文章目录
第3章 ML Pipelines原理与实战
Spark MLlib 是Spark的重要组成部分,也是最早推出库之一, 其基于RDD的API,算法比较丰富,也比较稳定,也比较好用。但是如果目标数据集结构复杂需要多次处理,或者是对新数据需要结合多个已经训练好的单个模型进行综合计算时,使用 MLlib 将会让程序结构复杂,甚至难于理解和实现。为改变这一局限性,从Spark 1.2 版本之后引入的 ML Pipeline,经过多个版本的发展,目前Spark ML功能齐全、性能稳定,Spark ML克服了MLlib在处理复杂机器学习问题的一些不足(如工作比较复杂,流程不清晰等),向用户提供基于DataFrame 之上的更加高层次的 API 库,以更加方便的构建复杂的机器学习工作流式应用,使整个机器学习过程变得更加易用、简洁、规范和高效。Spark的Pipeline与Scikit中Pipeline功能相近、理念相同。本章主要介绍Spark ML中Pipelines的有关内容。
本章主要介绍ML Pipeline相关内容,包括:
Pipeline简介
DataFrame
构成Pipeline的一些组件
介绍pipeline的一般原理
使用pipeline的几个实例
3.1Pipeline简介
3.2DataFrame
以下通过一个实例来说明DataFrame的创建、操作等内容:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
//以一个简单客户文件customer.txt为例,含name,age,gender三列 $cat customer.txt name,age,gender 吴凡,25,F 张海燕,28,F 张宏,30,M 刘婷,29,F 高峰,31,M //创建DataFrame import org.apache.spark.sql.SparkSession import org.apache.spark.sql.DataFrame val spark = SparkSession.builder() .appName("Spark SQL basic example") .config("spark.some.config.option", "some-value") .getOrCreate() //创建DataFrame val df1 = spark.read.option("header", true).format("csv").load("file:///home/hadoop/data/customer.csv") // 转换字符类型 val df2 = df1.select( df1("name").cast("String"), df1("age").cast("Double"), df1("gender").cast("String")) //显示df2的Schema df2.printSchema() root |-- name: string (nullable = true) |-- age: double (nullable = true) |-- gender: string (nullable = true) // 创建视图,后续可以把视图作为表样使用 df2.createOrReplaceTempView("customer") //查询 val cust1 = spark.sql("SELECT * FROM customer WHERE age BETWEEN 30 AND 35") cust1.limit(5).show +----+----+------+ |name| age|gender| +----+----+------+ | 张宏|30.0| M| | 高峰|31.0| M| | 赵建军|32.0| M| | 李俊|32.0| M| | 孙达荣|33.0| M| +----+----+------+ val cust2 = spark.sql("SELECT * FROM customer WHERE gender like 'M'") cust2.limit(5).show +----+----+------+ |name| age|gender| +----+----+------+ | 张宏|30.0| M| | 高峰|31.0| M| | 王华|40.0| M| | 赵建军|32.0| M| | 李俊|32.0| M| +----+----+------+ |
3.3 Pipeline组件
Pipeline组件主要包括Transformer和Estimator。
1. Transformer
2.Estimator
3.4 Pipeline原理
要构建一个Pipeline,首先需要定义Pipeline中的各个Stage,如指标提取和转换模型训练等。有了这些处理特定问题的Transformer和Estimator,我们就可以按照具体的处理逻辑来有序的组织Stages并创建一个Pipeline。
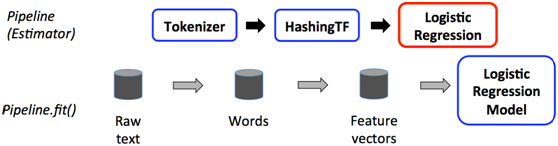
图3-1 pipeline在训练数据上的流程
整个流水线是一个估计器。所以当流水线的fit()方法运行后,会产生一个流水线模型,流水线模型是转换器。流水线模型会在测试时被调用,下面的图示说明用法。

图3-2 pipeline在测试数据上的流程
上面的图示中,流水线模型和原始流水线有同样数目的阶段,然而原始流水线中的估计器此时变为了转换器。当流水线模型的transform()方法被调用于测试数据集时,数据依次经过流水线的各个阶段。每个阶段的transform()方法更新数据集,并将之传到下个阶段。
流水线和流水线模型有助于确认训练数据和测试数据经过同样的特征处理流程。
以上两图如果合并为一图,可用如下图形表达:
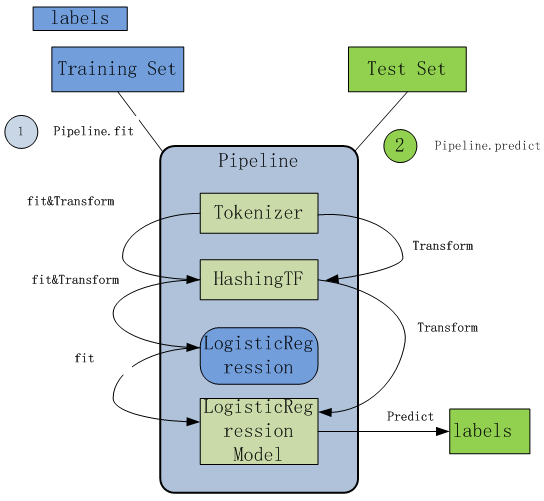
图3-3 Spark pipeline 流程图
其中Pipeline及LogisticRegression都Estimator,Tokenizer,HashingTF,LogisticRegression Model为Transformer。
3.5Pipeline实例
3.5.1使用Estimator, Transformer, and Param实例
机器学习整个过程中,特征转换、特征选择、派生特征等工作,一般需要占据大部分时间,现在ML提供了很多Transformer,如OneHotEncoder、StringIndexer、PCA、Bucketizer、Word2vec等,利用这些函数可极大提高工作效率。
以下通过实例说明如何使用ML库中Estimaor、Transformer和Param等。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
import org.apache.spark.ml.classification.LogisticRegression import org.apache.spark.ml.linalg.{Vector, Vectors} import org.apache.spark.ml.param.ParamMap import org.apache.spark.sql.Row //从(标识、特征)元组开始训练数据. val training = spark.createDataFrame(Seq( (1.0, Vectors.dense(0.0, 1.1, 0.1)), (0.0, Vectors.dense(2.0, 1.0, -1.0)), (0.0, Vectors.dense(2.0, 1.3, 1.0)), (1.0, Vectors.dense(0.0, 1.2, -0.5)) )).toDF("label", "features") //创建一个LogisticRegression实例。 