第5章 Spark入门
Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,2014年至2015年,Spark经历了高速发展,Databricks 2015 Spark调查报告显示:2014年9月至2015年9月,已经有超过600个Spark源码贡献者,而在此之前的12个月人数只有315,Spark超越Hadoop,无可争议地成为大数据领域内最活跃的开源项目。除此之外,已经有超过200个公司为Spark奉献过源代码,使Spark社区成为迄今为止开发人员参与最多的社区。
Spark以其先进的设计理念,迅速成为社区的热门项目,围绕着Spark推出了Spark SQL、Spark Streaming、MLLib和GraphX等组件,也就是BDAS(伯克利数据分析栈),这些组件逐渐形成大数据处理一站式解决平台。
Spark使用Scala语言进行实现,它是一种面向对象、函数式编程语言,能够像操作本地集合对象一样轻松地操作分布式数据集(Scala 提供一个称为 Actor 的并行模型,其中Actor通过它的收件箱来发送和接收非同步信息而不是共享数据,该方式被称为:Shared Nothing 模型)。在Spark官网上介绍,它具有运行速度快、易用性好、通用性强和随处运行等特点。
运行速度快
Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算。官方提供的数据表明,如果数据由磁盘读取,速度是Hadoop MapReduce的10倍以上,如果数据从内存中读取,速度可以高达100多倍。

易用性好
Spark不仅支持Scala编写应用程序,而且支持Java和Python等语言进行编写,特别是Scala是一种高效、可拓展的语言,能够用简洁的代码处理较为复杂的处理工作。
通用性强
Spark生态圈包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX等组件,这些组件分别处理Spark Core提供内存计算框架、SparkStreaming的实时处理应用、Spark SQL的即席查询、MLlib或MLbase的机器学习和GraphX的图处理,它们无缝集成于Spark平台。
随处运行
Spark具有很强的适应性,能够读取HDFS、HBase、S3和Techyon等的数据,能够以Mesos、YARN和自身携带的Standalone作为资源管理器调度job,来完成Spark应用程序的计算。
5.1 Spark架构及原理
进入交换式编程界面,在之前的Spark版本中,Spark shell会自动创建一个SparkContext对象sc。2.0中Spark shell则会自动创建一个SparkSession对象(spark),在输入spark时就会发现它已经存在了。下图说明了SparkContext在Spark中的主要功能。
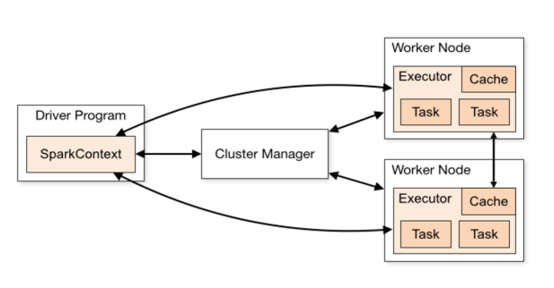
从图中可以看到SparkContext起到的是一个中介的作用,通过它来使用Spark其他的功能。每一个JVM都有一个对应的SparkContext,Driver program通过SparkContext连接到集群管理器来实现对集群中任务的控制。Spark配置参数的设置以及对SQLContext、HiveContext和StreamingContext的控制也要通过SparkContext。不过在Spark2.0中上述的一切功能都是通过SparkSession来完成的,同时SparkSession也简化了DataFrame/Dataset API的使用和对数据的操作。SparkSession成为Spark的一个全新的切入点。
5.2 Spark SQL简介
Spark Sql 的前身是shark,最初是用来查询Hive,Hive是为熟悉数据库,但不熟悉MapReduce的开发人员提供的工具,Hive提供可以对数据进行提取转化和加载(简称ETL)功能,通过Hive工具可以查询分析存储在Hadoop上的大规模数据。Hive定义了简单的查询语言HQL(类SQL),可以把SQL操作转成MapReduce任务。
MapReduce的计算过程消耗大量的IO,降低了运行效率,为了提高查询Hadoop上的数据的效率,出现了很多工具,如Impla 和shark等,其中Shark是spark的生态组件之一,它复用了Hive的SQL解析等组件,修改了内存管理,物理计划、执行模块,使它能够运行在Spark的计算引擎上,使用SQL的查询速度有了10-100倍的提升。
随着shark的发展,shark对Hive的依赖限制了其发展,包括语法解析器和查询优化器。Spark团队汲取了shark的优点重新设计了Spark SQL,使之在数据兼容、性能优化、组件扩展等方面得到极大的提升。
数据兼容:不仅兼容Hive,还可以从RDD、parquet文件、Json文件获取数据、支持从RDBMS获取数据。
