Theano是Python的一个库,为开源项目,在2008年,由Yoshua Bengio领导的加拿大蒙特利尔理工学院LISA实验室开发。对于解决大量数据的问题,使用Theano可能获得与手工用C实现差不多的性能。另外通过利用GPU,它能获得比CPU上的快很多数量级的性能。
Theano把计算机代数系统(CAS)和优化的编译器结合在一起。 它也可以对许多数学操作生成自定义的C代码。这种CAS和优化编译的组合对于有复杂数学表达式重复的被求值并且求值速度很关键的问题是非常有用的。对于许多不同的表达式只求值一次的场景,Theano也能最小化编译/分析的次数,但是仍然可以提供诸如自动差分这样的符号计算的特性。
Theano主要特点:
第一个特点:
使用“符号计算图”来描述模型表达式的开源架构,当前很多优秀的开源工具库或深度学习框架,如TensorFlow、Keras等,都借鉴了Theano的设计风格及其底层设计,因此,了解Theano的特点,尤其是符合图的机制对我们学好其它开源工具非常有帮助。
第二个特点:Theano针对多维数组(或张量),能够高效实现、编译和评估数学表达式,它同时还可以使得代码在GPU上执行。它没有专门提供深度学习相关的API,因此,用户构建模型时需要从最基本的网络层开始构建。
1、符号变量
Theano的变量类型称为符号变量,用TensorVariable表示,又称为张量,它是Theano表达式和运算操作的基本单位。创建符号变量的方式有如下几种:
使用内置的变量类型创建
目前Theano支持7种内置的变量类型,分别是标量(scalar)、向量(vector)、行(row)、列(col)、矩阵(matrix)、tensor3、tensor4等。其中标量是0阶张量,向量为1阶张量,矩阵为二阶张量等,以下为创建内置变量的实例:
from theano import tensor as T
data=T.vector(name='data',dtype='float64')
其中,
name指定变量名字
dtype指变量的数据类型。
以下我们通过Theano的tensor模块中scalar来计算一维数据样本点x的输入z,权重假设为w,偏移量为b,即它们间的关系为:
z=w*x+b
实现这个表达式的代码如下:
from theano import tensor as T
#初始化
x=T.scalar()
w=T.scalar()
b=T.scalar()
z=w*x+b
#编译
net_input=theano.function(inputs=[w,x,b],outputs=z)
#执行
print('net input: %.2f' %net_input(3.0,2.0,0.1))
运算结果为:net input: 6.10
自定义变量类型
内置的变量类型只能处理4维及以下的变量,如果需要处理更高维的数据时,我们可以使用Theano的自定义变量类型,具体通过TensorType方法来实现:
from theano import tensor as T
mytype=T.TensorType('float64',broadcastable=(),name=None,sparse_grad=False)
其中broadcastable是True或False的布尔类型元组,元组的大小等于变量的维度,如果为True,表示变量在对应维度上的数据可以进行广播,否则数据不能广播。
广播机制(broadcast)是一种重要机制,有了这种机制,就可以方便对不同维的张量进行运算,否则,就要手工把低维数据变成高维,利用广播机制系统自动利用复制等方法把低维数据补齐,numpy也有这种机制。以下我们通过一个实例来说明广播机制原理:
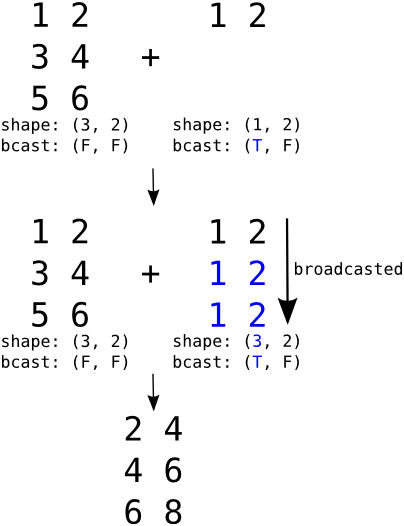
上图矩阵与向量相加的具体代码如下:
import numpy as np
import theano.tensor as T
r = T.row()
r.broadcastable
# (True, False)
mtr = T.matrix()
mtr.broadcastable
# (False, False)
f_row = theano.function([r, mtr], [r + mtr])
R = np.arange(1,3).reshape(1,2)
R
#array([[1, 2]])
M = numpy.arange(1,7).reshape(3, 2)
M
#array([[1, 2],
# [3, 4],
# [5, 6]])
f_row(R, M)
