第1章我们介绍了NumPy,它是数据计算的基础,更是深度学习框架的基石。但如果直接使用NumPy计算大数据,其性能已成为一个瓶颈。
随着数据爆炸式增长,尤其是图像数据、音频数据等数据的快速增长,迫切需要突破这个瓶颈。需求就是强大动力!通过大咖们的不懈努力,在很多方面取得可喜进展,如硬件有GPU,软件有Theano、Keras、TensorFlow,算法有卷积神经网络、循环神经网络等等。
Theano是Python的一个库,为开源项目,在2008年,由Yoshua Bengio领导的加拿大蒙特利尔理工学院LISA实验室开发。对于解决大量数据的问题,使用Theano可能获得与手工用C实现差不多的性能。另外通过利用GPU,它能获得比CPU上的快很多数量级的性能。Theano开发者在2010年公布的测试报告中指出:在CPU上执行程序时,Theano程序性能是NumPy的1.8倍,而在GPU上是NumPy的11倍。这还是2010的测试结果,近些年无论是Theano还是GPU,性能都有显著提高。
这里我们把Theano作为基础来讲,除了其性能方面的跨越外,它还是“符合计算图”的开创者,当前很多优秀的开源工具,如TensorFlow、Keras等,都派生于或借鉴了Theano的底层设计。所以了解Theano的使用,将有助于我们更好学习TensorFlow、Keras等其他开源工具。
至于Theano是如何实现性能方面的跨越?如何用“符号计算图”来运算等,本章都将有所涉猎,但限于篇幅无法深入分析,只做一些基础性的介绍。涵盖的主要内容:
如何安装Theano
符号变量是什么
如何设计符号计算图
函数的功能
共享变量的妙用
2.1安装
这里主要介绍Linux+Anaconda+theano环境的安装说明,Linux为CentOS或Ubuntu都可以,安装Python、NumPy、SciPy等,建议使用Anaconda来安装,当然也可用pip进行安装。最好使用工具来安装,这样可以避免很多程序依赖的麻烦,而且日后的软件升级维护也很方便。
Theano支持CPU、GPU,如果使用GPU还需要安装其驱动程序如CUDA等,限于篇幅这里只介绍CPU的(TensorFlow将介绍基于GPU的安装),有关GPU的安装,大家可参考:http://www.deeplearning.net/software/theano/install.html
以下为安装主要步骤:
(1)安装anaconda
从anaconda官网:https://www.anaconda.com/download/下载linux环境最新的软件包,Python版本建议选择3系列的,2系列后续将不再维护。下载文件为一个sh程序包:如:
Anaconda3-4.3.1-Linux-x86_64.sh,然后在下载目录下运行如下命令:
安装过程中按enter或y即可,安装完成后,程序提示是否把anaconda的binary加入到.bashrc配置文件中,加入后运行python、ipython时将自动使用新安装的Python环境。
安装完成后,你可用conda list命令查看已安装的库:
安装成功的话,应该能看到numpy、scipy、matplotlib、conda等库。
(2)安装theano
利用conda 来安装或更新程序
(3)测试
先启动python,然后导入theano模块,如果不报错,说明安装成功。
Python 3.6.0 |Anaconda custom (64-bit)| (default, Dec 23 2016, 12:22:00)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-1)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import theano
>>>
2.2符号变量
存储数据需要用到各种变量,Theano如何使用变量的呢?Theano用一种变量类型称为符号变量来表示变量,用TensorVariable表示,又称为张量(Tensor),张量是Theano的核心元素(也是TensorFlow的核心元素),它是Theano表达式和运算操作的基本单位。张量可以是标量(scalar)、向量(vector)、矩阵(matrix)等的统称。具体来说,标量就是我们通常看到的0阶的张量,如12,a等,而向量和矩阵分别为1阶张量和2阶的张量。
如果通过这些概念,你还不很清楚,没有关系,可以结合以下一个实例,来直观感受一下。
首先定义三个标量:一个代表输入x、一个代表权重w、一个表示偏移量b,然后计算这些标量运算结果z=x*w+b,Theano代码实现如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#导入需要的库或模块 import theano from theano import tensor as T #初始化张量 x=T.scalar(name='input',dtype='float32') w=T.scalar(name='weight',dtype='float32') b=T.scalar(name='bias',dtype='float32') z=w*x+b #编译程序 net_input=theano.function(inputs=[w,x,b],outputs=z) #执行程序 print('net_input: %2f'% net_input(2.0,3.0,0.5)) |
打印结果
net_input: 6.500000
通过以上实例我们不难看出,Theano本身是一个通用的符号计算框架,与非符号架构的框架不同,它先使用tensor variable初始化变量,然后将复杂的符号表达式编译成为函数模型,最后运行时传入实际数据进行计算。整个过程涉及三个步骤:定义符号变量,编译代码,执行代码。这节主要介绍第一步如何定义符号变量,其他步骤将在后续小节介绍。
