文章目录
- 第14章TensorFlowOnSpark详解
- 14.1TensorFlow简介
- 14.1.1TensorFlow的安装
- 14.1.2TensorFlow的发展
- 14.1.3TensorFlow的特点
- 14.1.4TensorFlow编程模型
- 14.1.5TensorFlow常用函数
- 14.1.6TensorFlow的运行原理
- 14.2TensorFlow实现卷积神经网络
- 14.2.1卷积神经网络简介
- 14.2.3卷积神经网络的网络结构
- 14.2.4.1 导入数据
- 14.2.4.2 权重初始化
- 14.2.4.3 构建卷积神经网络结构
- 14.2.4.4 训练评估模型
- 14.3TensorFlow实现循环神经网络
- 14.3.1循环神经网络简介
- 14.3.2LSTM循环神经网络简介
- 14.3.4TensorFlow实现循环神经网络
- 14.4分布式TensorFlow
- 14.4.1客户端、主节点和工作节点间的关系
- 14.4.2分布式模式
- 14.4.3在Pyspark集群环境运行TensorFlow
- 14.5TensorFlowOnSpark架构
- 14.6TensorFlowOnSpark安装
- 14.7TensorFlowOnSpark实例
- 14.7.1TensorFlowOnSpark单机模式实例
- 14.7.2TensorFlowOnSpark集群模式实例
- 14.8小结
第14章TensorFlowOnSpark详解
前面我们介绍了Spark MLlib的多种机器学习算法,如分类、回归、聚类、推荐等,Spark目前还缺乏对神经网络、深度学习的足够支持,但近几年市场对神经网络,尤其对深度学习热情高涨,成了当下很多企业的研究热点,缺失神经网络的支持,这或许也算是Spark MLlib尚欠不足之处吧。
不过好消息是TensorFlow这个深度学习框架,已经有了Spark接口,即TensorFlowOnSpark。TensorFlow是目前很热门的深度学习框架,是Google于2015年11月9日开源的第二代深度学习系统,也是AlphaGo的基础程序。
本章我们将介绍深度学习最好框架TensorFlow及TensorFlowOnSpark,具体包括:
TensorFlow简介
TensorFlow实现卷积神经网络
分布式TensorFlow
TensorFlowOnSpark架构
TensorFlowOnSpark实例
14.1TensorFlow简介
14.1.1TensorFlow的安装
安装TensorFlow,因本环境的python2.7采用anaconda来安装,故这里采用conda管理工具来安装TensorFlow,目前conda缺省安装版本为TensorFlow 1.1。
|
1 |
conda install tensorflow |
验证安装是否成功,可以通过导入tensorflow来检验。
启动ipython(或python)
|
1 |
import tensorflow as tf |
14.1.2TensorFlow的发展
2015年11月9日谷歌开源了人工智能系统TensorFlow,同时成为2015年最受关注的开源项目之一。TensorFlow的开源大大降低了深度学习在各个行业中的应用难度。TensorFlow的近期里程碑事件主要有:
2016年04月:发布了分布式TensorFlow的0.8版本,把DeepMind模型迁移到TensorFlow;
2016年06月:TensorFlow v0.9发布,改进了移动设备的支持;
2016年11月:TensorFlow开源一周年;
2017年2月:TensorFlow v1.0发布,增加了Java、Go的API,以及专用的编译器和调试工具,同时TensorFlow 1.0引入了一个高级API,包含tf.layers,tf.metrics和tf.losses模块。还宣布增了一个新的tf.keras模块,它与另一个流行的高级神经网络库Keras完全兼容。
2017年4月:TensorFlow v1.1发布,为 Windows 添加 Java API 支,添加 tf.spectral 模块, Keras 2 API等;
2017年6月:TensorFlow v1.2发布,包括 API 的重要变化、contrib API的变化和Bug 修复及其他改变等。
14.1.3TensorFlow的特点
14.1.4TensorFlow编程模型
TensorFlow如何工作?我们通过一个简单的实例进行说明,为计算x+y,你需要创建下图(图14-1)这张数据流图:
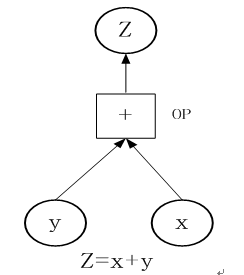
图14-1计算x+y的数据流图
以下构成上数据流图(图14-1)的详细步骤:
1)定义x= [1,3,5],y =[2,4,7],这个图和tf.Tensor一起工作来代表数据的单位,你需要创建恒定的张量:
|
1 2 3 |
import tensorflow as tf x = tf.constant([1,3,5]) y = tf.constant([2,4,7]) |
2)定义操作
|
1 |
op = tf.add(x,y) |
3)张量和操作都有了,接下来就是创建图
|
1 |
my_graph = tf.Graph() |
注意:这一步不是必须的,在创建回话时,系统将自动创建一个默认图。
4)为了运行这图你将需要创建一个回话(tf.Session),一个tf.Session对象封装了操作对象执行的环境,为了做到这一点,我们需要定义在会话中将要用到哪一张图:
|
1 2 3 4 |
with tf.Session(graph=my_graph) as sess: x = tf.constant([1,3,5]) y = tf.constant([2,4,7]) op = tf.add(x,y) |
5)想要执行这个操作,要用到tf.Session.run()这个方法:
|
1 2 3 4 5 6 7 8 |
import tensorflow as tf my_graph = tf.Graph() with tf.Session(graph=my_graph) as sess: x = tf.constant([1,3,5]) y = tf.constant([2,4,7]) op = tf.add(x,y) result = sess.run(fetches=op) print(result) |
6)运行结果:
[ 3 7 12]
14.1.5TensorFlow常用函数
14.1.6TensorFlow的运行原理
TensorFlow有一个重要组件client,即客户端,此外,还有master、worker,这些有点类似Spark的结构。它通过Session的接口与master及多个worker相连,其中每一个worker可以与多个硬件设备(device)相连,比如CPU或GPU,并负责管理这些硬件。而master则负责管理所有worker按流程执行计算图。
