本文将介绍如何使用 Keras + Tensorflow1.6,python为3.6 创建卷积神经网络,并对其进行训练,以使得车辆保持在两条白线之间,如下图:

|
1 2 3 4 5 6 7 |
import os import urllib.request import pickle %matplotlib inline import matplotlib from matplotlib.pyplot import imshow |
下载数据
|
1 2 3 4 |
#downlaod driving data (450Mb) data_url = 'https://s3.amazonaws.com/donkey_resources/indoor_lanes.pkl' file_path, headers = urllib.request.urlretrieve(data_url) print(file_path) |
备注:由于下载经常出现超时情况,大家可以先下载该文件,然后放到指定目录。
|
1 |
file_path='./autocar/indoor_lanes.pkl' |
步骤1:获取驾驶数据
数据集由 ~7900 个图像和手动开车时收集的转向角组成。大约三分之二的图像与线之间的汽车。另外三分之一的车开始偏离航线,并且驶回线路之间。
数据集由 2 个 pickled 数组组成。X 是图像阵列,Y 是相应转向角度的阵列。
|
1 2 3 4 5 6 7 |
#抽取数据 with open(file_path, 'rb') as f: X, Y = pickle.load(f) print('X.shape: ', X.shape) print('Y.shape: ', Y.shape) imshow(X[0]) |
打印结果
X.shape: (7892, 120, 160, 3)
Y.shape: (7892,)

步骤2:拆分数据
在这里,对数据进行洗牌(shuffle),并将数据分成三部分。训练数据将用于训练我们的驾驶模型,使用验证数据避免过度拟合模型,测试数据用于测试我们的模型。
|
1 2 3 4 5 6 7 8 9 10 |
import numpy as np #用shuffle把数据打乱 def unison_shuffled_copies(X, Y): assert len(X) == len(Y) p = np.random.permutation(len(X)) return X[p], Y[p] shuffled_X, shuffled_Y = unison_shuffled_copies(X,Y) len(shuffled_X) |
打印结果
7892
|
1 2 3 4 5 6 7 8 |
test_cutoff = int(len(X) * .8) # 80% of data used for training val_cutoff = test_cutoff + int(len(X) * .1) # 10% of data used for validation and test data train_X, train_Y = shuffled_X[:test_cutoff], shuffled_Y[:test_cutoff] val_X, val_Y = shuffled_X[test_cutoff:val_cutoff], shuffled_Y[test_cutoff:val_cutoff] test_X, test_Y = shuffled_X[val_cutoff:], shuffled_Y[val_cutoff:] len(train_X) + len(val_X) + len(test_X) |
打印结果
7892
步骤3:增强训练数据
为了加倍我们的训练数据并防止转向偏差,我们翻转每个图像和转向角并将其添加到数据集中。还有其他的方法来增加使用翻译和假阴影驾驶数据,但我没有使用这些自动驾驶仪。
|
1 2 3 4 5 |
X_flipped = np.array([np.fliplr(i) for i in train_X]) Y_flipped = np.array([-i for i in train_Y]) train_X = np.concatenate([train_X, X_flipped]) train_Y = np.concatenate([train_Y, Y_flipped]) len(train_X) |
打印结果
12626
步骤4:创建驾驶模式
这种驾驶模式将是一个端到端的神经网络,接受图像阵列作为输入,并输出-90(左)和90(右)之间的转向角。 要做到这一点,我们将使用一个完全连接图层的3层卷积网络。该模型基于 Otavio 的 Carputer,但不产生油门值输出,不使用过去的转向值作为模型的输入,并且使用较少的卷积层。
|
1 2 3 |
from tensorflow.python.keras.models import Model, load_model from tensorflow.python.keras.layers import Input, Convolution2D, MaxPooling2D, Activation, Dropout, Flatten, Dense from tensorflow.python.keras import backend as K |
使用 TensorFlow 后端。
查看目前image数据格式,是tensorflow格式(channels_last) 还是theano格式(channels_first)
|
1 |
K.image_data_format() |
'channels_last'
如果不是tensorflow格式,可以通过K.set_image_data_format('channels_last')进行修改,或修改~/.keras/keras.json文件。 前者只对当前会话有效,后者修改,将永久有效。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
img_in = Input(shape=(120, 160, 3), name='img_in') angle_in = Input(shape=(1,), name='angle_in') x = Convolution2D(8, kernel_size=(3, 3),strides=(1,1))(img_in) x = Activation('relu')(x) x = MaxPooling2D(pool_size=(2, 2))(x) x = Convolution2D(16, kernel_size=(3, 3),strides=(1,1))(x) x = Activation('relu')(x) x = MaxPooling2D(pool_size=(2, 2))(x) x = Convolution2D(32, kernel_size=(3, 3),strides=(1,1))(x) x = Activation('relu')(x) x = MaxPooling2D(pool_size=(2, 2))(x) merged = Flatten()(x) x = Dense(256)(merged) x = Activation('linear')(x) x = Dropout(.2)(x) angle_out = Dense(1, name='angle_out')(x) model = Model(inputs=[img_in], outputs=[angle_out]) model.compile(optimizer='adam', loss='mean_squared_error') model.summary() |
打印结果