如何定义符号变量?或定义符号变量有哪些方式?在Theano中定义符号变量有大致三种:使用内置的变量类型、自定义变量类型、转换其他的变量类型,具体如下:
(1)使用内置的变量类型创建
目前Theano支持7种内置的变量类型,分别是标量(scalar)、向量(vector)、行(row)、列(col)、矩阵(matrix)、tensor3、tensor4等。其中标量是0阶张量,向量为1阶张量,矩阵为二阶张量等,以下为创建内置变量的实例:
|
1 2 3 4 5 |
import theano from theano import tensor as T x=T.scalar(name='input',dtype='float32') data=T.vector(name='data',dtype='float64') |
其中,name指定变量名字,dtype指变量的数据类型。
(2)自定义变量类型
内置的变量类型只能处理4维及以下的变量,如果需要处理更高维的数据时,我们可以使用Theano的自定义变量类型,具体通过TensorType方法来实现:
|
1 2 3 4 |
import theano from theano import tensor as T mytype=T.TensorType('float64',broadcastable=(),name=None,sparse_grad=False) |
其中broadcastable是True或False的布尔类型元组,元组的大小等于变量的维度,如果为True,表示变量在对应维度上的数据可以进行广播,否则数据不能广播。
广播机制(broadcast)是一种重要机制,有了这种机制,就可以方便对不同维的张量进行运算,否则,就要手工把低维数据变成高维,利用广播机制系统自动利用复制等方法把低维数据补齐,numpy也有这种机制。以下我们通过图1-2所示的一个实例来说明广播机制原理:
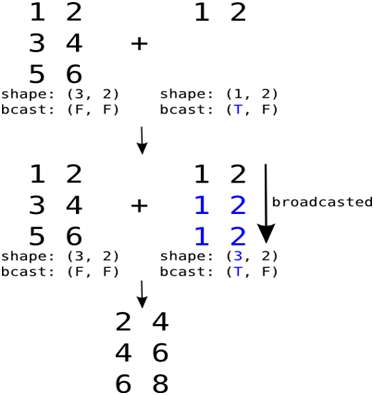
图2-1 广播机制
图2-1中矩阵与向量相加的具体代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import theano import numpy as np import theano.tensor as T r = T.row() r.broadcastable # (True, False) mtr = T.matrix() mtr.broadcastable # (False, False) f_row = theano.function([r, mtr], [r + mtr]) R = np.arange(1,3).reshape(1,2) print(R) #array([[1, 2]]) M = np.arange(1,7).reshape(3, 2) print(M) #array([[1, 2], # [3, 4], # [5, 6]]) f_row(R, M) #[array([[ 2., 4.], # [ 4., 6.], # [ 6., 8.]])] |
(3) 将Python类型变量或者Numpy类型变量转化为Theano共享变量
共享变量是Theano实现变量更新的重要机制,后面我们会详细讲解。要创建一个共享变量,只要把一个Python对象或NumPy对象传递给shared函数即可,如下示例:
|
1 2 3 4 5 6 7 |
import theano import numpy as np import theano.tensor as T data=np.array([[1,2],[3,4]]) shared_data=theano.shared(data) type(shared_data) |
2.3符号计算图模型
符号变量定义后,需要说明这些变量间的运算关系,如何描述变量间的运算关系? Theano实际采用符号计算图模型来实现。首先创建表达式所需的变量,然后通过操作符(op)把这些变量结合在一起。如图2-1。
Theano处理符号表达式时通过把符号表达式转换为一个计算图(graph)来处理(TensorFlow也使用了这种方法,等到我们介绍TensorFlow时,大家可对比一下),符号计算图的节点有:variable、type、apply和op。
variable节点:即符号的变量节点,符号变量是符号表达式存放信息的数据结构,可以分为输入符号和输出符号。
type节点:当定义了一种具体的变量类型以及变量的数据类型时,Theano为其指定数据存储的限制条件。
apply节点:把某一种类型的符号操作符应用到具体的符号变量中,与variable不同,apply节点无须由用户指定,一个apply节点包括3个字段:op、inputs、outputs。
op节点:即操作符节点,定义了一种符号变量间的运算,如+、-、sum()、tanh()等。
Theano是将符号表达式的计算表示成graphs。这些graphs是由Apply 和 Variable将节点连接而组成,它们分别与函数的应用和数据相连接。 操作由 Op 实例表示,而数据类型由 Type 实例表示。下面这段代码和图2-2,说明了这些代码所构建的结构。借助这个图或许有助于您进一步理解,如何将这些内容拟合在一起:
|
1 2 3 4 5 6 7 |
import theano import numpy as np import theano.tensor as T x = T.dmatrix('x') y = T.dmatrix('y') z = x + y |

图2-2 符号计算图
图2-2中箭头表示指向python对象的引用。这里的蓝色盒子是一个 Apply 节点,红色盒子是 Variable 节点,绿色圆圈是Ops,紫色盒子是 Types。
