第4章 Hadoop入门
4.1 Hadoop大数据处理架构
图4-1 Hadoop大数据处理架构图
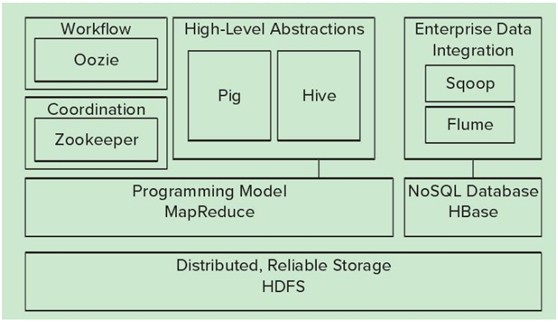
从底部开始,Hadoop生态圈由以下内容组成:
• HDFS—— Hadoop生态圈的基本组成部分是Hadoop分布式文件系统(Hadoop Distributed File System-HDFS)。HDFS是一种数据分布式保存机制,数据被保存在计算机集群上。数据写入一次,读取多次。HDFS为HBase等工具提供了数据基础。
• MapReduce——Hadoop的主要执行框架是MapReduce,它是一个分布式、并行处理的编程模型。MapReduce把任务分为map(映射)阶段和reduce(化简)。开发人员使用存储在HDFS中数据(可实现快速存储),编写Hadoop的MapReduce任务。由于MapReduce工作原理的特性, Hadoop能以并行的方式访问数据,从而实现快速访问数据。
• Hbase——HBase是一个建立在HDFS之上,面向列的NoSQL数据库,用于快速读/写大量数据。HBase使用Zookeeper进行管理,确保所有组件都正常运行。
• Zookeeper ——用于Hadoop的分布式协调服务。Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
• Oozie——Oozie是一个可扩展的工作体系,集成于Hadoop的堆栈,用于协调多个MapReduce作业的执行。它能够管理一个复杂的系统,基于外部事件来执行,外部事件包括数据的定时和数据的出现。
• Pig——它是MapReduce编程的复杂性的抽象。Pig平台包括运行环境和用于分析Hadoop数据集的脚本语言(Pig Latin)。其编译器将Pig Latin翻译成MapReduce程序序列。
• Hive ——Hive类似于SQL高级语言,用于运行存储在Hadoop上的查询语句,Hive让不熟悉MapReduce开发人员也能编写数据查询语句,然后这些语句被翻译为Hadoop上面的MapReduce任务。像Pig一样,Hive作为一个抽象层工具,吸引了很多熟悉SQL而不是Java编程的数据分析师。
Hadoop的生态圈还包括以下几个框架,用来与其它企业融合:
• Sqoop是一个连接工具,用于在关系数据库、数据仓库和Hadoop之间转移数据。Sqoop利用数据库技术描述架构,进行数据的导入/导出;利用MapReduce实现并行化运行和容错技术。
• Flume提供了分布式、可靠、高效的服务,用于收集、汇总大数据,并将单台计算机的大量数据转移到HDFS。它基于一个简单而灵活的架构,并提供了数据流的流。它利用简单的可扩展的数据模型,将企业中多台计算机上的数据转移到Hadoop。
4.2 Hadoop的核心HDFS
图4-2 HDFS架构图
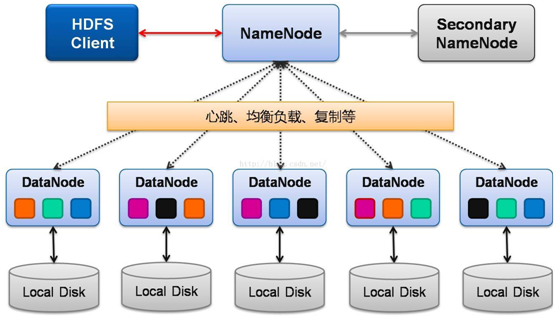
Client:
访问或通过命令行管理HDFS;与NameNode交互,获取文件位置信息;与DataNode交互,读取和写入数据。
NameNode:
Master节点,只有一个,管理HDFS的名称空间和数据块映射信息;配置副本策略;处理客户端请求。
DataNode:
Slave节点,存储实际的数据;执行数据块的读写;汇报存储信息给NameNode。
Secondary NameNode:
辅助NameNode,分担其工作量;定期合并fsimage和fsedits,推送给NameNode;紧急情况下,可辅助恢复NameNode,但Secondary NameNode并非NameNode的热备
4.3 Hadoop的核心MapReduce
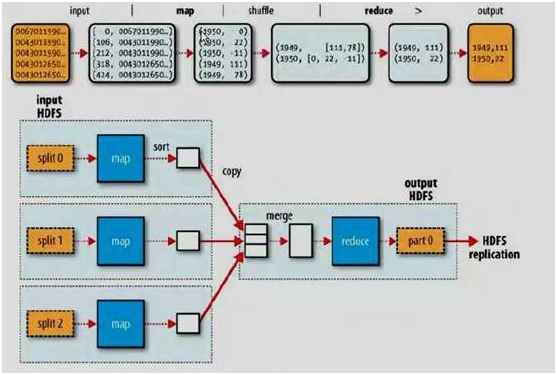
MapReduce是hadoop技术的核心,它提供了一种可以利用底层分布式处理环境进行并行出理的模式,并将处理过程分为两个阶段:Map和Reduce。在map阶段,原始数据通过分片处理输入到mapper进行过滤和转换,生成的中间数据在Reduce阶段作为Reducer的输入,经过reducer的聚合处理,得到输出结果。其处理架构如下:
