文章目录
第4章 PyTorch数据处理工具箱
在3.5节我们利用PyTorch的torchvision、data等包,下载及预处理MNIST数据集。数据下载和预处理是机器学习、深度学习实际项目中耗时又重要的任务,尤其是数据预处理,关系到数据质量和模型性能,往往要占据项目的大部分时间。好在PyTorch为此提供了专门的数据下载、数据处理包,使用这些包,可极大提高我们的开发效率及数据质量。
本章将介绍以下内容:
简单介绍PyTorch相关的数据处理工具箱
utils.data简介
torchvision简介
TensorBoard简介及实例
4.1 数据处理工具箱概述
通过第3章,读者应该对torchvision、data等数据处理包有了初步的认识,但可能理解还不够深入,接下来我们将详细介绍。PyTorch涉及数据处理(数据装载、数据预处理、数据增强等)主要工具包及相互关系如图4-1所示。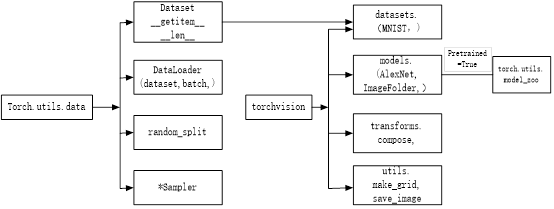
图4-1 PyTorch主要数据处理工具
图4-1 的左边是torch.utils.data工具包,它包括以下4个类:
1) Dataset:是一个抽象类,其他数据集需要继承这个类,并且覆写其中的两个方法(__getitem__、__len__)。
2) DataLoader:定义一个新的迭代器,实现批量(batch)读取,打乱数据(shuffle)并提供并行加速等功能。
3) random_split:把数据集随机拆分为给定长度的非重叠新数据集。
4) *sampler:多种采样函数。
图4-1中间是PyTorch可视化处理工具(torchvision),它是PyTorch的一个视觉处理工具包,独立于PyTorch,需要另外安装,使用pip或conda安装即可:
|
1 2 3 4 5 6 7 |
pip install torchvision #或conda install torchvision 它包括4个类,各类的主要功能如下。 1) 1.datasets:提供常用的数据集加载,设计上都是继承torch.utils.data.Dataset,主要包括MMIST、CIFAR10/100、ImageNet、COCO等。 2) 2.models:提供深度学习中各种经典的网络结构以及训练好的模型(如果选择pretrained=True),包括AlexNet, VGG系列、ResNet系列、Inception系列等。 3) 3.transforms:常用的数据预处理操作,主要包括对Tensor及PIL Image对象的操作。 4) 4.utils:含两个函数,一个是make_grid,它能将多张图像拼接在一个网格中;另一个是save_img,它能将Tensor保存成图像。 |
4.2 utils.data简介
utils.data包括Dataset和DataLoader。torch.utils.data.Dataset为抽象类。自定义数据集需要继承这个类,并实现两个函数,即__len__和__getitem__。前者提供数据的大小(size),后者通过给定索引获取数据和标签或一个样本。 __getitem__一次只能获取一个样本,所以通过torch.utils.data.DataLoader来定义一个新的迭代器,实现batch读取。首先我们来定义一个简单的数据集,然后具体使用Dataset及DataLoader,给读者一个直观的认识。 1)导入需要的模块。
|
1 2 3 |
import torch from torch.utils import data import numpy as np |
2)定义获取数据集的类。
该类继承基类Dataset,自定义一个数据集及对应标签。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
class TestDataset(data.Dataset):#继承Dataset def __init__(self): self.Data=np.asarray([[1,2],[3,4],[2,1],[3,4],[4,5]])#一些由2维向量表示的数据集 self.Label=np.asarray([0,1,0,1,2])#这是数据集对应的标签 def __getitem__(self, index): #把numpy转换为Tensor txt=torch.from_numpy(self.Data[index]) label=torch.tensor(self.Label[index]) return txt,label def __len__(self): return len(self.Data) |
3)获取数据集中数据。
|
1 2 3 4 5 6 7 |
Test=TestDataset() print(Test[2]) #相当于调用__getitem__(2) print(Test.__len__()) #輸出: #(tensor([2, 1]), tensor(0)) #5 |
以上数据以元组格式返回,每次只返回一个样本。实际上,Dateset只负责数据的抽取,一次调用__getitem__只返回一个样本。如果希望批量处理(batch),同时还要进行shuffle和并行加速等操作,可选择DataLoader。DataLoader的格式为:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
data.DataLoader( dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, ) |
主要参数说明如下。
dataset: 加载的数据集。
batch_size: 批大小。
shuffle:是否将数据打乱。
sampler:样本抽样。
num_workers:使用多进程加载的进程数,0代表不使用多进程。