在创建 Variables 之后,应用 Apply Ops得到更多的变量,这些变量仅仅是一个占位符,在function中作为输入。变量指向 Apply 节点的过程是用来表示函数通过它们的owner 域来生成它们 。这些Apply节点是通过它们的inputs和outputs域来得到它们的输入和输出变量。
x 和 y 的owner 域的指向都是None,是因为它们不是另一个计算的结果。如果它们中的一个是另一个计算的结果,那么owner域将会指向另一个蓝色盒。
2.4函数
上节我们介绍了如何把一个符号表达式转化为符号计算图,这节我们介绍函数的功能,函数是Theano的一个核心设计模块,它提供一个接口,把函数计算图编译为可调用的函数对象。前面介绍了如何定义自变量x(不需要赋值),这节介绍如何编写函数方程。
(1)函数定义的格式
theano.function(inputs, outputs, mode=None, updates=None, givens=None, no_default_updates=False, accept_inplace=False, name=None,rebuild_strict=True, allow_input_downcast=None, profile=None, on_unused_input='raise')。
这里参数看起来很多,但常用的一般只用到三个,inputs表示自变量、outputs表示函数的因变量(也就是函数的返回值),还有另外一个比较常用的是updates这个参数,这个一般用于神经网络共享变量参数更新,通常以字典或元组列表的形式指定;givens是一个字典或元组列表,记为[(var1,var2)],表示在每一次函数调用时,在符号计算图中,把符号变量var1节点替换为var2节点,该参数常用来指定训练数据集的batch大小。
我们看一个有多个自变量、同时又有多个因变量的函数定义例子:
|
1 2 3 4 5 6 7 8 9 |
import theano x, y =theano.tensor.fscalars('x', 'y') z1= x + y z2=x*y #定义x、y为自变量,z1、z2为函数返回值(因变量) f =theano.function([x,y],[z1,z2]) #返回当x=2,y=3的时候,函数f的因变量z1,z2的值 print(f(2,3)) |
打印结果
[array(5.0, dtype=float32), array(6.0, dtype=float32)]
在执行theano.function()时,Theano进行了编译优化,得到一个end-to-end的函数,传入数据调用f(2,3)时,执行的是优化后保存在图结构中的模型,而不是我们写的那行z=x+y,尽管二者结果一样。这样的好处是Theano可以对函数f进行优化,提升速度;坏处是不方便开发和调试,由于实际执行的代码不是我们写的代码,所以无法设置断点进行调试,也无法直接观察执行时中间变量的值。
(2)自动求导
Theano有了符号计算图2-2,自动计算导数就很容易了。tensor.grad()唯一需要做的就是从outputs逆向遍历到输入节点。对于每个Op,它都定义了怎么根据输入计算出偏导数。使用链式法则就可以计算出梯度了。利用Theano求导时非常方便,可以直接利用函数theano.grad(),比如求S函数的导数:

以下代码实现当x=3的时候,求s函数的导数:
|
1 2 3 4 5 6 |
import theano x =theano.tensor.fscalar('x')#定义一个float类型的变量x y= 1 / (1 + theano.tensor.exp(-x))#定义变量y dx=theano.grad(y,x)#偏导数函数 f= theano.function([x],dx)#定义函数f,输入为x,输出为s函数的偏导数 print(f(3))#计算当x=3的时候,函数y的偏导数 |
打印结果
0.045176658779382706
(3)更新共享变量参数
在深度学习中通常需要迭代多次,每次迭代都需要更新参数。Theano如何更新参数呢?在theano.function函数中,有个非常重要的参数updates,updates是一个包含两个元素的列表或tuple,updates=[old_w,new_w],当函数被调用的时候,这个会用new_w替换old_w,具体看下面这个例子。
|
1 2 3 4 5 6 |
import theano w= theano.shared(1)#定义一个共享变量w,其初始值为1 x=theano.tensor.iscalar('x') f=theano.function([x], w, updates=[[w, w+x]])#定义函数自变量为x,因变量为w,当函数执行完毕后,更新参数w=w+x print(f(3))#函数输出为w print(w.get_value())#这个时候可以看到w=w+x为4 |
打印结果:1、4
在求梯度下降的时候,经常用到updates这个参数。比如updates=[w,w-α*(dT/dw)],其中dT/dw就是我们梯度下降的时候,代价函数对参数w的偏导数,α是学习速率。为便于大家的更全面的了解Theano函数一些使用,下面我们通过一个逻辑回归的完整实例来说明:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