图4-3 MapReduce处理架构图
4.4 HDFS常用命令
在本节将介绍,如何创建或删除HDFS目录、如何把本地文件传输或复制到HDFS上、如何获取HDFS上的文件等。
HDFS的命令格式为:
hadoop fs -cmd
其中cmd为具体命令,为一系列可变参数,请看如下样例:
查看HDFS上的根目录下的目录或文件:
drwxr-xr-x - hadoop supergroup 0 2017-02-15 21:29 /ch7
drwxr-xr-x - hadoop supergroup 0 2017-02-25 12:31 /exdata
drwxr-xr-x - hadoop supergroup 0 2017-01-11 21:33 /hbase
创建目录
hadoop fs -ls /
drwxr-xr-x - hadoop supergroup 0 2017-02-15 21:29 /ch7
drwxr-xr-x - hadoop supergroup 0 2017-03-26 11:15 /data
hadoop fs -ls /data/tmp
把linux本地文件上传到HDFS
hadoop fs -ls /data/tmp/
-rw-r--r-- 3 hadoop supergroup 34 2017-03-26 11:20 /data/tmp/log.txt
查看HDFS文件内容
sh: 0: Can't open insert_mysql.sh
下载HDFS文件
$ hadoop fs -get /data/tmp/log.txt
删除HDFS文件或空目录
4.5 Hadoop运行实例
下例为Hadoop2.7.2版本MapReudce示例之WordCount
查看测试数据
hadoop spark
hadoop hive
hadoop hbase
hadoop pig
spark sql
spark mllib
spark r
spark streaming
spark graphx
scala java
python c
mysql sql
在HDFS上创建目录
把测试文件上传到HDFS
$ hadoop fs -ls /wordcount/input
-rw-r--r-- 3 hadoop supergroup 138 2017-03-26 15:14 /wordcount/input/wordcount.txt
运行hadoop一个统计单词频度的程序
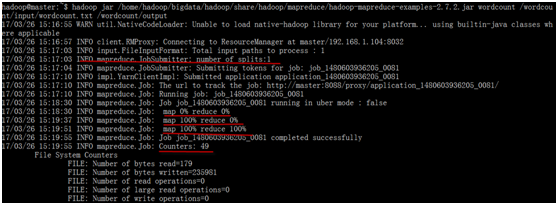
查看运行结果
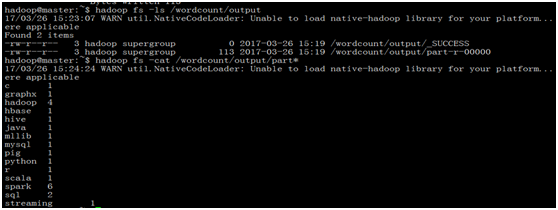
4.6 Hadoop与Hive
Hive是建立在Hadoop之上的数据仓库,由Facebook开发,在某种程度上可以看成是用户编程接口,本身并不存储和处理数据,依赖于HDFS存储数据,依赖MR处理数据。有类SQL语言HiveQL,不完全支持SQL标准,如,不支持更新操作、索引和事务,其子查询和连接操作也存在很多限制。
Hive把HQL语句转换成MR任务后,采用批处理的方式对海量数据进行处理。数据仓库存储的是静态数据,很适合采用MR进行批处理。Hive还提供了一系列对数据进行提取、转换、加载的工具,可以存储、查询和分析存储在HDFS上的数据。
图4-5Hadoop与Hive间的关系:

在4.5节中,我们统计一个文件的字频,使用了一个java现成的包,一般而言,如果需要处理HDFS上文件,需要使用java开发一个相关应用MapReduce来实现;不过有不少任务,我们不一定要使用Java来实现,除了Java,我们还可以使用HQL,尤其对对Java不熟悉的人来说,将带来不少便利,同时,在一定程度上,也大大降处理基于HDFS上文件的门槛,下例是以HQL实现以上需求的一个示例。
###首先在hive中创建1表,然后,把数据导入该表
hive> show databases;
OK
default
feigu
sqoop
stg_db
Time taken: 2.72 seconds, Fetched: 4 row(s)