collate_fn:如何将多个样本数据拼接成一个batch,一般使用默认的拼接方式即可。
pin_memory:是否将数据保存在锁页内存(pin memory区,pin memory中的数据转到GPU会快一些。
drop_last:dataset 中的数据个数可能不是 batch_size的整数倍,drop_last为True会将多出来不足一个batch的数据丢弃。
使用函数DataLoader加载数据。
|
1 2 3 4 5 6 |
test_loader = data.DataLoader(Test,batch_size=2,shuffle=False,num_workers=2) for i,traindata in enumerate(test_loader): print('i:',i) Data,Label=traindata print('data:',Data) print('Label:',Label) |
运行结果如下:
i: 0
data: tensor([[1, 2],
[3, 4]])
Label: tensor([0, 1])
i: 1
data: tensor([[2, 1],
[3, 4]])
Label: tensor([0, 1])
i: 2
data: tensor([[4, 5]])
Label: tensor([2])
从这个结果可以看出,这是批量读取。我们可以像使用迭代器一样使用它,如对它进行循环操作。不过它不是迭代器,我们可以通过iter命令转换为迭代器。
|
1 2 |
dataiter=iter(test_loader) imgs,labels=next(dataiter) |
一般用data.Dataset处理同一个目录下的数据。如果数据在不同目录下,不同目录代表不同类别(这种情况比较普遍),使用data.Dataset来处理就不很方便。不过,可以使用PyTorch提供的另一种可视化数据处理工具(即torchvision)就非常方便,不但可以自动获取标签,还提供很多数据预处理、数据增强等转换函数。
4.3 torchvision简介
torchvision有4个功能模块,model、datasets、transforms和utils。其中model后续章节将介绍,利用datasets下载一些经典数据集,3.5小节有实例,读者可以参考一下。本节主要介绍如何使用datasets的ImageFolder处理自定义数据集,如何使用transforms对源数据进行预处理、增强等。下面重点介绍transforms及ImageFolder。
4.3.1 transforms
transforms提供了对PIL Image对象和Tensor对象的常用操作。
1)对PIL Image的常见操作如下。
Scale/Resize: 调整尺寸,长宽比保持不变。
CenterCrop、RandomCrop、RandomSizedCrop:裁剪图像,CenterCrop和RandomCrop在crop时是固定size,RandomResizedCrop则是random size的crop。
Pad: 填充。
ToTensor: 把一个取值范围是[0,255]的PIL.Image 转换成 Tensor。形状为(H,W,C)的numpy.ndarray,转换成形状为[C,H,W],取值范围是[0,1.0]的torch.FloatTensor。
RandomHorizontalFlip:图像随机水平翻转,翻转概率为0.5。
RandomVerticalFlip: 图像随机垂直翻转。
ColorJitter: 修改亮度、对比度和饱和度。
2)对Tensor的常见操作如下。
Normalize: 标准化,即减均值,除以标准差。
ToPILImage:将Tensor转为PIL Image。
如果要对数据集进行多个操作,可通过Compose将这些操作像管道一样拼接起来,类似于nn.Sequential。以下为示例代码。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
transforms.Compose([ #将给定的 PIL.Image 进行中心切割,得到给定的 size, #size 可以是 tuple,(target_height, target_width)。 #size 也可以是一个 Integer,在这种情况下,切出来的图像形状是正方形。 transforms.CenterCrop(10), #切割中心点的位置随机选取 transforms.RandomCrop(20, padding=0), #把一个取值范围是 [0, 255] 的 PIL.Image 或者 shape 为 (H, W, C) 的 numpy.ndarray, #转换为形状为 (C, H, W),取值范围是 [0, 1] 的 torch.FloatTensor transforms.ToTensor(), #规范化到[-1,1] transforms.Normalize(mean = (0.5, 0.5, 0.5), std = (0.5, 0.5, 0.5)) ]) |
还可以自己定义一个python lambda表达式,如将每个像素值加10,可表示为:transforms.Lambda(lambda x: x.add(10))。
更多内容可参考官网,地址为https://pytorch.org/docs/stable/torchvision/transforms.html。
4.3.2 ImageFolder
当文件依据标签处于不同文件下时,如:
─── data
├── zhangliu
│ ├── 001.jpg
│ └── 002.jpg
├── wuhua
│ ├── 001.jpg
│ └── 002.jpg
.................
