun(),这个函数已部署到生产环境,后来,客户说,需要监控该函数的运行时间,对此,如何处理呢?首先想到的可能是修改原函数,但有一点风险,尤其当该函数涉及面较广时。哪是否有不修改原函数,仍可达到目的方法呢?有的!我们可以添加一个函数,然后采用装饰器的方法就可达到目的,详细情况,请看下例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#testdeco.py # -*- coding:utf-8 -*- '''示例: 使用装饰器(decorator)示例 装饰函数的参数是被装饰的函数对象,返回原函数对象 装饰的实质语句: myfunc = deco(myfunc)''' def func(): y = 0 for i in range(100): y = y + i + 1 print(y) return y ##导入模块 from testdeco import * ##查看帮助信息 print(testdeco.__doc__) |
显示如下结果,这个结果正好是testdeco.pyz文件中的三个引号部分'''
示例: 使用装饰器(decorator)示例
装饰函数的参数是被装饰的函数对象,返回原函数对象
装饰的实质语句: myfunc = deco(myfunc)
在函数func外增加一个函数,统计运行函数func所耗时间的函数timelong,然后采用函数装饰器,这样我们就看不改变原函数func的情况下,增加函数func的功能,详细请看如下示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
#cat testdeco1.py # -*- coding:utf-8 -*- '''示例: 使用装饰器(decorator)示例 装饰函数的参数是被装饰的函数对象,返回原函数对象 装饰的实质语句: myfunc = decofun(myfunc)''' import time def timeslong(func): def call(): start = time.clock() print("It's time starting ! ") func() print("It's time ending ! ") end = time.clock() return "It's used : %s ." % (end - start) return call @timeslong ###相当于func=timeslong(func) def func(): y = 0 for i in range(100): y = y + i + 1 print(y) return y ####运行函数 %run testdeco1.py func() |
运行结果:"It's used : 0.002424 ."
6.7 属性装饰器
上节介绍了函数装饰器(decorator),其作用可以给函数动态加上功能。对于类的方法,装饰器一样起作用。Python内置的@property装饰器就是负责把一个方法变成属性调用的。
使用场景:当一个类中,含有一些属性,这些属性不想被直接操作,这时可以考虑属性装饰器,即@property。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
class Exam(object): def __init__(self, score): self._score = score def get_score(self): return self._score def set_score(self, val): if val < 0: self._score = 0 elif val > 100: self._score = 100 else: self._score = val |
不希望对初始化变量直接操作,使用了两个函数;不过这样写,有点麻烦,每次给变量赋值需要采用函数格式。
|
1 2 3 4 |
e = Exam(70) e.get_score() #70 e.set_score(101) e.get_score() #100 |
可以通过在函数前,添加@property,使函数或方法变为属性来操作。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
class Exam(object): def __init__(self, score): self._score = score @property def score(self): return self._score @score.setter def score(self, val): if val < 0: self._score = 0 elif val > 100: self._score = 100 else: self._score = val |
调用函数
|
1 2 3 4 |
e = Exam(90) e.score #90 e.score=110 e.score # 100 |
这样通过在方法前加上@property,就把方法变成了属性,操作属性比操作函数就简单一些,这或许就是属性特征的来由吧。
6.8 内置函数
内置函数可理解为开发语言自带的函数,Java有很多内置函数、MySQL也有很多自带的函数,有效利用这些函数能大大提高我们的开发效率。
Python有哪些内置函数呢?如何使用内置函数法?查看内置函数可用通过以下命令:
|
1 |
print(dir(__builtins__)) |
查看这些内置函数的使用方法,可以用help(内置函数)方法或?内置函数。
|
1 |
map? |
将显示该函数的语法及使用方法等:
Init signature: map(self, /, *args, **kwargs)
Docstring:
map(func, *iterables) --> map object
Make an iterator that computes the function using arguments from
each of the iterables. Stops when the shortest iterable is exhausted.