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
img_in (InputLayer) (None, 120, 160, 3) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 118, 158, 8) 224
_________________________________________________________________
activation_1 (Activation) (None, 118, 158, 8) 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 59, 79, 8) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 57, 77, 16) 1168
_________________________________________________________________
activation_2 (Activation) (None, 57, 77, 16) 0
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 28, 38, 16) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 26, 36, 32) 4640
_________________________________________________________________
activation_3 (Activation) (None, 26, 36, 32) 0
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 13, 18, 32) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 7488) 0
_________________________________________________________________
dense_1 (Dense) (None, 256) 1917184
_________________________________________________________________
activation_4 (Activation) (None, 256) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 256) 0
_________________________________________________________________
angle_out (Dense) (None, 1) 257
=================================================================
Total params: 1,923,473
Trainable params: 1,923,473
Non-trainable params: 0
步骤5:训练模型
我们已经学会了很难的方法,即使这一切都是完美的,如果你没有正确地训练,你的自动驾驶仪将无法工作。我遇到的最大的问题是过度适应模型,以至于在很少的情况下都不能正常工作。 这里是 2 个 Keras回调,将节省您的时间。 警告 - 如果仅使用CPU,则需要较长时间,这里我采用GPU进行训练
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import os from tensorflow.python.keras import callbacks model_path = os.path.expanduser('~/best_autopilot.hdf5') #Save the model after each epoch if the validation loss improved. save_best = callbacks.ModelCheckpoint(model_path, monitor='val_loss', verbose=1, save_best_only=True, mode='min') #stop training if the validation loss doesn't improve for 5 consecutive epochs. early_stop = callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=5, verbose=0, mode='auto') callbacks_list = [save_best, early_stop] |
因时间关系,这里只进行 10 次迭代(epochs),训练时间2分钟左右,比较快。
|
1 |
model.fit(train_X, train_Y, batch_size=64, epochs=10, validation_data=(val_X, val_Y), callbacks=callbacks_list) |
运行结果
Train on 12626 samples, validate on 789 samples
Epoch 1/10
12608/12626 [============================>.]12608/12626 [============================>.] - ETA: 0s - loss: 41288.4184
Epoch 00001: val_loss improved from inf to 656.89127, saving model to /home/wumg/best_autopilot.hdf5
12626/12626 [==============================]12626/12626 [==============================] - 22s 2ms/step - loss: 41230.2161 - val_loss: 656.8913
Epoch 2/10
12608/12626 [============================>.]12608/12626 [============================>.] - ETA: 0s - loss: 550.5565
Epoch 00002: val_loss improved from 656.89127 to 543.14232, saving model to /home/wumg/best_autopilot.hdf5
12626/12626 [==============================]12626/12626 [==============================] - 15s 1ms/step - loss: 550.1622 - val_loss: 543.1423
Epoch 3/10
12608/12626 [============================>.]12608/12626 [============================>.] - ETA: 0s - loss: 476.8377
Epoch 00003: val_loss improved from 543.14232 to 417.43844, saving model to /home/wumg/best_autopilot.hdf5