我们可以利用 torchvision.datasets.ImageFolder 来直接构造出 dataset,代码如下:
|
1 2 |
loader = datasets.ImageFolder(path) loader = data.DataLoader(dataset) |
ImageFolder 会将目录中的文件夹名自动转化成序列,那么DataLoader载入时,标签自动就是整数序列了。
下面我们利用ImageFolder读取不同目录下图像数据,然后使用transorms进行图像预处理,预处理有多个,我们用compose把这些操作拼接在一起。然后使用DataLoader加载。
将处理后的数据用torchvision.utils中的save_image保存为一个png格式文件,然后用Image.open打开该png文件,详细代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
from torchvision import transforms, utils from torchvision import datasets import torch import matplotlib.pyplot as plt %matplotlib inline my_trans=transforms.Compose([ transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(), transforms.ToTensor() ]) train_data = datasets.ImageFolder('../data/torchvision_data', transform=my_trans) train_loader = data.DataLoader(train_data,batch_size=8,shuffle=True,) for i_batch, img in enumerate(train_loader): if i_batch == 0: print(img[1]) fig = plt.figure() grid = utils.make_grid(img[0]) plt.imshow(grid.numpy().transpose((1, 2, 0))) plt.show() utils.save_image(grid,'test01.png') break |
运行结果如下,结果如图4-2所示。
tensor([2, 2, 0, 0, 0, 1, 2, 2])

图4-2 make_grid拼接在一起的图形
打开test01.png文件:
|
1 2 |
from PIL import Image Image.open('test01.png') |
运行结果如图4-3所示。
图4-3 用Image查看png文件
4.4 可视化工具
TensorBoard是Google TensorFlow 的可视化工具,可以记录训练数据、评估数据、网络结构、图像等,并且可以在Web上展示,对于观察神经网路训练的过程非常有帮助。PyTorch支持tensorboard_logger、 visdom等可视化工具。
4.4.1 TensorBoard简介
TensorBoard功能很强大,支持scalar、image、figure、histogram、audio、text、graph、onnx_graph、embedding、pr_curve、videosummaries等可视化方式。
使用TensorBoard的一般步骤如下。
1)导入tensorboard,实例化SummaryWriter类,指明记录日志路径等信息。
|
1 2 3 4 5 6 7 |
from torch.utils.tensorboard import SummaryWriter #实例化SummaryWriter,并指明日志存放路径。在当前目录没有logs目录将自动创建。 writer = SummaryWriter(log_dir='logs') #调用实例 writer.add_xxx() #关闭writer writer.close() |
【说明】
(1)其中logs指生成日志文件路径,如果是在Windows环境下,需要注意其logs路径格式与Linux环境不同,需要使用转义字符或在字符串前加r,如
writer = SummaryWriter(log_dir=r'D:\myboard\test\logs')
(2)SummaryWriter的格式为:
|
1 2 |
SummaryWriter(log_dir=None, comment='', **kwargs) #其中comment在文件命名加上comment后缀 |
(3)如果不写log_dir,系统将在当前目录创建一个runs的目录。
2)调用相应的API接口,接口一般格式为:
|
1 2 |
add_xxx(tag-name, object, iteration-number) #即add_xxx(标签,记录的对象,迭代次数) |
3)启动tensorboard服务。cd到logs目录所在的同级目录,在命令行输入如下命令,logdir等式右边可以是相对路径或绝对路径。
|
1 2 3 |
tensorboard --logdir=logs --port 6006 #如果是windows环境,要注意路径解析,如 #tensorboard --logdir=r'D:\myboard\test\logs' --port 6006 |
4)Web展示。在浏览器输入:
|
1 |
http://服务器IP或名称:6006 #如果是本机,服务器名称可以使用localhost |
便可看到logs目录保存的各种图形,如图4-4所示。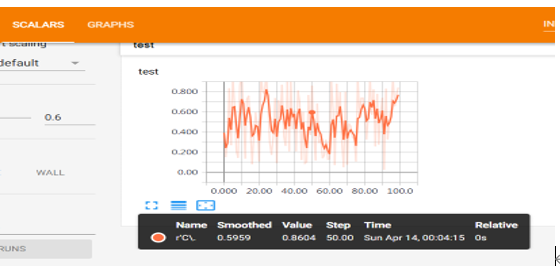
图4-4 TensorBoard示例图形
鼠标在图形上移动,还可以看到对应位置的具体数据。
4.4.2用TensorBoard可视化神经网络
4.4.1节介绍了TensorBoard的主要内容,为帮助大家更好地理解,下面我们将介绍几个实例。实例内容涉及如何使用TensorBoard可视化神经网络模型、可视化损失值、图像等。
1)导入需要的模块。
|
1 2 3 4 5 |