#[array([[ 2., 4.],
# [ 4., 6.],
# [ 6., 8.]])]
将Python类型变量或者Numpy类型变量转化为Theano共享变量
共享变量是Theano实现变量更新的重要机制,后面我们会详细讲解。要创建一个共享变量,只要把一个Python对象或Numpy对象传递给shared函数即可。
import numpy as np
import theano.tensor as T
data=np.array([[1,2],[3,4]])
shared_data=theano.shared(data)
type(shared_data)
2.符号计算图模型
要定义一个符号表达式,首先创建表达式所需的变量,然后通过操作符(op)把这些变量结合在一起。
Theano处理符号表达式时通过把符号表达式转换为一个计算图(graph)来处理(TensorFlow也使用了这种方法,等到我们介绍TensorFlow时,大家可对比一下),符号计算图的节点有:variable、type、apply和op
variable节点:即符号的变量节点,符号变量是符号表达式存放信息的数据结构,可以分为输入符号和输出符号。
type节点:当定义了一种具体的变量类型以及变量的数据类型时,Theano为其指定数据存储的限制条件。
apply节点:把某一种类型的符号操作符应用到具体的符号变量中,与variable不同,apply节点无须由用户指定,一个apply节点包括3个字段:op、inputs、outputs。
op节点:即操作符节点,定义了一种符号变量间的运算,如+、-、sum()、tanh()等。
Theano是将符号表达式的计算表示成graphs。这些graphs是由将Apply 和 Variable节点内连接而组成的,它们是分别与函数的应用和数据相连接的。 操作是由 Op 实例表示,而数据类型是由 Type 实例表示。下面有一段代码和一个图表,该图表用来说明由这些代码所构建的结构。借助这个图或许有助于您理解如何将这些片拟合到一起:
import numpy as np
import theano.tensor as T
x = T.dmatrix('x')
y = T.dmatrix('y')
z = x + y
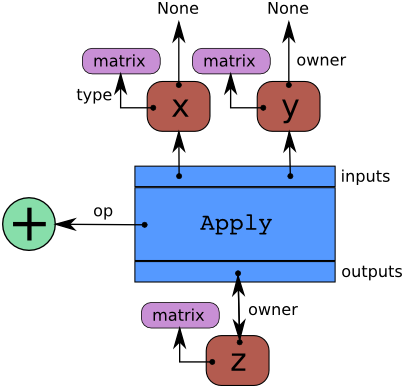
图中箭头表示指向python对象的引用。这里的蓝色盒子是一个 Apply 节点。红色盒子是 Variable 节点。绿色圆圈是Ops。紫色盒子是 Types。
在创建 Variables 之后,对它们应用 Apply Ops 从而得到更多的变量,并得到一个二分、有向、无环图。变量指向 Apply 节点的过程是用来表示函数通过它们的owner 域来生成它们 。这些Apply节点是通过它们的inputs和outputs域来得到它们的输入和输出变量的。
x 和 y 的owner 域的指向都是None是因为它们不是另一个计算的结果。如果它们中的一个是另一个计算的结果,那么owner域将会指向另一个的蓝色盒。
3.函数
函数是Theano的一个核心设计模块,我们了解了Theano如何把一个符号表达式转化为符号计算图,函数的功能则是提供一个接口,把函数计算图编译为可调用的函数对象。
3.1 Theano的编程风格
在theano中,我们一般是先声明自变量x(不需要赋值),然后编写函数方程结束后;最后在为自变量赋值,计算出函数的输出值y。如下示例:
#声明一个int类型的变量x
x=theano.tensor.iscalar('x')
#定义y=x^3
y=theano.tensor.pow(x,3)
#定义函数的自变量为x(输入),因变量为y(输出)
f=theano.function([x],y)
#计算当x=2的时候,函数f(x)的值
print (f(2))
#计算当x=4时,函数f(x)=x^3的值
print (f(4))
8
64
一旦我们定义了f(x)=x^3,这个时候,我们就可以输入我们想要的x值,然后计算出x的三次方。
3.2 函数的定义
Theano函数定义语法为:
theano.function(inputs, outputs, mode=None, updates=None, givens=None, no_default_updates=False, accept_inplace=False, name=None,rebuild_strict=True, allow_input_downcast=None, profile=None, on_unused_input='raise')。
参数看起来很多,但常用的一般只用到三个,inputs表示自变量、outputs表示函数的因变量(也就是函数的返回值),还有另外一个比较常用的是updates这个参数,这个一般用于神经网络共享变量参数更新,通常以字典或元组列表的形式指定;givens是一个字典或元组列表,记为[(var1,var2)],表示在每一次函数调用时,在符号计算图中,把符号变量var1节点替换为var2节点,该参数常用来指定训练数据集的batch大小。
我们看一个有多个自变量、同时又有多个因变量的函数定义例子:
x, y =theano.tensor.fscalars('x', 'y')
z1= x + y
z2=x*y
f =theano.function([x,y],[z1,z2])#定义x、y为自变量,z1、z2为函数返回值(因变量)
print(f(2,3))#返回当x=2,y=3的时候,函数f的因变量z1,z2的值
[array(5.0, dtype=float32), array(6.0, dtype=float32)]
3.3 重要函数
Theano有个很好用的函数,就是求函数的偏导数theano.grad(),比如下面S函数:

我们要求当x=3的时候,s函数的导数,代码如下:
x =theano.tensor.fscalar('x')#定义一个float类型的变量x
y= 1 / (1 + theano.tensor.exp(-x))#定义变量y
dx=theano.grad(y,x)#偏导数函数
f= theano.function([x],dx)#定义函数f,输入为x,输出为s函数的偏导数
print(f(3))#计算当x=3的时候,函数y的偏导数
0.045176658779382706
3.4 更新共享变量参数