14.2TensorFlow实现卷积神经网络
神经网络可为机器学习中最活跃的领域之一,尤其代表深度学习的卷积神经(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)更是炙手可热。
14.2.1卷积神经网络简介
卷积神经网络是人工神经网络的一种,已成为图像识别、视频处理、语音分析等领域的研究热点。它的权值共享网络结构使之更类似于生物神经网络,减少了权值的数量,降低了网络模型的复杂度,防止因参数太多导致过拟合。
14.2.3卷积神经网络的网络结构
接下来,我们利用训练集训练卷积神经网络模型,然后在测试集上验证该模型。
搭建的卷积神经网络使用的一些参数是:
卷积层1:kernel_size [5, 5], stride=1,32个卷积窗口
池化层1: pool_size [2, 2], stride = 2
卷积层2:kernel_size [5, 5], stride=1,64个卷积窗口
池化层2: pool_size [2, 2], stride = 2
全连接层: 1024个特征,使用dropout减少过拟合
输出层: 使用softmax进行分类
14.2.4.1 导入数据
首先启动ipython,进入交互计算环境,当然直接启动python也可,然后通过TensorFlow自带的函数读取图片数据。
|
1 2 3 4 |
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) ~/anaconda2/lib/python2.7/site-packages/tensorflow/contrib/learn/python/learn/datasets/mnist.py 中函数read_data_sets四个local_file |
如果无法直接通过input_data下载,可以先把MNIST数据下载,然后,修改
python/learn/datasets/mnist.py文件中read_data_sets函数中4个local_file的值
具体如下,注释原来的local_file,新增4行local_file
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#local_file = base.maybe_download(TRAIN_IMAGES, train_dir,SOURCE_URL + TRAIN_IMAGES) local_file = train_dir + "/" + TRAIN_IMAGES with open(local_file, 'rb') as f: train_images = extract_images(f) #local_file = base.maybe_download(TRAIN_LABELS, train_dir,SOURCE_URL + TRAIN_LABELS) local_file = train_dir + "/" + TRAIN_LABELS with open(local_file, 'rb') as f: train_labels = extract_labels(f, one_hot=one_hot) #local_file = base.maybe_download(TEST_IMAGES, train_dir,SOURCE_URL + TEST_IMAGES) local_file = train_dir + "/" + TEST_IMAGES with open(local_file, 'rb') as f: test_images = extract_images(f) #local_file = base.maybe_download(TEST_LABELS, train_dir,SOURCE_URL + TEST_LABELS) local_file = train_dir + "/" + TEST_LABELS |
更加数据实际存放路径,修改read_data_sets中读取文件路径。
|
1 2 3 |
mnist = input_data.read_data_sets("./TensorFlowOnSpark/mnist", one_hot=True) # 创建交互式session sess = tf.InteractiveSession() |
14.2.4.2 权重初始化
# 正态分布,标准差为0.1,默认最大为1,最小为-1,均值为0
|
1 2 3 4 5 6 7 |
def weight_variable(shape): initial = tf.truncated_normal(shape, stddev=0.1) return tf.Variable(initial) # 创建一个结构为shape矩阵也可以说是数组shape声明其行列,初始化所有值为0.1 def bias_variable(shape): initial = tf.constant(0.1, shape=shape) return tf.Variable(initial) |
14.2.4.3 构建卷积神经网络结构
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
# 卷积遍历各方向步数为1,SAME:边缘外自动补0,遍历相乘 def conv2d(x, W): return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME') # 池化卷积结果(conv2d)池化层采用kernel大小为2*2,步数也为2,周围补0,取最大值。数据量缩小了4倍 def max_pool_2x2(x): return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],strides=[1, 2, 2, 1], padding='SAME') #定义输入输出结构 # 声明一个占位符,None表示输入图片的数量不定,28*28图片分辨率 xs = tf.placeholder(tf.float32, [None, 28*28]) # 类别是0-9总共10个类别,对应输出分类结果 ys = tf.placeholder(tf.float32, [None, 10]) keep_prob = tf.placeholder(tf.float32) # x_image又把xs reshape成了28*28*1的形状,因为是灰色图片,所以通道是1.作为训练时的input,-1代表图片数量不定 x_image = tf.reshape(xs, [-1, 28, 28, 1]) #搭建网络,定义算法公式,也就是forward时的计算 ## 第一层卷积操作 ## # 第一二参数值得卷积核尺寸大小,即patch,第三个参数是图像通道数,第四个参数是卷积核的数目,代表会出现多少个卷积特征图像; W_conv1 = weight_variable([5, 5, 1, 32]) # 对于每一个卷积核都有一个对应的偏置量。 