第1章 Scrapy爬虫基础
1.1 Scrapy运行所依赖的组件
Scrapy框架是一个快速高效地抓取并解析网页内容的爬虫工具。它支持批量方式、多线程获取网页内容,采用简单易用地提取元素规则,并且还支持把抓取结果输出到多种结果集中。
目前最新版本为1.2,本课件中演示使用的版本是0.14。Scrapy可以运行在windows和Linux平台上,且都需要Python支持,可以使用Python 2.7以上版本来运行本课件中的例子。
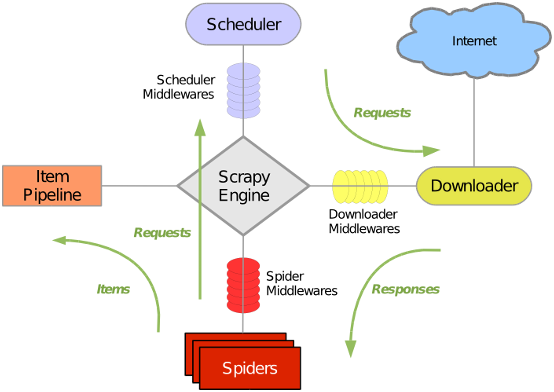
scrapy模块组成图及运行过程
Scrapy在Linux平台上运行需要依赖很多包,以下列出在Ubuntu上安装Scrapy所需要事先安装的包,这些包之间的安装顺序存在依赖关系。
依次安装以下模块:
1. setuptools-0.6c11
2. zope.interface-4.0.1
3. 重新安装Python2.7开发版
4. Twisted-12.1.0
5. w3lib-1.2
6. libxml2和 libxml2-dev
7. libxslt1-dev和libxslt-dev
8. python2.7-mysqldb
9. Scrapy 0.14.4
1.2 手动创建一个Scrapy爬虫项目,并抓取P2P网贷信息
安装Scrapy后,可以通过命令行来测试是否安装成功,如下图:

手动创建并运行一个爬虫项目,通常需要以下几个步骤:
① 创建一个空的scrapy项目
② 定义要抓取的网址,并解析网页中特定标签中的内容
③ 定义item类来规范抓取后的内容
④ 编写pipeline类实现item信息落地
1.3创建一个空的scrapy项目
Scrapy中的爬虫是属于某个项目的。首先可以通过在命令行输入“scrapystartproject”命令来创建一个空的项目。比如现在要创建一个名为mydemo的项目,操作如下:

该命令会在硬盘上创建文件夹mydemo,并自动生成子文件夹mydemo和一些文件,其中mydemo/spiders/目录是用来存放具体爬虫文件的目录。爬虫文件需要用户手动创建,一个目录下可以同时存在多个爬虫文件
1.4 定义要抓取的网址,并解析网页中特定标签中的内容
在mydemo/spiders/下创建Python文件mydemo_page.py,内容如下:
#!/usr/bin/python
fromscrapy.spider import BaseSpider
classMyDemoSpider(BaseSpider):
name = "p2p_page"
start_urls = ["http://www.pingledai.com/td/tz/jkinfo?jkid=364&sh=1"]
def parse(self, response):
print(response.body)
• name属性:用来给爬虫起名字。它也是运行“scrapy crawl”命令时所要提供的参数值。
• start_urls属性:指明了爬虫要抓取的URL地址,类型是字符串数组,可以给爬虫指定一个抓取列表。
• parse方法:是对抓取得到的内容进行解析的方法。参数中的response是抓取后获得的HTML页面内容
创建mydemo_spider.py文件后,我们就可以启动爬虫了。只需要输入命令行
scrapy crawl p2p_page <回车>,就可以看到日志信息,爬虫已经启动,并且最后打印出目标页面对应的HTML源码来。
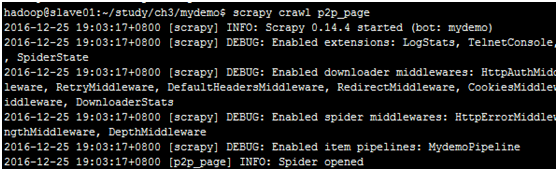
HTML源码中有我们需要的网贷信息,如何提取出这些信息,就需要在parse方法中继续编码了。Scrapy使用一种XPath Selector机制来解析HTML中的数据,它是基于XPath表达式语法的(有关XPath的详细内容,可参见http://www.w3.org/TR/xpath/)。
XPath Selector在Scrapy中内置了两种创建方式,分别是HtmlXPathSelector和XmlPathSelector用来解析Html和Xml代码。在parse方法中可以对HTML利用XPath配合css代码来提取所需的内容。XPath选择器有三个方法:
1. select(xpath): 返回一个相对于当前选中节点的选择器列表(一个XPath可能选到多个节点)
2. extract(): 返回选择器(列表)对应的节点的字符串(列表)
3. re(regex): 返回正则表达式匹配的字符串(分组匹配)列表
parse方法里面使用Xpath方式来逐个解析需要提取出来的要素信息
hxs = HtmlXPathSelector(response)
#标题
title=hxs.select('//span[@id="tzjkcap"]/text()').extract()[0].encode('utf-8')
print(title)
data = hxs.select('//div[@class="pull-left"]/text()').extract()
#借款金额
amount = data[0].encode('utf-8')
print(amount)
#利率
interest = data[1].encode('utf-8')
print(interest)
#借款进度
progress = data[5].encode('utf-8')
progress = progress.replace(' ','')
progress = progress.replace('\n','')
print(progress)
#还款方式
payway = data[6].encode('utf-8')
print(payway)
#期限