import numpy as np import theano import theano.tensor as T rng = np.random # 我们为了测试,自己生成10个样本,每个样本是3维的向量,然后用于训练 N = 10 feats = 3 D = (rng.randn(N, feats).astype(np.float32), rng.randint(size=N, low=0, high=2).astype(np.float32)) # 声明自变量x、以及每个样本对应的标签y(训练标签) x = T.matrix("x") y = T.vector("y") #随机初始化参数w、b=0,为共享变量 w = theano.shared(rng.randn(feats), name="w") b = theano.shared(0., name="b") #构造代价函数 p_1 = 1 / (1 + T.exp(-T.dot(x, w) - b)) # s激活函数 xent = -y * T.log(p_1) - (1-y) * T.log(1-p_1) # 交叉商代价函数 cost = xent.mean() + 0.01 * (w ** 2).sum()# 代价函数的平均值+L2正则项以防过拟合,其中权重衰减系数为0.01 gw, gb = T.grad(cost, [w, b]) #对总代价函数求参数的偏导数 prediction = p_1 > 0.5 # 大于0.5预测值为1,否则为0. train = theano.function(inputs=[x,y],outputs=[prediction, xent],updates=((w, w - 0.1 * gw), (b, b - 0.1 * gb)))#训练所需函数 predict = theano.function(inputs=[x], outputs=prediction)#测试阶段函数 #训练 training_steps = 1000 for i in range(training_steps): pred, err = train(D[0], D[1]) print (err.mean())#查看代价函数下降变化过程 |
2.5条件与循环
编写函数需要经常用到条件或循环,这节我们就简单介绍Theano如何实现条件判断或逻辑循环。 (1)条件判断 Theano是一种符号语言,条件判断不能直接使用Python的if语句。在Theano可以用ifelse 和 Switch来表示判定。这两个判决语句有何区别呢? switch对每个输出变量进行操作,ifelse只对一个满足条件的变量操作,比如: 对语句: switch(cond, ift, iff) 如果满足条件,则switch既执行ift也执行iff。对语句: if cond then ift else iff ifelse只执行ift或者只执行iff 以下通过一个示例进一步说明
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
from theano import tensor as T from theano.ifelse import ifelse import theano,time,numpy a,b=T.scalars('a','b') x,y=T.matrices('x','y') z_switch=T.switch(T.lt(a,b),T.mean(x),T.mean(y))#lt:a < b? z_lazy=ifelse(T.lt(a,b),T.mean(x),T.mean(y)) #optimizer:optimizer的类型结构(可以简化计算,增加计算的稳定性) #linker:决定使用哪种方式进行编译(C/Python) f_switch = theano.function([a, b, x, y], z_switch,mode=theano.Mode(linker='vm')) f_lazyifelse = theano.function([a, b, x, y], z_lazy,mode=theano.Mode(linker='vm')) val1 = 0. val2 = 1. big_mat1 = numpy.ones((1000, 100)) big_mat2 = numpy.ones((1000, 100)) n_times = 10 tic = time.clock() for i in range(n_times): f_switch(val1, val2, big_mat1, big_mat2) print('time spent evaluating both values %f sec' % (time.clock() - tic)) tic = time.clock() for i in range(n_times): f_lazyifelse(val1, val2, big_mat1, big_mat2) print('time spent evaluating one value %f sec' % (time.clock() - tic)) |
打印结果
time spent evaluating both values 0.005268 sec
time spent evaluating one value 0.007501 sec
(2)循环语句
scan是theano中构建循环Graph的方法,scan是个灵活复杂的函数,任何用循环、递归或者跟序列有关的计算,都可以用scan完成。其格式如下:
theano.scan(fn, sequences=None, outputs_info=None, non_sequences=None, n_steps=None, truncate_gradient=-1, go_backwards=False, mode=None, name=None, profile=False, allow_gc=None, strict=False)
参数说明:
fn:函数类型,scan的一步执行。除了outputs_info,fn可以返回sequences变量的更新updates。fn的输入变量顺序为sequences中的变量,outputs_info的变量,non_sequences中的变量。如果使用了taps,则按照taps给fn喂变量。taps的详细介绍会在后面的例子中给出。