这个实例是一个估计器. val lr = new LogisticRegression() //打印参数,文档和任何默认值. println("LogisticRegression parameters:\n" + lr.explainParams() + "\n") //我们可以使用setter方法来设置参数. lr.setMaxIter(10) .setRegParam(0.01) //训练LogisticRegression模型,这里使用了存储在lr中的参数。. val model1 = lr.fit(training) //由于模型1是模型(即由估计器生成的转换器), //我们可以查看它在fit()中使用的参数。 //打印参数(名称:值)对,其中名称是唯一的ID, // LogisticRegression实例。 println("Model 1 was fit using parameters: " + model1.parent.extractParamMap) //我们可以用ParamMap来指定参数, //它支持几种指定参数的方法。 val paramMap = ParamMap(lr.maxIter -> 20) .put(lr.maxIter, 30) //指定1个参数。 这会覆盖原来的maxIter。 .put(lr.regParam -> 0.1, lr.threshold -> 0.55) // 指定多个参数。 //也可以组合ParamMaps. val paramMap2 = ParamMap(lr.probabilityCol -> "myProbability") // 修改输出列名 val paramMapCombined = paramMap ++ paramMap2 //现在使用paramMapCombined参数学习一个新的模型。 // paramMapCombined覆盖之前通过lr.set *方法设置的所有参数。 val model2 = lr.fit(training, paramMapCombined) println("Model 2 was fit using parameters: " + model2.parent.extractParamMap) // 准备测试数据 val test = spark.createDataFrame(Seq( (1.0, Vectors.dense(-1.0, 1.5, 1.3)), (0.0, Vectors.dense(3.0, 2.0, -0.1)), (1.0, Vectors.dense(0.0, 2.2, -1.5)) )).toDF("label", "features") //使用Transformer.transform()方法对测试数据进行预测 // LogisticRegression.transform将仅使用“特征”列 //请注意,model2.transform()输出一个“myProbability”列,而不是通常的。 // 我们先前通过lr.probabilityCol参数重新命名了'probability'列 model2.transform(test) .select("features", "label", "myProbability", "prediction") .collect() .foreach { case Row(features: Vector, label: Double, prob: Vector, prediction: Double) => println(s"($features, $label) -> prob=$prob, prediction=$prediction") } |
3.5.2ML使用Pipeline实例
使用Pipeline的实例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
import org.apache.spark.ml.{Pipeline, PipelineModel} import org.apache.spark.ml.classification.LogisticRegression import org.apache.spark.ml.feature.{HashingTF, Tokenizer} import org.apache.spark.ml.linalg.Vector import org.apache.spark.sql.Row //准备训练文档,(id,内容,标签) val training = spark.createDataFrame(Seq( (0L, "a b c d e spark", 1.0), (1L, "b d", 0.0), (2L, "spark f g h", 1.0), (3L, "hadoop mapreduce", 0.0) )).toDF("id", "text", "label") //配置ML Pipeline,由三个stage组成,tokenizer, hashingTF, and lr. val tokenizer = new Tokenizer() .setInputCol("text") .setOutputCol("words") val hashingTF = new HashingTF() .setNumFeatures(1000) .setInputCol(tokenizer.getOutputCol) .setOutputCol("features") val lr = new LogisticRegression() .setMaxIter(10) .setRegParam(0.001) val pipeline = new Pipeline() .setStages(Array(tokenizer, hashingTF, lr)) //在训练数据集上使用Pipeline val model = pipeline.fit(training) // Now we can optionally save the fitted pipeline to disk //现在可以保存安装好的流水线到磁盘上 model.write.overwrite().save("/tmp/spark-logistic-regression-model") //现在可以保存未安装好的Pipeline保存到磁盘上 pipeline.write.overwrite().save("/tmp/unfit-lr-model") // 装载模型 val sameModel = PipelineModel.load("/tmp/spark-logistic-regression-model") //准备测试文档,不包含标签(id, text) . val test = spark.createDataFrame(Seq( (4L, "spark i j k"), (5L, "l m n"), (6L, "spark hadoop spark"), (7L, "apache hadoop") )).toDF("id", "text") //在测试文档上做出预测. model.transform(test) .select("id", "text", "probability", "prediction") .collect() .foreach { case Row(id: Long, text: String, prob: Vector, prediction: Double) => println(s"($id, $text) --> prob=$prob, prediction=$prediction") } |
3.6小结
本章主要介绍了流水线(pipeline)的基本概念,流水线的两个组件:Transformer和Estimator,它们是构成Pipeline的Stage,把这些stages按照一定次序组装到Pipeline上,就构成一个流水线,这些stages包括特征转换、特征选择、模型训练等任务,通过几个实例具体说明Pipeline的创建及使用。流水线是一项重要内容,章节还有很多实际使用实例,下一章主要介绍构成Pipeline的一些stages。熟练使用这些Stages有助于提升我们开发效率。
Pingback引用通告: 深度实践Spark机器学习 – 飞谷云人工智能