12626/12626 [==============================]12626/12626 [==============================] - 15s 1ms/step - loss: 476.6054 - val_loss: 417.4384
Epoch 4/10
12608/12626 [============================>.]12608/12626 [============================>.] - ETA: 0s - loss: 420.1108
Epoch 00004: val_loss improved from 417.43844 to 416.97928, saving model to /home/wumg/best_autopilot.hdf5
12626/12626 [==============================]12626/12626 [==============================] - 15s 1ms/step - loss: 420.0584 - val_loss: 416.9793
Epoch 5/10
12608/12626 [============================>.]12608/12626 [============================>.] - ETA: 0s - loss: 399.4089
Epoch 00005: val_loss did not improve
12626/12626 [==============================]12626/12626 [==============================] - 15s 1ms/step - loss: 399.0109 - val_loss: 420.7120
Epoch 6/10
12608/12626 [============================>.]12608/12626 [============================>.] - ETA: 0s - loss: 373.5299
Epoch 00006: val_loss improved from 416.97928 to 411.31800, saving model to /home/wumg/best_autopilot.hdf5
12626/12626 [==============================]12626/12626 [==============================] - 15s 1ms/step - loss: 373.7999 - val_loss: 411.3180
Epoch 7/10
12608/12626 [============================>.]12608/12626 [============================>.] - ETA: 0s - loss: 356.3707
Epoch 00007: val_loss improved from 411.31800 to 384.65238, saving model to /home/wumg/best_autopilot.hdf5
12626/12626 [==============================]12626/12626 [==============================] - 15s 1ms/step - loss: 356.4031 - val_loss: 384.6524
Epoch 8/10
12608/12626 [============================>.]12608/12626 [============================>.] - ETA: 0s - loss: 338.6780
Epoch 00008: val_loss did not improve
12626/12626 [==============================]12626/12626 [==============================] - 15s 1ms/step - loss: 338.4380 - val_loss: 435.1508
Epoch 9/10
12608/12626 [============================>.]12608/12626 [============================>.] - ETA: 0s - loss: 325.1715
Epoch 00009: val_loss improved from 384.65238 to 348.49219, saving model to /home/wumg/best_autopilot.hdf5
12626/12626 [==============================]12626/12626 [==============================] - 15s 1ms/step - loss: 325.0649 - val_loss: 348.4922
Epoch 10/10
12608/12626 [============================>.]12608/12626 [============================>.] - ETA: 0s - loss: 304.1439
Epoch 00010: val_loss did not improve
12626/12626 [==============================]12626/12626 [==============================] - 15s 1ms/step - loss: 304.2825 - val_loss: 349.3760
步骤6:评估性能
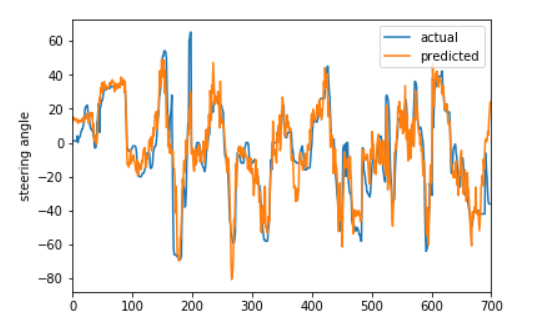
我们可以通过绘制预测值和实际值来检查我们的模型预测是否合理。第一个图表显示我们的测试数据中存在一个学习关系(在训练期间,部分测试数据我们的模型没有注意到)。
|
1 2 3 4 5 6 7 8 9 |
import pandas as pd model = load_model(model_path) test_P = model.predict(test_X) test_P = test_P.reshape((test_P.shape[0],)) df = pd.DataFrame({'predicted':test_P, 'actual':test_Y}) ax = df.plot.scatter('predicted', 'actual') |

第二张图,使用包含训练数据的非混洗(unshuffled)数据,来显示预测角度紧跟实际转向角度。
|
1 2 3 4 5 6 |
P = model.predict(X[:700]) #predict outputs nested arrays so we need to reshape to plot. P = P.reshape((P.shape[0],)) ax = pd.DataFrame({'predicted':P, 'actual':Y[:700]}).plot() ax.set_ylabel("steering angle") |
后续可进一步完善
改善模型,这个模型是纯粹(navie)的,因为它不使用过去的值来帮助预测未来。我们可以通过将过去的转向角度作为模型的输入来进行试验,添加一个递归层,或者只是改变卷积层的结构。
添加更多数据,随着我们添加更多驾驶数据,此模型将会得到改进。 预测油门,输出目前自动驾驶仪只能转向并保持恒定的速度。一个更复杂的模型将加速在直路上,并在路缘之前放缓。
Pingback引用通告: Python与人工智能 – 飞谷云人工智能