sequences:scan进行迭代的变量,scan会在T.arange()生成的list上遍历,例如下面的polynomial 例子。
outputs_info:初始化fn的输出变量,和输出的shape一致。如果初始化值设为None表示这个变量不需要初始值。
non_sequences:fn函数用到的其他变量,迭代过程中不可改变(unchange)。
n_steps:fn的迭代次数。
下面通过一个例子解释scan函数的具体使用方法。
代码实现思路是:先定义函数one_step,它就是scan里的fn,其任务就是计算多项式的一项,scan函数返回的result里会保存多项式每一项的值,然后我们对result求和,就得到了多项式的值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
import theano import theano.tensor as T import numpy as np # 定义单步的函数,实现a*x^n # 输入参数的顺序要与下面scan的输入参数对应 def one_step(coef, power, x): return coef * x ** power coefs = T.ivector() # 每步变化的值,系数组成的向量 powers = T.ivector() # 每步变化的值,指数组成的向量 x = T.iscalar() # 每步不变的值,自变量 # seq,out_info,non_seq与one_step函数的参数顺序一一对应 # 返回的result是每一项的符号表达式组成的list result, updates = theano.scan(fn = one_step, sequences = [coefs, powers], outputs_info = None, non_sequences = x) # 每一项的值与输入的函数关系 f_poly = theano.function([x, coefs, powers], result, allow_input_downcast=True) coef_val = np.array([2,3,4,6,5]) power_val = np.array([0,1,2,3,4]) x_val = 10 print("多项式各项的值: ",f_poly(x_val, coef_val, power_val)) #scan返回的result是每一项的值,并没有求和,如果我们只想要多项式的值,可以把f_poly写成这样: # 多项式每一项的和与输入的函数关系 f_poly = theano.function([x, coefs, powers], result.sum(), allow_input_downcast=True) print("多项式和的值:",f_poly(x_val, coef_val, power_val)) |
打印结果
多项式各项的值: [ 2 30 400 6000 50000]
多项式和的值: 56432
2.6共享变量
共享变量(shared variable)是实现机器学习算法参数更新的重要机制。shared函数会返回共享变量。这种变量的值在多个函数可直接共享。可以用符号变量的地方都可以用共享变量。但不同的是,共享变量有一个内部状态的值,这个值可以被多个函数共享。它可以存储在显存中,利用GPU提高性能。我们可以使用get_value和set_value方法来读取或者修改共享变量的值,使用共享变量实现累加操作。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import theano import theano.tensor as T from theano import shared import numpy as np #定义一个共享变量,并初始化为0 state = shared(0) inc = T.iscalar('inc') accumulator = theano.function([inc], state, updates=[(state, state+inc)]) # 打印state的初始值 print(state.get_value()) accumulator(1) # 进行一次函数调用 # 函数返回后,state的值发生了变化 print(state.get_value()) |
这里state是一个共享 变量,初始化为0,每次调用accumulator(),state都会加上inc。共享变量可以像普通张量一样用于符号表达式,另外,他还有自己的值,可以直接用.get_value()和.set_value()方法来访问和修改。
上述代码引入了函数中updates参数。updates参数是一个list,其中每个元素是一个元组(tuple),这个tuple的第一个元素是一个共享变量,第二个元素是一个新的表达式。updatas中的共享变量会在函数返回后更新自己的值。updates的作用在于执行效率,updates多数时候可以用原地(in-place)算法快速实现,在GPU上,Theano可以更好地控制何时何地给共享变量分配空间,带来性能提升。最常见的神经网络权值更新,一般会用update实现。
2.7小结
Theano基于NumPy,但性能方面又高于NumPy。因Theano采用了张量(Tensor)这个核心元素,在计算方面采用符号计算模型,而且采用共享变量、自动求导、利用GPU等适合于大数据、深度学习的方法,其他很多开发项目也深受这些技术和框架影响。本章主要为后续介绍TensorFlow做个铺垫。
Pingback引用通告: Python深度学习—-TensorFlow卷 – 飞谷云人工智能