性能优化:采用内存列式存储、自定义序列化器等方式提升性能。
组件扩展:SQL的语法解析器、分析器、优化器都可以重新定义和扩展。
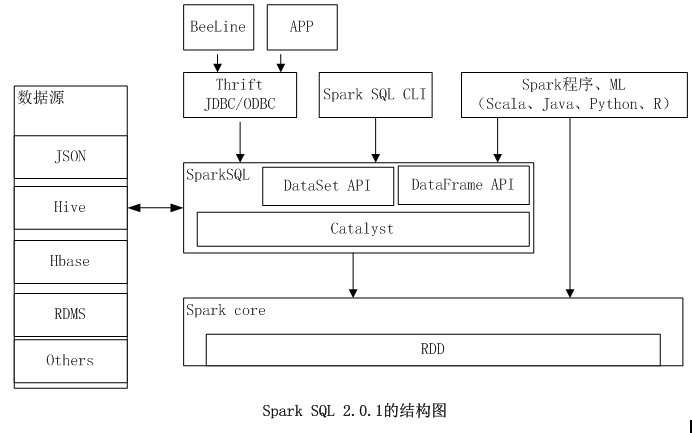
Spark SQL是Spark提供的针对结构化数据处理的模块。不同于基本的Spark RDD API,SparkSQL提供的接口提供了更多的关于数据和计算执行的信息。其数据源可以是文件、Hive表、其他数据库等,我们可以通过command-line或者JDBC/ODBC与SQL接口进行交互。
5.3 Spark SQL操作MySQL
spark-shell --master spark://master:7077 --driver-memory 1G
//连接mysql数据库
scala>val jdbcDF = spark.read.format("jdbc").options(Map("url" ->"jdbc:mysql://192.168.1.106:3306/testdb", "driver" ->"com.mysql.jdbc.Driver", "dbtable" ->"testdb.stud_info", "user" ->"feigu", "password" ->"feigu")).load()
//创建一个视图
scala>jdbcDF.createOrReplaceTempView("stud_info")
scala> val sqlDF=sql("select * from stud_info limit 5")
sqlDF: org.apache.spark.sql.DataFrame = [stud_code: string, stud_name: string ... 8 more fields]
scala> sqlDF.show()
+----------+---------+--------+------+--------+------------+------------+-----+
| stud_code|stud_name|stud_sex| birthday| log_date|orig_addr|lev_date|college_code|college_name|state|
+----------+---------+--------+----------+---+------------+------------+-----+
|2015101000| 王进| M|1997-08-01|2014-09-01| 苏州| null| 10| 理学院| 1
|2015101001| 刘海| M|1997-09-29|2014-09-01| 上海| null| 10| 理学院| 1
|2015101002| 张飞| M|1996-10-21|2014-09-02| 济南| null| 10| 理学院| 1
|2015101003| 刘婷| F|1998-01-10|2014-09-01| 北京| null| 10| 理学院| 1
|2015101004| 卢家| M|1997-08-01|2014-09-01| 南京| null| 10| 理学院| 1
5.4 Spark SQL操作Hive
Spark SQL与Hive的交换,当在Hive上工作时,必须实例化SparkSession对Hive的支持,包括对持久化Hive元存储的连通性,对Hive序列化反序列化,Hive用户自定义函数的支持。当没有在hive-site.xml配置是,context会自动在当前目录创建metastore_db并且创建一个被spark.sql.warehouse.dir配置的目录,默认在spark应用启动的当前目录的spark-warehouse。注意从Spark2.0.0开始hive-site.xml中的hive.metastore.warehouse.dir参数被弃用。作为替代,使用spark.sql.warehouse.dir来指定仓库中数据库的位置。你可能需要授权写权限给启动spark应用的用户。
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
case class Record(key: Int, value: String)
// warehouseLocation points to the default location for managed databases and tables
val warehouseLocation = "spark-warehouse"
val spark = SparkSession
.builder()
.appName("Spark Hive Example")
.config("spark.sql.warehouse.dir", warehouseLocation)