b_conv1 = bias_variable([32]) # 图片乘以卷积核,并加上偏执量,卷积结果28x28x32 h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) # 池化结果14x14x32 卷积结果乘以池化卷积核 h_pool1 = max_pool_2x2(h_conv1) ## 第二层卷积操作 ## # 32通道卷积,卷积出64个特征 w_conv2 = weight_variable([5,5,32,64]) # 64个偏执数据 b_conv2 = bias_variable([64]) # 注意h_pool1是上一层的池化结果,#卷积结果14x14x64 h_conv2 = tf.nn.relu(conv2d(h_pool1,w_conv2)+b_conv2) # 池化结果7x7x64 h_pool2 = max_pool_2x2(h_conv2) # 原图像尺寸28*28,第一轮图像缩小为14*14,共有32张,第二轮后图像缩小为7*7,共有64张 ## 第三层全连接操作 # 二维张量,第一个参数7*7*64的patch,第二个参数代表卷积个数共1024个 W_fc1 = weight_variable([7*7*64, 1024]) # 1024个偏执数据 b_fc1 = bias_variable([1024]) # 将第二层卷积池化结果reshape成只有一行7*7*64个数据# [n_samples, 7, 7, 64] ->> [n_samples, 7*7*64] h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64]) # 卷积操作,结果是1*1*1024,matmul实现最基本的矩阵相乘。 h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) # dropout操作,减少过拟合。对卷积结果执行dropout操作。 keep_prob = tf.placeholder(tf.float32) h_fc1_drop = tf.nn.dropout(h_fc1,keep_prob) ## 第四层输出操作 ## # 二维张量,1*1024矩阵卷积,共10个卷积,对应我们开始的ys长度为10 W_fc2 = weight_variable([1024, 10]) b_fc2 = bias_variable([10]) # 最后的分类,结果为1*1*10 softmax y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2) #定义交叉熵为loss函数,采用Adam方法优化loss。 cross_entropy = -tf.reduce_sum(ys * tf.log(y_conv)) train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) |
14.2.4.4 训练评估模型
|
1 2 3 4 5 6 7 8 9 10 11 |
#模型训练及评测 correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(ys,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) tf.global_variables_initializer().run() for i in range(2000): batch = mnist.train.next_batch(50) if i%100 == 0: train_accuracy = accuracy.eval(feed_dict={xs:batch[0], ys: batch[1], keep_prob: 1.0}) print("step %d, training accuracy %g"%(i, train_accuracy)) train_step.run(feed_dict={xs: batch[0], ys: batch[1], keep_prob: 0.5}) |
这里只迭代了2000次,运行结果;如果迭代20000次,在测试集上的精度可到99.2%左右
## -- End pasted text --
step 0, training accuracy 0.14
step 100, training accuracy 0.86
step 200, training accuracy 0.94
step 300, training accuracy 0.94
step 400, training accuracy 0.94
step 500, training accuracy 0.98
step 600, training accuracy 0.94
step 700, training accuracy 0.94
step 800, training accuracy 0.98
step 900, training accuracy 0.98
step 1000, training accuracy 1
step 1100, training accuracy 0.94
step 1200, training accuracy 0.98
step 1300, training accuracy 0.96
step 1400, training accuracy 0.92
step 1500, training accuracy 0.96
step 1600, training accuracy 0.96
step 1700, training accuracy 1
step 1800, training accuracy 1
step 1900, training accuracy 0.96
在测试集上,测试模型精度
|
1 2 |
print("test accuracy %g"%accuracy.eval(feed_dict={xs: mnist.test.images, ys: mnist.test.labels, keep_prob: 1.0})) test accuracy 0.9778 |
14.3TensorFlow实现循环神经网络
14.3.1循环神经网络简介
在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,
每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。
14.3.2LSTM循环神经网络简介
LSTM是一种特殊的RNNs,可以很好地解决长时依赖问题。
14.3.4TensorFlow实现循环神经网络
前面我们用卷积神经网络,对MNIST中的手写数进行设别,如果迭代20000次,精度可达到99.2左右,这个精度应该比较高;如果我们用循环神经网络来识别,是否可行?如果可以,效果如何?