Type: type
Subclasses:
以下介绍几种常用的内置函数,这些函数后续将大量使用,而且scala中也有类型函数。Hadoop的计算架构为MapReduce,实际上是由Map和Reduce两部分组成的,map和reduce
在Python也类似函数。
1、映射(map)
map(function,seq1,,,)
map()函数接收两个参数,一个是函数,一个是序列,map将传入的函数依次作用到序列的每个元素,并把结果作为新的list返回。函数遍历1个(或多个)序列(或迭代器)的每个元素,映射到另一个列表。
|
1 2 3 4 5 6 7 8 9 10 |
a1=range(0,5) b1=range(5,10) ###处理1个序列 map(lambda x:x**2,a1) ###处理2个序列 map(lambda x,y:x+y,a1,b1) map(None,a1,b1) ##没有函数时,相当于zip(a1,b1) |
2、filter(过滤)
filter(function, seq1)
把函数应用于序列(或迭代器)的每个元素,取出满足函数条件的元素,构成一个新序列,等价于[ item for item in iterable if function(item)]
|
1 2 |
f1=filter(lambda x:x%2==0,b1) print(list(f1)) |
运行结果:
[6, 8]
3、foreach
foreach(function, iterator) ##这个是Python3才有。
foreach的作用是在不改变迭代器中的值的前提下(单纯依靠函数的副作用),将函数应用到迭代器中的各个元素上,主要是用作输出和调试作用,它一般不返回值。
map和foreach类似,都是将一个函数应用到迭代器的所有值中,但map返回一个新的列表作为结果,而foreach不返回值。
4、range([lower,]stop[,step])
xrange 用法与 range 完全相同,所不同的是生成的不是一个list对象,而是一个生成器。要生成很大的数字序列的时候,用xrange会比range性能优很多,因为不需要一上来就开辟一块很大的内存空间,用于大数据迭代时xrange优于range。
注:Python 3系列只有range,它就相当于xrange。
|
1 2 3 4 |
a2=range(0,10,2) #a2是一个生成器,可以通过索引获取,或转换为列表获取 print(list(a2)) print(a2[2]) |
运行结果:
[0, 2, 4, 6, 8]
4
Numpy.random模块也提供了一些用于高效生成多种随机数的函数,如normal可产生一个标准正态分布的样本。
|
1 2 |
import numpy as np np.random.normal(size=(3,2)) |
运行结果:
array([[-2.60662221, 0.41874463],
[ 0.64875586, -0.7013413 ],
[ 2.08334769, -1.41301304]])
6.9 lambda函数
lambda函数又称为匿名函数,使用lambda函数可以返回一个运算结果,其格式如下:
result=lambda[arg1,[arg2,...,]]:express
参数说明
①result就是表示式express的结果。
②关键字lambda是必须的
③参数可以一个,也可多个,多个参数以逗号分隔
④lambda也是函数,是一行函数,参数后需要一个冒号:
⑤express只能有一个表达式,无需return语句,表达式本身的结果就是返回值。
lambda函数非常简洁,它通常作为参数传递给函数,以下是些应用实例。
|
1 2 3 4 5 6 7 8 9 10 11 |
#定义一个Python普通函数 def fun_add(a,b,c): return a+b+c #执行函数 print(fun_add(1,2,3)) #用lambda函数实现fun_add功能 result=lambda a,b,c:a+b+c #执行lambda函数 print(result(1,2,3)) |
可以把lambda函数作为参数传递给其它函数,例如:
|
1 2 3 4 5 |
lst61=["Python","Pytorch","Keras","TensorFlow"] #对列表lst61中的元素,根据元素长度排序 sorted(lst61,key=lambda x:len(x)) #['Keras', 'Python', 'Pytorch', 'TensorFlow'] #对列表lst61中的元素,根据元素中的第二个字符排序 sorted(lst61,key=lambda x:x[1]) #['Keras', 'TensorFlow', 'Python', 'Pytorch'] |
6.10 装饰器
装饰器本质上是一个 Python 函数或类,它可以让其他函数或类在不需要做任何代码修改的前提下增加额外功能,装饰器的返回值也是一个函数/类对象。它经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景,装饰器是解决这类问题的绝佳设计。有了装饰器,我们就可以抽离出大量与函数功能本身无关的雷同代码到装饰器中并继续重用。概括的讲,装饰器的作用就是为已经存在的对象添加额外的功能。
|
1 2 |
def foo(): print('i am foo') |
现在有一个新的需求,希望可以记录下函数的执行日志,于是在代码中添加日志代码:
|
1 2 3 4 |
import logging def foo(): print('i am foo') logging.info("foo is running") |
如果函数 bar()、bar2() 也有类似的需求,怎么做?再写一个 logging 在 bar 函数里?这样就造成大量雷同的代码,为了减少重复写代码,我们可以这样做,重新定义一个新的函数:专门处理日志 ,日志处理完之后再执行真正的业务代码。
|
1 2 3 4 5 6 7 8 |
def use_logging(func): logging.warning("%s is running" % func.__name__) func() def foo(): print('i am foo') use_logging(foo) |
WARNING:root:foo is running
i am foo
这样做逻辑上是没问题的,功能是实现了,但是我们调用的时候不再是调用真正的业务逻辑 foo 函数,而是换成了 use_logging 函数,这就破坏了原有的代码结构, 现在我们不得不每次都要把原来的那个 foo 函数作为参数传递给 use_logging 函数,那么有没有更好的方式的呢?当然有,答案就是装饰器。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def use_logging(func): def wrapper(*args): logging.warning("%s is running" % func.__name__) # 把 foo 当做参数传递进来时,执行func()就相当于执行foo() return func(*args) return wrapper def foo(): print('i am foo') foo = use_logging(foo) # 因为装饰器 use_logging(foo) 返回的时函数对象 wrapper,这条语句相当于 foo = wrapper foo() # 执行foo()就相当于执行 wrapper() |