在theano.function函数中,有个非常重要的参数updates,updates是一个包含两个元素的列表或tuple,updates=[old_w,new_w],当函数被调用的时候,这个会用new_w替换old_w,具体看下面这个例子
w= theano.shared(1)#定义一个共享变量w,其初始值为1
x=theano.tensor.iscalar('x')
f=theano.function([x], w, updates=[[w, w+x]])#定义函数自变量为x,因变量为w,当函数执行完毕后,更新参数w=w+x
print(f(3))#函数输出为w
print(w.get_value())#这个时候可以看到w=w+x为4
1
4
在求梯度下降的时候,经常用到updates这个参数。比如updates=[w,w-α*(dT/dw)],其中dT/dw就是我们梯度下降的时候,损失函数对参数w的偏导数,α是学习率。为便于大家的更全面的了解Theano函数一些使用,下面我们通过一个逻辑回归的完整实例来说明:
import theano
import theano.tensor as T
rng = np.random
# 我们为了测试,自己生成10个样本,每个样本是3维的向量,然后用于训练
N = 10
feats = 3
D = (rng.randn(N, feats).astype(np.float32), rng.randint(size=N, low=0, high=2).astype(np.float32))
# 声明自变量x、以及每个样本对应的标签y(训练标签)
x = T.matrix("x")
y = T.vector("y")
#随机初始化参数w、b=0,为共享变量
w = theano.shared(rng.randn(feats), name="w")
b = theano.shared(0., name="b")
#构造损失函数
p_1 = 1 / (1 + T.exp(-T.dot(x, w) - b)) # s激活函数
xent = -y * T.log(p_1) - (1-y) * T.log(1-p_1) # 交叉商损失函数
cost = xent.mean() + 0.01 * (w ** 2).sum()# 损失函数的平均值+L2正则项以防过拟合,其中权重衰减系数为0.01
gw, gb = T.grad(cost, [w, b]) #对总损失函数求参数的偏导数
prediction = p_1 > 0.5 # 大于0.5预测值为1,否则为0.
train = theano.function(inputs=[x,y],outputs=[prediction, xent],updates=((w, w - 0.1 * gw), (b, b - 0.1 * gb)))#训练所需函数
predict = theano.function(inputs=[x], outputs=prediction)#测试阶段函数
#训练
training_steps = 1000
for i in range(training_steps):
pred, err = train(D[0], D[1])
print (err.mean())#查看损失函数下降变化过程
4、共享变量
共享变量是实现机器学习算法参数更新的重要机制。对于一般的符号变量,没有赋予初始值。在编写深度学习程序时,需要对权重参数进行初始化,此时需要带有初始值的符号变量,这种带有初始值的符号变量称为共享变量,共享变量的初始值由Numpy数据指定。
创建共享变量有两种模型:深拷贝和浅拷贝。深拷贝复制Numpy数组,浅拷贝只是复制Numpy的指针,后续对Numpy的修改将影响浅拷贝的共享变量值。这两种模式通过borrow参数来设置,默认borrow=False(即深拷贝),下面我们通过一个实例来说明:
import theano
np_array=np.ones(2,dtype='float32')
s_default=theano.shared(np_array)
s_f=theano.shared(np_array,borrow=False)
s_t=theano.shared(np_array,borrow=True)
np_array的值为:array([ 1., 1.], dtype=float32)
下面我们修改np_array的值,查看对不同模式的共享变量影响。
np_array
# array([ 3., 3.], dtype=float32)
s_default.get_value()
# array([ 1., 1.], dtype=float32)
s_f. get_value()
# array([ 1., 1.], dtype=float32)
s_t. get_value()
# array([ 3., 3.], dtype=float32)
通过以上代码运行结果可以看到,修改numpy的np_array值,对深拷贝的共享变量s_default,s_f变量没有影响,对s_t共享变量有影响。
5、配置Theano
现在maeOS、Linux或windows,大都使用64位内存寻址方式。Numpy和Theano默认情况下,也都使用双精度浮点格式(float64),但是,如果想要使用GPU加速计算,一般依赖32位的内存寻址方式,这是目前Theano唯一支持的计算框架。CPU在32位和64位都可以。
修改Theano的配置,可以通过以下两种方法,优先级从高到底:
(1)通过设置THEANO_FLAGS环境变量;
(2)通过.theanorc文件来设置。
5.1通过THEANO_FLAGS配置
通过设置THEANO_FLAGS环境变量来修改Theano的配置,这种方式可以是全局的,也可以是针对某个脚本文件。THEANO_FLAGS以字符串的形式显示,字符串以逗号分隔,如下所示:
THEANO_FLAGS='floatX=float32,device=gpu0'
具体修改可以直接修改环境变量或在命令行下修改或在脚本中修改。在脚本中修改时,需要在导入theano之前修改,否则可能导致修改无效。如下示例:
os.environ["THEANO_FLAGS"]= 'floatX=float32,device=cpu'
import theano
print(theano.config.floatX)
float64
5.2通过.theanorc文件配置
.theanorc文件一般在$HOME目录下,编辑这个文件添加如下内容即可:
device=cpu
floatX=float64