为了适合使用RNN来识别,每张图片大小为28x28像素,我们把每张图片的每一行(元素个数为28)作为输入数据n_inputs,把每一行(一张图片共28行)看成是与时间序列有关的步数n_steps,这样图片的所有信息都用上了,而且适合使用RNN的应用场景。
启动ipython,进入ipython的交互式界面,导入需要的库,并启动交互式会话。
|
1 2 3 |
import tensorflow as tf import numpy as np sess = tf.InteractiveSession() |
加载数据,具体实现细节可参考14.2.4.1小节,这里就不详细说明了。
|
1 2 |
from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets("./TensorFlowOnSpark/mnist", one_hot=True) |
1. 构建模型
设置训练模型的超参数,学习速率,批量大小等。
|
1 2 |
learning_rate = 0.01 batch_size = 128 |
设置循环神经网络的参数,包括输入数长度,输入的步数,隐藏节点数,类别数等。
|
1 2 3 4 |
n_input = 28 n_steps = 28 n_hidden = 256 n_classes = 10 |
定义输入数据及权重等
|
1 2 |
x = tf.placeholder(tf.float32, [None, n_steps, n_input]) y = tf.placeholder(tf.float32, [None, n_classes]) |
定义权重及初始化偏移量
|
1 2 3 |
# Classifier weights and biases w = tf.Variable(tf.truncated_normal([n_hidden, n_classes])) b = tf.Variable(tf.zeros([n_classes])) |
定义并初始化Input gate、Forget gate、Output gate、Memory cell等的输入数据、权重、偏移量,这里采用tensorflow中truncated_normal函数初始化相关参数值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# Input gate: input, previous output, and bias ix = tf.Variable(tf.truncated_normal([n_input, n_hidden], -0.1, 0.1)) im = tf.Variable(tf.truncated_normal([n_hidden, n_hidden], -0.1, 0.1)) ib = tf.Variable(tf.zeros([1, n_hidden])) # Forget gate: input, previous output, and bias fx = tf.Variable(tf.truncated_normal([n_input, n_hidden], -0.1, 0.1)) fm = tf.Variable(tf.truncated_normal([n_hidden, n_hidden], -0.1, 0.1)) fb = tf.Variable(tf.zeros([1, n_hidden])) # Memory cell: input, state, and bias cx = tf.Variable(tf.truncated_normal([n_input, n_hidden], -0.1, 0.1)) cm = tf.Variable(tf.truncated_normal([n_hidden, n_hidden], -0.1, 0.1)) cb = tf.Variable(tf.zeros([1, n_hidden])) # Output gate: input, previous output, and bias ox = tf.Variable(tf.truncated_normal([n_input, n_hidden], -0.1, 0.1)) om = tf.Variable(tf.truncated_normal([n_hidden, n_hidden], -0.1, 0.1)) ob = tf.Variable(tf.zeros([1, n_hidden])) |
创建循环神经网络结构
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
def LSTMRNN(x, n_steps, n_input, n_hidden, n_classes): # 定义LSTM单元 def lstm_cell(i, o, state): input_gate = tf.sigmoid(tf.matmul(i, ix) + tf.matmul(o, im) + ib) forget_gate = tf.sigmoid(tf.matmul(i, fx) + tf.matmul(o, fm) + fb) update = tf.tanh(tf.matmul(i, cx) + tf.matmul(o, cm) + cb) state = forget_gate * state + input_gate * update output_gate = tf.sigmoid(tf.matmul(i, ox) + tf.matmul(o, om) + ob) return output_gate * tf.tanh(state), state # 把状态线上的多个值串联起来 outputs = list() state = tf.Variable(tf.zeros([batch_size, n_hidden])) output = tf.Variable(tf.zeros([batch_size, n_hidden])) # 输入数据x用函数transpose把第一个维度与第二个维度互换,使用reshape把x #变为(n_steps*batch_size,n_input)的形状,然后利用split把x拆成长度为n_steps #的列表,这样适合LMTM的输入格式。 x = tf.transpose(x, [1, 0, 2]) x = tf.reshape(x, [-1, n_input]) x = tf.split(x, n_steps, 0) for i in x: output, state = lstm_cell(i, output, state) outputs.append(output) logits =tf.matmul(outputs[-1], w) + b return logits |
2. 定义损失函数及优化器
|
1 2 3 4 5 6 7 8 9 10 11 12 |
pred = LSTMRNN(x, n_steps, n_input, n_hidden, n_classes) cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y)) optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1)) accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) # Initializing the variables init = tf.global_variables_initializer() # Launch the graph sess.run(init) |
3. 训练数据及评估模型
|