WARNING:root:foo is running
i am foo
use_logging 就是一个装饰器,它一个普通的函数,它把执行真正业务逻辑的函数 func 包裹在其中,看起来像 foo 被 use_logging 装饰了一样,use_logging 返回的也是一个函数,这个函数的名字叫 wrapper。在这个例子中,函数进入和退出时 ,被称为一个横切面,这种编程方式被称为面向切面的编程。
@ 语法糖
如果你接触 Python 有一段时间了的话,想必你对 @ 符号一定不陌生了,没错 @ 符号就是装饰器的语法糖,它放在函数开始定义的地方,这样就可以省略最后一步再次赋值的操作。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
def use_logging(func): def wrapper(*args): logging.warning("%s is running" % func.__name__) return func(*args) return wrapper @use_logging def foo(): print("i am foo") foo() |
如上所示,有了 @ ,我们就可以省去foo = use_logging(foo)这一句了,直接调用 foo() 即可得到想要的结果。你们看到了没有,foo() 函数不需要做任何修改,只需在定义的地方加上装饰器,调用的时候还是和以前一样,如果我们有其他的类似函数,我们可以继续调用装饰器来修饰函数,而不用重复修改函数或者增加新的封装。这样,我们就提高了程序的可重复利用性,并增加了程序的可读性。
装饰器在 Python 使用如此方便都要归因于 Python 的函数能像普通的对象一样能作为参数传递给其他函数,可以被赋值给其他变量,可以作为返回值,可以被定义在另外一个函数内。
可能有人问,如果我的业务逻辑函数 foo 需要参数怎么办?比如:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def use_logging(func): def wrapper(*args,**kwargs): logging.warning("%s is running" % func.__name__) return func(*args,**kwargs) return wrapper @use_logging def foo(name): print("i am %s" % name) foo(name="apple") |
WARNING:root:foo is running
i am apple
6.11 生成器函数
前面我们介绍了函数的返回值,可以一个或多个。如果返回百万个或更多值时,将消耗很大一部分资源,为解决这一问题,人们想到用生成器。具体方法很简单,就是把函数中return 语句换成yield语句即可,示例如下:
|
1 2 3 4 |
def gen61(n): for i in range(n): yield i #return i |
遍历函数生成器gen61(10)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#遍历函数生成器gen61 #方法1:使用for循环遍历函数生成器 for i in gen61(10): print(i,end=" ") print() #方法2:使用next函数逐个遍历函数生成器 gen=gen61(10) while True: try: #因为不停调用next会报异常,所以要捕捉处理异常。 x = next(gen) #注意这里不能直接写next(gen61(10)),否则每次都是重复调用1 print(x,end=" ") except StopIteration as e: break |
6.12 把函数放在模块中
前面我们介绍了函数及函数参数等,函数定义好之后,我们可以调用,无需重写代码。不过这些函数如果仅停留在开发环境,环境一旦关闭函数也不存在了,那么,如何永久保存定义好的函数?
很简单,只要把这些函数放在模块中即可。所谓模块实际上就是扩展名为.py的文件。
如果当前运行的程序需要使用定义好的函数,只要导入对应的模块即可,导入模块的方式有多种,下面将介绍每种方式。
6.12.1 导入整个模块
假设我们已生成一个模块,模块对应的文件名为:func_op.py,文件存在当前目录下,当前目录可以通过以下命令查看:
|
1 2 3 4 |
#linux环境使用命令 !pwd #windows环境使用命令 system chdir #或者! Chdir |
当然也可放在其它Python能找到的目录(sys.path)下。Python首先查找当前目录,然后查找Python的lib目录、site-packages目录和环境变量PYTHONPATH设置的目录。
(1)创建.py文件
创建.py文件,可以使用pycharm或一般文本编辑器,如NotePad或UE都可。
创建文件后,把该文件放在jupyter notebook当前目录下。
#cat func_op.py具体内容如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
#定义一个函数,累加截止自然数为n,作为参数传给这个函数 def sum_1n(n): """该函数的参数为自然数n,其功能为累加从1到n的n个连续自然数""" #定义一个存放累加数的变量 j=0 #用range(1,n+1)生成1到n连续n个自然数 for i in range(1,n+1): j+=i #把累加结果作为返回值 return j #定义一个函数,接受任意数量的参数 def calc_sum(*lst): """累加所有参数""" sum=0 for i in lst: sum+=i return sum |
(2)导入模块
|
1 |
import func_op |
导入模块,就import 对应的模块名称。导入模块实际上就是让当前程序或会话打开对应的文件,并将文件中的所有函数都复制过来,当然,复制过程都是Python在幕后操作,我们不必关心。
(3)调用函数
导入模块func_op.py后,在jupyter notebook界面,通过模块名.+tab键 就可看到图6-1的内容。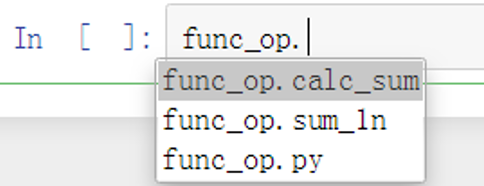
图6-1 查看导入模块中的函数或变量等
调用函数,使用模块名.函数名,中间用句点.