.enableHiveSupport()
.getOrCreate()
import spark.implicits._
import spark.sql
sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
sql("LOAD DATA LOCAL INPATH '/home/hadoop/bigdata/spark/examples/src/main/resources/kv1.txt' INTO TABLE src")
// Queries are expressed in HiveQL
sql("SELECT * FROM src limit 3").show()
// +---+-------+
// |key| value|
// +---+-------+
// |238|val_238|
// | 86| val_86|
// |311|val_311|
// ...
// Aggregation queries are also supported.
sql("SELECT COUNT(*) FROM src").show()
// +--------+
// |count(1)|
// +--------+
// | 500 |
// +--------+
// The results of SQL queries are themselves DataFrames and support all normal functions.
val sqlDF = sql("SELECT key, value FROM src WHERE key < 10 ORDER BY key") // The items in DaraFrames are of type Row, which allows you to access each column by ordinal. val stringsDS = sqlDF.map { case Row(key: Int, value: String) => s"Key: $key, Value: $value"
}
stringsDS.show()
// +--------------------+
// | value|
// +--------------------+
// |Key: 0, Value: val_0|
// |Key: 0, Value: val_0|
// |Key: 0, Value: val_0|
// ...
// You can also use DataFrames to create temporary views within a SparkSession.
val recordsDF = spark.createDataFrame((1 to 100).map(i => Record(i, s"val_$i")))
recordsDF.createOrReplaceTempView("records")
// Queries can then join DataFrame data with data stored in Hive.
sql("SELECT * FROM records r JOIN src s ON r.key = s.key").show()
// +---+------+---+------+
// |key| value|key| value|
// +---+------+---+------+
// | 2| val_2| 2| val_2|
// | 4| val_4| 4| val_4|
// | 5| val_5| 5| val_5|
5.5 pyspark操作hive
以下代码操作hive中表:fund.rpt_fund的数据,fund是数据库名称,rpt_fund是表名。
from pyspark.sql import Row
from pyspark.sql.functions import *
warehouse_location = 'spark-warehouse'
spark = SparkSession \
.builder \
.appName("Python Spark SQL Hive integration example") \
.config("spark.sql.warehouse.dir", warehouse_location) \
.enableHiveSupport() \
.getOrCreate()
df= spark.sql("Select fund_date,nav,accnav from fund.rpt_fund")
df1=df.select(substring(trim(df.fund_date),1,7).alias('year'),df.nav,df.accnav)