1 2 3 4 5 6 7 8 9 10 |
for step in range(10000): batch_x, batch_y = mnist.train.next_batch(batch_size) batch_x = batch_x.reshape((batch_size, n_steps, n_input)) sess.run(optimizer, feed_dict={x: batch_x, y: batch_y}) if step % 100 == 0: acc = sess.run(accuracy, feed_dict={x: batch_x, y: batch_y}) loss = sess.run(cost, feed_dict={x: batch_x, y: batch_y}) print "Iter " + str(step) + ", Minibatch Loss= " + "{:.6f}".format(loss) + ", Training Accuracy= " + "{:.5f}".format(acc) print "Optimization Finished!" |
运行结果,以下是最后批次的运行结果。
Iter 8000, Minibatch Loss= 0.085752, Training Accuracy= 0.97656
Iter 8100, Minibatch Loss= 0.065435, Training Accuracy= 0.96875
Iter 8200, Minibatch Loss= 0.088926, Training Accuracy= 0.97656
Iter 8300, Minibatch Loss= 0.039572, Training Accuracy= 1.00000
Iter 8400, Minibatch Loss= 0.050593, Training Accuracy= 0.98438
Iter 8500, Minibatch Loss= 0.030424, Training Accuracy= 0.99219
Iter 8600, Minibatch Loss= 0.026174, Training Accuracy= 0.99219
Iter 8700, Minibatch Loss= 0.045043, Training Accuracy= 0.98438
Iter 8800, Minibatch Loss= 0.031143, Training Accuracy= 0.98438
Iter 8900, Minibatch Loss= 0.055115, Training Accuracy= 0.99219
Iter 9000, Minibatch Loss= 0.061676, Training Accuracy= 0.98438
Iter 9100, Minibatch Loss= 0.123581, Training Accuracy= 0.97656
Iter 9200, Minibatch Loss= 0.057620, Training Accuracy= 0.98438
Iter 9300, Minibatch Loss= 0.043013, Training Accuracy= 0.99219
Iter 9400, Minibatch Loss= 0.067405, Training Accuracy= 0.98438
Iter 9500, Minibatch Loss= 0.020679, Training Accuracy= 1.00000
Iter 9600, Minibatch Loss= 0.079038, Training Accuracy= 0.98438
Iter 9700, Minibatch Loss= 0.080076, Training Accuracy= 0.97656
Iter 9800, Minibatch Loss= 0.010582, Training Accuracy= 1.00000
Iter 9900, Minibatch Loss= 0.019426, Training Accuracy= 1.00000
Optimization Finished!
在测试集上验证模型
|
1 2 3 4 5 |
# Calculate accuracy for 128 mnist test images test_len = batch_size test_data = mnist.test.images[:test_len].reshape((-1, n_steps, n_input)) test_label = mnist.test.labels[:test_len] print "Testing Accuracy:", sess.run(accuracy, feed_dict={x: test_data, y: test_label}) |
运行结果如下,这个结果虽然比CNN结果低些,但也是不错的一个结果。
Testing Accuracy: 0.976562
14.4分布式TensorFlow
2016年4月14日,Google发布了分布式TensorFlow,能够支持在几百台机器上并行训练。分布式的TensorFlow由高性能的gRPC库作为底层技术支持。
14.4.1客户端、主节点和工作节点间的关系
14.4.2分布式模式
常用的深度学习训练模型为数据并行化,即TensorFlow任务采用相同的训练模型在不同的小批量数据集上进行训练,然后在参数服务器上更新模型的共享参数。TensorFlow支持同步训练和异步训练两种模型训练方式。
14.4.3在Pyspark集群环境运行TensorFlow
这节将通过神经网络来模拟一个一元二次方程:y=x^2-0.5,
TensorFlowOnSpark的详细配置,请参考14.4节。已集群方式启动pyspark:
|
1 |
pyspark --master spark://master:7077 --driver-memory 1G --total-executor-cores 2 |
进入pyspark的交换界面
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt #构造满足一元二次方程的函数 x_data = np.linspace(-1, 1, 300)[:, np.newaxis] #加入一些噪声 noise = np.random.normal(0, 0.05, x_data.shape) y_data = np.square(x_data) - 0.5 + noise #画出散点图 fig=plt.figure() ax=fig.add_subplot(1,1,1) ax.scatter(x_data,y_data) |
构造一个神经网络
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