|
1 2 3 4 5 |
#查看函数的帮助信息 func_op.sum_1n.__doc__ #'该函数的参数为自然数n,其功能为累加从1到n的n个连续自然数' #调用函数 func_op.sum_1n(100) #5050 |
6.12.2 导入需要的函数
有时一个模块中有很多函数,其中很多函数暂时用不上或对应程序不需要这些函数,那么我们导入模块时,为节省资源,就可导入需要的函数,不需要的就不导入。导入需要函数的格式为:
|
1 |
from module_name import function_name |
如果需要导入模块中的多个函数,可以用逗号分隔这些函数。
|
1 |
from module_name import function_name1, function_name2 |
这种情况,调用函数时,不需要使用句点,直接使用函数名即可。
|
1 2 3 4 |
#导入需要的函数sum_1n from func_op import sum_1n #调用函数 sum_1n(100) #5050 |
有时函数名比较长,我们可以用取别名的方式,简化函数名称,调用时,直接使用别名就可。
|
1 2 3 4 |
#导入需要的函数sum_1n,并简称为sn from func_op import sum_1n as sn #调用函数 sn(100)#5050 |
6.12.3 导入所有函数
如果模块中函数较多,或我们不想一个个写需要导入的函数,也可导入所有函数。导入所有函数使用如下格式
|
1 |
from module_name import * |
调用函数时也无需使用句点,直接调用函数名即可。示例如下:
|
1 2 3 |
#导入模块中的所有函数 from func_op import * sum_1n(1000) #500500 |
使用这种导入方式简单,但存在一定风险。用这种方式导入的函数或变量将覆盖当前程序或环境已有的函数或变量。所以,一般不建议使用,尤其对导入的模块不熟悉时。比较理想的方法就是按需导入,导入我们需要的函数,或采用句点的方式导入,这样可以更好地避免覆盖函数或变量的风险。
6.12.4 主程序
在编写众多Python程序中,通常至少一个会使用main(),根据不成为文的约定,带有main()函数的程序,被认为是主程序,它是程序运行的起点。主程序可以导入其它模块,然后使用这些模块中的函数、变量等。例如,创建一个名为train_sum.py的主程序,该程序作为执行起点。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import func_op #定义一个主函数 def main(): #输入一个自然数n n=input("输入一个自然数: ") #把字符型转换为整数型 n=int(n) #调用模块func_op中的函数sum_1n result=func_op.sum_1n(n) print("1到{}的连续自然数的和为{}".format(n,result)) ##判断是否以主程序形式运行 if __name__=='__main__': main() |
假设这个主程序放在Jupyter notebook的当前目录,运行该主程序,可以在命令行执行或Jupyter notebook界面执行。具体执行格式如下:
|
1 2 3 4 |
#命令行执行 python train_sum.py #在Jupyter Notebook界面执行 run train_sum.py |
在主程序中,因加了if __name__=='__main__'语句,所以如果导入主程序将不会运行。
其中参数是通过语句input获取,也可以通过命令行运行程序时直接给定。把train_sum.py稍微修改一下。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import func_op import sys def main(): #输入一个自然数n #n=input("输入一个自然数: ") #从命令行获取参数 n=sys.argv[1] #进行数据类型转换 n=int(n) #如果命令行运行:python train_sum.py 100 #则sys.argv[0]是train_sum.py,sys.argv[1]是100 #调用模块func_op中的函数sum_1n result=func_op.sum_1n(n) print("1到{}的连续自然数的和为{}".format(n,result)) ##判断是否以主程序形式运行 if __name__=='__main__': main() |
如果在命令行输入更多参数,或希望得到更强的表现力,可以使用argparse模块,argparse的使用可参考Python官网
6.13 练习
(1)简述形参、实参、位置参数、默认参数、动态参数的区别。
(2)写函数,检查传入列表的长度,如果大于4,那么仅保留前4个长度的内容,并将新内容返回给调用者;否则,返回原列表。
(3)有一个字典dic = {"k1":"ok!","k2":[1,2,3,4],"k3":[10,20]},写函数,遍历字典的每一个value的长度,如果大于2,那么仅仅保留前两个长度的内容,并将返回修改后的字典。