term = data[8].encode('utf-8')
print(term)
解析出P2P网贷信息后,同样使用启动爬虫的命令
scrapy crawl p2p_page <回车>,就可以在控制台看到打印出来的内容了。
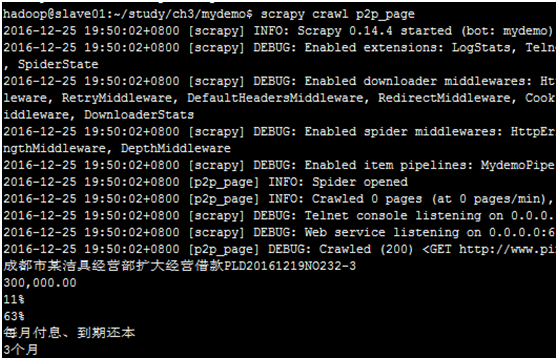
1.5 定义item类来规范抓取后的内容
页面上要抓取的内容,通常是一条完整的记录,譬如一个帖子、一条职位信息或是一条QQ动态。在Scrapy中可使用item类来封装这条记录,item.py文件在spiders的同级目录下。
classMydemoItem(Item):
# define the fields for your item here like:
# name = Field()
pass
Item和Field类都是Scrapy框架提供的。Field类使用Python内置的字典(Python dict)对象,用来存放不同类型的属性值。MydemoItem类继承自Item类,pass空语句代表本程序不执行相应的动作。
在MydemoItem类中定义p2p招标信息的每个属性,类型均为Field类型,并增加一个打印所有属性的方法
fromscrapy.item import Item, Field
classMydemoItem(Item):
# define the fields for your item here like:
# name = Field()
#标题
title=Field()
#期限
term=Field()
#利率
interest=Field()
#还款方式
payway=Field()
#借款金额
amount=Field()
#借款进度
progress=Field()
#打印出所有属性值
defprintProps(self):
#return self['progress']
return "[标题] %s, [期限] %s, [利率] %s, [还款方式] %s, [借款进度] %s, [借款金额] %s " %(self['title'], self['term'], self['interest'], self['payway'], self['progress'], self['amount'])
在spiders/mydemo_page.py中的parse方法里面创建MydemoItem实例,把HTML中抓取的内容赋值给实例中的每个属性。
hxs = HtmlXPathSelector(response)
#标题
title=hxs.select('//span[@id="tzjkcap"]/text()').extract()[0].encode('utf-8')
#print(title)
... ...
... ...
p2pitem = items.MydemoItem()
p2pitem['title'] = title
p2pitem['term'] = term
p2pitem['interest'] = interest
p2pitem['payway'] = payway
p2pitem['amount'] = amount
p2pitem['progress'] = progress
print(p2pitem.printProps())
最后运行scrapy crawl p2p_page命令,查看运行结果
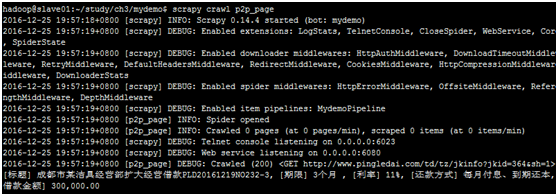
1.6 如何把抓取后信息放入文件中
1. 定义一个管道类来实现抓取内容落地
parse方法返回的MyDemoItem对象,可以在pipelines.py文件的process_item方法中得到继续处理,把MyDemoItem中的属性写入文件。示例代码如下,把抓取下来的p2p网贷信息项写入p2poutput.dat文件中。FilePipelines.py文件可以从pipelines.py复制得到。
importos
classMydemoPipeline(object):
defprocess_item(self, item, spider):
#把解析后的内容放入文件中
fname = "p2poutput.dat"
f_handle = open(fname,'w')
f_handle.write(item.printProps())
f_handle.close()
return item
2. 配置管道类的执行顺序
除了定义FilePipelines文件之外,还需要让scrapy知道有这个文件存在,所以需要在mydemo/settings.py文件中增加配置项,如下红色的代码行,在里面增加“目录名.文件名.类名”这样的配置内容。
BOT_VERSION = '1.0'
SPIDER_MODULES = ['mydemo.spiders']
NEWSPIDER_MODULE = 'mydemo.spiders'
USER_AGENT = '%s/%s' % (BOT_NAME, BOT_VERSION)
ITEM_PIPELINES = {'mydemo.FilePipelines.MydemoPipeline':1}
3. 执行p2p_page爬虫
再次运行scrapy crawl p2p_page命令,查看运行结果。会发现在mydemo目录下多出来一个p2poutput.dat文件,就是管道文件生成的爬取结果文件。
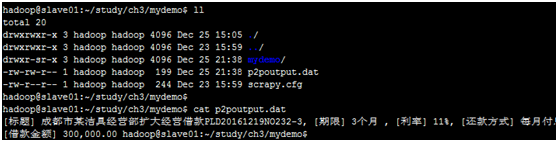
以上完成了一个最基本的爬虫抓取数据的功能,后续课程还会陆续介绍如何把抓取的内容写入到数据库?如何让两个爬虫配合工作及如何抓取图片文件。
第2章 分析京东客户评价数据
Pingback引用通告: Python与人工智能 – 飞谷云人工智能