xs = tf.placeholder(tf.float32, [None, 1]) ys = tf.placeholder(tf.float32, [None, 1]) #定义添加层的函数 def add_layer(inputs, in_size, out_size, activation_function=None): weights = tf.Variable(tf.random_normal([in_size, out_size])) biases = tf.Variable(tf.zeros([1, out_size]) + 0.1) Wx_plus_b = tf.matmul(inputs, weights) + biases if activation_function is None: outputs = Wx_plus_b else: outputs = activation_function(Wx_plus_b) return outputs #构造输入层为1,隐藏层20个,输出层为1的神经网络 h1 = add_layer(xs, 1, 20, activation_function=tf.nn.relu) #构造输出层,隐含层的输出为输出层的输入 prediction = add_layer(h1, 20, 1, activation_function=None) #计算损失值 loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),reduction_indices=[1])) train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss) #初始化所以变量 init = tf.global_variables_initializer() sess = tf.Session() sess.run(init) #训练1000次 for i in range(1000): sess.run(train_step, feed_dict={xs: x_data, ys: y_data}) if i % 50 == 0: print(sess.run(loss, feed_dict={xs: x_data, ys: y_data})) prediction_value=sess.run(prediction,feed_dict={xs:x_data}) lines=ax.plot(x_data,prediction_value,'r',lw=5) |
输出结果:
1.62758
0.00996406
0.00634915
0.00483868
0.0043179
0.00399014
0.00368176
0.00337165
0.00309145
0.00284696
0.00267657
0.00255845
0.0024702
0.00240239
0.00235583
0.00232014
0.00229183
0.00226797
0.00224843
14.5TensorFlowOnSpark架构
TensorFlowOnSpark(TFoS),支持 TensorFlow 在 Spark 和 Hadoop 上的分布式运行。
14.6TensorFlowOnSpark安装
安装TensorFlowOnSpark,采用pip管理工具进行安装,缺省安装是1.0版本。
|
1 |
pip install tensorflowonspark |
执行以上命令后,在用户当前目录下,将新增一个TensorFlowOnSpark目录。
然后,在.bashrc定义该路径。
|
1 |
export TFoS_HOME=/home/hadoop/TensorFlowOnSpark |
可以通过pyspark环境来验证,以上2个安装是否成功。
|
1 2 3 |
pyspark >>> import tensorflow as tf >>> from tensorflowonspark import TFCluster |
导入这些库,如果没有异常,说明安装成功。接下来开始为训练数据做一些准备工作。
对scripts目录进行打包,便于把该包发布到各worker上
|
1 2 |
cd TensorFlowOnSpark/scripts zip -r ../tfspark.zip * |
14.7TensorFlowOnSpark实例
使用TensorFlowOnSpark对MNIST数据进行预测,MNIST是一个手写数字数据库,它有60000个训练样本集和10000个测试样本集,train-images-idx3-ubyte.gz、train-labels-idx1-ubyte.gz等四个文件。这些图像数据都保存在二进制文件中。每个样本图像的宽高为28*28。
下载MNIST数据
|
1 2 3 4 5 6 |
mkdir ${TFoS_HOME}/mnist pushd ${TFoS_HOME}/mnist curl -O "http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz" curl -O "http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz" curl -O "http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz" curl -O "http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz" |
14.7.1TensorFlowOnSpark单机模式实例
设置本机相关参数,在单机上启动一个master节点,两个worker节点。
|
1 2 3 4 5 |
export MASTER=spark://$(hostname):7077 export SPARK_WORKER_INSTANCES=2 export CORES_PER_WORKER=1 export TOTAL_CORES=$((${CORES_PER_WORKER}*${SPARK_WORKER_INSTANCES})) ${SPARK_HOME}/sbin/start-master.sh; ${SPARK_HOME}/sbin/start-slave.sh -c $CORES_PER_WORKER -m 2G ${MASTER} |
启动以后,通过jps可以看到如下一些进程。一个master,两个worker,namenode是之前启动hadoop的进程。
|
1 2 3 4 5 6 7 8 |
[hadoop@master ~]$ jps 25157 Master 25258 Worker 27229 RunJar 26893 NameNode 27087 SecondaryNameNode 13071 Jps 25215 Worker |
相关服务起来后,接下来把MNIST数据上传到HDFS上,并把数据转换cvs格式。
|
1 |
${SPARK_HOME}/bin/spark-submit --master spark://master:7077 ${TFoS_HOME}/examples/mnist/mnist_data_setup.py --output /examples/mnist/csv --format csv |
运行完成后,通过hadoop fs命令可以在HDFS上看到如下信息:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