import torch import torch.nn as nn import torch.nn.functional as F import torchvision from torch.utils.tensorboard import SummaryWriter |
2)构建神经网络。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 10, kernel_size=5) self.conv2 = nn.Conv2d(10, 20, kernel_size=5) self.conv2_drop = nn.Dropout2d() self.fc1 = nn.Linear(320, 50) self.fc2 = nn.Linear(50, 10) self.bn = nn.BatchNorm2d(20) def forward(self, x): x = F.max_pool2d(self.conv1(x), 2) x = F.relu(x) + F.relu(-x) x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2)) x = self.bn(x) x = x.view(-1, 320) x = F.relu(self.fc1(x)) x = F.dropout(x, training=self.training) x = self.fc2(x) x = F.softmax(x, dim=1) return x |
3)把模型保存为graph。
|
1 2 3 4 5 6 7 |
#定义输入 input = torch.rand(32, 1, 28, 28) #实例化神经网络 model = Net() #将model保存为graph with SummaryWriter(log_dir='logs',comment='Net') as w: w.add_graph(model, (input, )) |
打开浏览器,便可看到图4-5所示的可视化计算图。
图4-5 TensorBoard可视化计算图
4.4.3用TensorBoard可视化损失值
可视化损失值,使用add_scalar函数,这里利用一层全连接神经网络,训练一元二次函数的参数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
dtype = torch.FloatTensor writer = SummaryWriter(log_dir='logs',comment='Linear') np.random.seed(100) x_train = np.linspace(-1, 1, 100).reshape(100,1) y_train = 3*np.power(x_train, 2) +2+ 0.2*np.random.rand(x_train.size).reshape(100,1) model = nn.Linear(input_size, output_size) criterion = nn.MSELoss() optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) for epoch in range(num_epoches): inputs = torch.from_numpy(x_train).type(dtype) targets = torch.from_numpy(y_train).type(dtype) output = model(inputs) loss = criterion(output, targets) optimizer.zero_grad() loss.backward() optimizer.step() # 保存loss的数据与epoch数值 writer.add_scalar('训练损失值', loss, epoch) |
运行结果如图4-6所示。

图4-6 可视化损失值与迭代步的关系
4.4.4用TensorBoard可视化特征图
利用TensorBoard对特征图进行可视化,不同卷积层的特征图的抽取程度是不一样的。
x从cifair10数据集获取。注意:因PyTorch1.7 utils有一个bug,这里使用了PyTorch1.10版的utils。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
#import torchvision.utils as vutils ##因pytorch1.7 utils有一个bug, ##这里使用了当前最新的utils版本(v1.10) import utils as vutils writer = SummaryWriter(log_dir='logs',comment='feature map') img_grid = vutils.make_grid(x, normalize=True, scale_each=True, nrow=2) net.eval() for name, layer in net._modules.items(): # 为fc层预处理x x = x.view(x.size(0), -1) if "fc" in name else x print(x.size()) x = layer(x) print(f'{name}') # 查看卷积层的特征图 if 'layer' in name or 'conv' in name: x1 = x.transpose(0, 1) # C,B, H, W ---> B,C, H, W img_grid = vutils.make_grid(x1, normalize=True, scale_each=True, nrow=4) # normalize进行归一化处理 writer.add_image(f'{name}_feature_maps', img_grid, global_step=0) |
运行结果如图4-7、图4-8所示。
图4-7 conv1的特征图
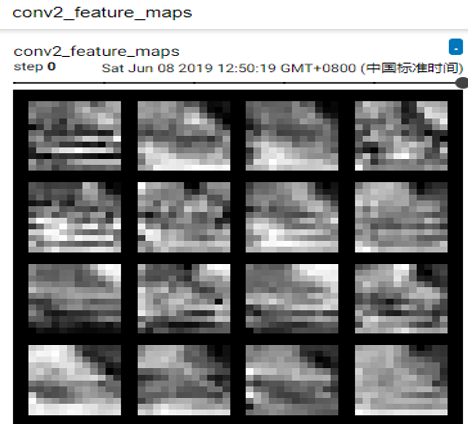
图4-8 conv2的特征图
4.5 小结
本章详细介绍了PyTorch有关数据下载、预处理方面的一些常用包,以及可视化计算结果的TensorBoard工具,并通过一些实例详细说明如何使用这些包或工具。第1-4章介绍了有关NumPy及PyTorch的基础知识,这有助于读者更好理解和使用接下来的深度学习方面的基本概念、原理和算法等内容。