df2=df1.groupBy("year").mean("nav","accnav").orderBy("year")
df3=df2.toPandas()
df4=df3.set_index(['year'])
df4.plot(kind='bar',rot=30)
## df4.plot(kind='line',rot=30)
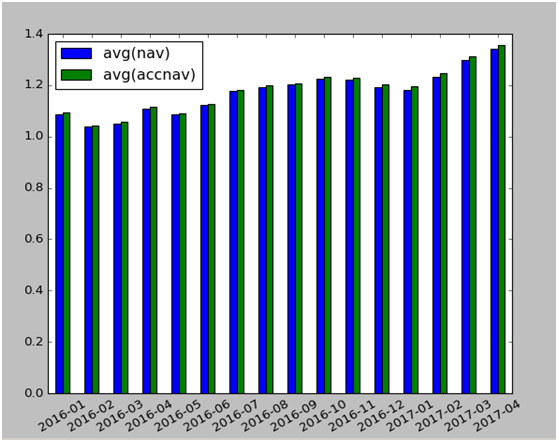
或折线图

5.6练习
一、单选题
1. Spark 的四大组件下面哪个不是
A.Spark Streaming
B Mlib
C Graphx
D Spark R
2.spark 1.4 版本的最大变化
A spark sql Release 版本
B 引入 Spark R
C DataFrame
D支持动态资源分配
3. Spark Job 默认的调度模式
A FIFO B FAIR
C 无 D 运行时指定
4.下面哪个不是 RDD 的特点
A. 可分区 B 可序列化 C 可修改 D 可持久化
5. 关于广播变量,下面哪个是错误的
A 任何函数调用 B 是只读的 C 存储在各个节点 D 存储在磁盘或 HDFS
6. 关于累加器,下面哪个是错误的
A 支持加法 B 支持数值类型
C 可并行 D 不支持自定义类型
7.Spark 支持的分布式部署方式中哪个是错误的
A standalone B spark on mesos
C spark on YARN D Spark on local
8.Stage 的 Task 的数量由什么决定
A Partition B Job C Stage D TaskScheduler
9.下面哪个操作是窄依赖
A join B filter
C group D sort
10.下面哪个操作肯定是宽依赖
A map B flatMap
C reduceByKey D sample
11.spark 的 master 和 worker 通过什么方式进行通信的?
A http B nio C netty D Akka
12.下列哪个不是 RDD 的缓存方法
A persist() B Cache()
C Memory()
13.Task 运行在下来哪里个选项中 Executor 上的工作单元
A Driver program B. spark master
C.worker node D Cluster manager
14.hive 的元数据存储在 derby 和 MySQL 中有什么区别
A.没区别 B.多会话 C.支持网络环境 D数据库的区别
15.DataFrame 和 RDD 最大的区别
A.科学统计支持 B.多了 schema
C.存储方式不一样 D.外部数据源支持
二、实战题
1、利用Spark SQL查询MySQL数据库中stud_score,stud_info表,统计学生各科总成绩,并选出前5名的同学。
附录;推荐读物或网站
一、Linux
1、网站:
Linux中国:https://linux.cn
鸟哥的Linux私房菜: http://linux.vbird.org
Linux下载站: http://www.linuxdown.net
Linux公社: http://www.linuxidc.com
2、图书:
《鸟哥的Linux基础学习篇》鸟哥著
二、MySQL
1、网站:
MySQL社区:http://www.mysqlpub.com/
MySQL菜鸟教程: http://www.runoob.com/mysql/mysql-tutorial.html
MySQL官网:http://www.mysql.com/
2、图书
《深入浅出MySQL》唐汉名等著
三、Python
1、网站:
http://www.pythondoc.com/
2、图书:
基础入门:《python编程入门》Toby Donaldson著
《python基础教程》Magnus Lie Hetland著
数据分析:《利用Python进行数据分析》
机器学习:《机器学习实战》
《Python数据挖掘入门与实践》
《Python机器学习》【美】sebastian Raschka
四、Hadoop
1、hadoop官网:
http://www.apache.org/
2、图书:
《hadoop权威指南》第三版
《Hadoop大数据处理》刘军著
《自己动手做大数据系统》飞谷团队著
五、Spark
1、Spark官网:
http://www.apache.org/
2、图书
《Spark 核心技术与高级应用》于俊等著
《spark机器学习》【南非】Nick Pentreath 著
六.R
1.网站:
http://ggplot2.tidyverse.org/reference/
2. 图书:
《R语言实战》作者: Robert I. Kabacoff 译者: 高涛 / 肖楠 / 陈钢
《ggplot2数据分析与图形艺术》[美] 哈德利•威克姆 著;统计之都 译