hadoop fs -ls /user/hadoop/examples/mnist/csv/train/images Found 11 items -rw-r--r-- 1 hadoop supergroup 0 2017-06-15 23:21 /user/hadoop/examples/mnist/csv/train/images/_SUCCESS -rw-r--r-- 1 hadoop supergroup 9338236 2017-06-15 23:21 /user/hadoop/examples/mnist/csv/train/images/part-00000 -rw-r--r-- 1 hadoop supergroup 11231804 2017-06-15 23:21 /user/hadoop/examples/mnist/csv/train/images/part-00001 -rw-r--r-- 1 hadoop supergroup 11214784 2017-06-15 23:21 /user/hadoop/examples/mnist/csv/train/images/part-00002 -rw-r--r-- 1 hadoop supergroup 11226100 2017-06-15 23:21 /user/hadoop/examples/mnist/csv/train/images/part-00003 -rw-r--r-- 1 hadoop supergroup 11212767 2017-06-15 23:21 /user/hadoop/examples/mnist/csv/train/images/part-00004 -rw-r--r-- 1 hadoop supergroup 11173834 2017-06-15 23:21 /user/hadoop/examples/mnist/csv/train/images/part-00005 -rw-r--r-- 1 hadoop supergroup 11214285 2017-06-15 23:21 /user/hadoop/examples/mnist/csv/train/images/part-00006 -rw-r--r-- 1 hadoop supergroup 11201024 2017-06-15 23:21 /user/hadoop/examples/mnist/csv/train/images/part-00007 -rw-r--r-- 1 hadoop supergroup 11194141 2017-06-15 23:21 /user/hadoop/examples/mnist/csv/train/images/part-00008 -rw-r--r-- 1 hadoop supergroup 10449019 2017-06-15 23:21 /user/hadoop/examples/mnist/csv/train/images/part-00009 |
数据加载转换成功后,开始训练数据。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
${SPARK_HOME}/bin/spark-submit \ --master ${MASTER} \ --py-files ${TFoS_HOME}/tfspark.zip,${TFoS_HOME}/examples/mnist/spark/mnist_dist.py \ --conf spark.cores.max=${TOTAL_CORES} \ --conf spark.task.cpus=${CORES_PER_WORKER} \ --conf spark.executorEnv.JAVA_HOME="$JAVA_HOME" \ ${TFoS_HOME}/examples/mnist/spark/mnist_spark.py \ --cluster_size ${SPARK_WORKER_INSTANCES} \ --images examples/mnist/csv/train/images \ --labels examples/mnist/csv/train/labels \ --format csv \ --mode train \ --model mnist_model |
运行完成后,可以看到如下内容:
|
1 2 3 4 |
2017-06-18 05:30:50,072 INFO (MainThread-25741) Feeding training data 2017-06-18 05:32:07,655 INFO (MainThread-25741) Stopping TensorFlow nodes 2017-06-18 05:32:07,883 INFO (MainThread-25741) Shutting down cluster 2017-06-18T05:32:13.346161 ===== Stop |
如果运行过程中,过程被卡,可以调整mnist_dist.py文件中两处(在115,125行)logdir=logdir改为logdir=None。
训练完成后,接下来就是用测试集验证模型,并对结果进行预测。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
${SPARK_HOME}/bin/spark-submit \ --master ${MASTER} \ --py-files ${TFoS_HOME}/tfspark.zip,${TFoS_HOME}/examples/mnist/spark/mnist_dist.py \ --conf spark.cores.max=${TOTAL_CORES} \ --conf spark.task.cpus=${CORES_PER_WORKER} \ --conf spark.executorEnv.JAVA_HOME="$JAVA_HOME" \ ${TFoS_HOME}/examples/mnist/spark/mnist_spark.py \ --cluster_size ${SPARK_WORKER_INSTANCES} \ --images examples/mnist/csv/test/images \ --labels examples/mnist/csv/test/labels \ --mode inference \ --format csv \ --model mnist_model \ --output predictions |
运行完成以后,在HDFS上,就可看到predictions目录及相关内容。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
[hadoop@master spark]$ hadoop fs -ls /user/hadoop/predictions 17/06/20 02:45:57 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Found 11 items -rw-r--r-- 1 hadoop supergroup 0 2017-06-18 14:04 /user/hadoop/predictions/_SUCCESS -rw-r--r-- 1 hadoop supergroup 51000 2017-06-18 14:04 /user/hadoop/predictions/part-00000 -rw-r--r-- 1 hadoop supergroup 51000 2017-06-18 14:04 /user/hadoop/predictions/part-00001 -rw-r--r-- 1 hadoop supergroup 51000 2017-06-18 14:04 /user/hadoop/predictions/part-00002 -rw-r--r-- 1 hadoop supergroup 51000 2017-06-18 14:04 /user/hadoop/predictions/part-00003 -rw-r--r-- 1 hadoop supergroup 51000 2017-06-18 14:04 /user/hadoop/predictions/part-00004 -rw-r--r-- 1 hadoop supergroup 51000 2017-06-18 14:04 /user/hadoop/predictions/part-00005 -rw-r--r-- 1 hadoop supergroup 51000 2017-06-18 14:04 /user/hadoop/predictions/part-00006 -rw-r--r-- 1 hadoop supergroup 51000 2017-06-18 14:04 /user/hadoop/predictions/part-00007 -rw-r--r-- 1 hadoop supergroup 51000 2017-06-18 14:04 /user/hadoop/predictions/part-00008 -rw-r--r-- 1 hadoop supergroup 51000 2017-06-18 14:04 /user/hadoop/predictions/part-00009 |