hive> use feigu; ###使用feigu库
###在feigu库中创建表:wordcount
hive>CREATE TABLE wordcount (a1 string ,a2 string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' LINES TERMINATED BY '\n' ;
##导入数据
hive> load data local inpath '/home/hadoop/wordcount.txt' overwrite into table wordcount;
创建一个视图,把两个字段值,放在一列,考虑到有重复值,采用union all
###统计字频
hive> select b1,count(*) from v_wordcount group by b1;
Query ID = hadoop_20170329111745_5f3e13ce-3c76-48c2-933e-14c9936827a2
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
Starting Job = job_1480603936205_0084, Tracking URL = http://master:8088/proxy/application_1480603936205_0084/
Kill Command = /home/hadoop/bigdata/hadoop/bin/hadoop job -kill job_1480603936205_0084
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2017-03-29 11:18:15,343 Stage-1 map = 0%, reduce = 0%
2017-03-29 11:18:28,879 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.03 sec
2017-03-29 11:18:44,870 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.75 sec
MapReduce Total cumulative CPU time: 4 seconds 750 msec
Ended Job = job_1480603936205_0084
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.75 sec HDFS Read: 8223 HDFS Write: 113 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 750 msec
OK
c 1
graphx 1
hadoop 4
hbase 1
hive 1
java 1
mllib 1
mysql 1
pig 1
python 1
r 1
scala 1
spark 6
sql 2
streaming 1
Time taken: 62.681 seconds, Fetched: 15 row(s)
hive>
4.7练习
一、单选题
1. 下面哪个程序负责HDFS数据存储。
a) NameNode b) Jobtracker
c) Datanode
d) secondaryNameNode e) tasktracker
2. HDfS中的block默认保存几份?
a) 3份 b) 2份 c) 1份 d) 不确定
3. 下列哪个程序通常与NameNode在一个节点启动?
a) SecondaryNameNode b) DataNode c) TaskTracker d) Jobtracker
4. HDFS默认Block Size
a) 32MB b) 64MB c) 128MB
5. 下列哪项通常是集群的最主要的性能瓶颈
a) CPU b) 网络 c) 磁盘 d) 内存
二、创建一个文件,然后把该文件复制到HDFS上,然后查看该文件内容。