打开其中一个文件,可以看到预测结果信息。
2017-06-18T05:51:42.397905 Label: 5, Prediction: 5
2017-06-18T05:51:42.397923 Label: 9, Prediction: 8
2017-06-18T05:51:42.397941 Label: 7, Prediction: 5
2017-06-18T05:51:42.397958 Label: 3, Prediction: 5
2017-06-18T05:51:42.397976 Label: 4, Prediction: 8
2017-06-18T05:51:42.397993 Label: 9, Prediction: 8
2017-06-18T05:51:42.398012 Label: 6, Prediction: 5
14.7.2TensorFlowOnSpark集群模式实例
设置本机相关参数,在以集群方式启动spark,一个master节点,slave1、slave2作为
两个worker节点,各节点资源配置信息。
训练模型
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
${SPARK_HOME}/bin/spark-submit \ --master spark://master:7077 \ --py-files ${TFoS_HOME}/tfspark.zip,${TFoS_HOME}/examples/mnist/spark/mnist_dist.py \ --conf spark.cores.max=4 \ --conf spark.task.cpus=2 \ --conf spark.executorEnv.JAVA_HOME="$JAVA_HOME" \ --conf spark.executorEnv.LD_LIBRARY_PATH="${JAVA_HOME}/jre/lib/amd64/server" \ --conf spark.executorEnv.CLASSPATH="$($HADOOP_HOME/bin/hadoop classpath --glob):${CLASSPATH}" \ ${TFoS_HOME}/examples/mnist/spark/mnist_spark.py \ --cluster_size 2 \ --images examples/mnist/csv/train/images \ --labels examples/mnist/csv/train/labels \ --format csv \ --mode train \ --model mnist_model |
测试模型
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
${SPARK_HOME}/bin/spark-submit \ --master ${MASTER} \ --py-files ${TFoS_HOME}/tfspark.zip,${TFoS_HOME}/examples/mnist/spark/mnist_dist.py \ --conf spark.cores.max=4 \ --conf spark.task.cpus=2 \ --conf spark.executorEnv.JAVA_HOME="$JAVA_HOME" \ ${TFoS_HOME}/examples/mnist/spark/mnist_spark.py \ --cluster_size 2 \ --images examples/mnist/csv/test/images \ --labels examples/mnist/csv/test/labels \ --mode inference \ --format csv \ --model mnist_model \ --output predictions |
查看运行结果
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
$ hadoop fs -ls /user/hadoop/predictions Found 11 items -rw-r--r-- 1 hadoop supergroup 0 2017-06-20 08:55 /user/hadoop/predictions/_SUCCESS -rw-r--r-- 1 hadoop supergroup 51000 2017-06-20 08:55 /user/hadoop/predictions/part-00000 -rw-r--r-- 1 hadoop supergroup 51000 2017-06-20 08:55 /user/hadoop/predictions/part-00001 -rw-r--r-- 1 hadoop supergroup 51000 2017-06-20 08:55 /user/hadoop/predictions/part-00002 -rw-r--r-- 1 hadoop supergroup 51000 2017-06-20 08:55 /user/hadoop/predictions/part-00003 -rw-r--r-- 1 hadoop supergroup 51000 2017-06-20 08:55 /user/hadoop/predictions/part-00004 -rw-r--r-- 1 hadoop supergroup 51000 2017-06-20 08:55 /user/hadoop/predictions/part-00005 -rw-r--r-- 1 hadoop supergroup 51000 2017-06-20 08:55 /user/hadoop/predictions/part-00006 -rw-r--r-- 1 hadoop supergroup 51000 2017-06-20 08:55 /user/hadoop/predictions/part-00007 -rw-r--r-- 1 hadoop supergroup 51000 2017-06-20 08:55 /user/hadoop/predictions/part-00008 -rw-r--r-- 1 hadoop supergroup 51000 2017-06-20 08:55 /user/hadoop/predictions/part-00009 |
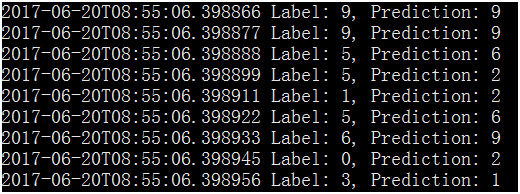
运行时各节点报错信息,可以查看spark/work/app-20170620085449-0003/1下的
14.8小结
为了弥补Spark机器学习中,缺乏神经网络、深度学习等的不足,这章我们介绍脱胎于AlphaGo的深度学习框架TensorFlow,以基础知识为主,在这个基础上介绍了使用TensorFlow的几个实例,最后介绍TensorFlow的分布式架构及与Spark整合的架构TensorFlowOnSpark。
新春佳节到。祝好!祝好!
不错不错!内容感觉好极了!