21.1 TensorFlow.js主要功能
TensorFlow.js是一个JavaScript库,它可以将机器学习功能添加到任何Web应用程序中。使用TensorFlow.js,可以从头开发机器学习脚本。你可以使用API在浏览器或Node.js服务器应用程序中构建和训练模型。并且,你可以使用TensorFlow.js在JavaScript环境中运行现有模型。
甚至,你可以使用TensorFlow.js用自己的数据再训练预先存在的机器学习模型,这些其中包括浏览器中客户端可用的数据。例如,你可以使用网络摄像头中的图像数据。如果你是一名机器学习、深度学习爱好者,那么TensorFlow.js是学习的好方法!
TensorFlow.js利用 WebGL 来进行加速的机器学习类库,它基于浏览器,提供了高层次的 JavaScript API 接口。它将高性能机器学习构建块带到您的指尖,使您能够在浏览器中训练神经网络或在推理模式下运行预先训练的模型。
TensorFlow.js的主要功能包括:利用用js开发机器学习、运行已有模型、重新训练已有模型等,具体请看下图:

有关安装/配置 TensorFlow.js 的指南,请参阅:https://js.tensorflow.org/index.html#getting-started。
21.2 安装Node.js和NPM
Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境。Node.js 使用了一个事件驱动、非阻塞式 I/O 的模型,使其轻量又高效。 Node.js 的使用包管理器 npm来管理所有模块的安装、配置、删除等操作,使用起来非常方便。但是想要配置好npm的使用环境还是稍微有点复杂,下面跟着我一起来学习在windows系统上配置NodeJS和NPM吧。
具体安装大家可参考:
https://jingyan.baidu.com/article/48b37f8dd141b41a646488bc.html
21.3 Javascript(js)简介
1.JavaScript历史
要了解JavaScript,我们首先要回顾一下JavaScript的诞生。
在上个世纪的1995年,当时的网景公司正凭借其Navigator浏览器成为Web时代开启时最著名的第一代互联网公司。
由于网景公司希望能在静态HTML页面上添加一些动态效果,于是叫Brendan Eich这哥们在两周之内设计出了JavaScript语言。你没看错,这哥们只用了10天时间。
为什么起名叫JavaScript?原因是当时Java语言非常红火,所以网景公司希望借Java的名气来推广,但事实上JavaScript除了语法上有点像Java,其他部分基本上没啥关系。
2.ECMAScript
因为网景开发了JavaScript,一年后微软又模仿JavaScript开发了JScript,为了让JavaScript成为全球标准,几个公司联合ECMA(European Computer Manufacturers Association)组织定制了JavaScript语言的标准,被称为ECMAScript标准。
所以简单说来就是,ECMAScript是一种语言标准,而JavaScript是网景公司对ECMAScript标准的一种实现。
那为什么不直接把JavaScript定为标准呢?因为JavaScript是网景的注册商标。
不过大多数时候,我们还是用JavaScript这个词。如果你遇到ECMAScript这个词,简单把它替换为JavaScript就行了。
3.JavaScript版本
JavaScript的标准——ECMAScript在不断发展,最新版ECMAScript 6标准(简称ES6)已经在2015年6月正式发布了,所以,讲到JavaScript的版本,实际上就是说它实现了ECMAScript标准的哪个版本。想更详细了解JavaScript,大家可参考:
http://www.runoob.com/js/js-howto.html
21.4 TensorFlow.JS基础
21.4.1 主要概念
TensorFlow.js的主要概念,包括张量(Tensor)、变量(Variables)、操作(operations)、模型和层(models and layers)等,如下图所示。
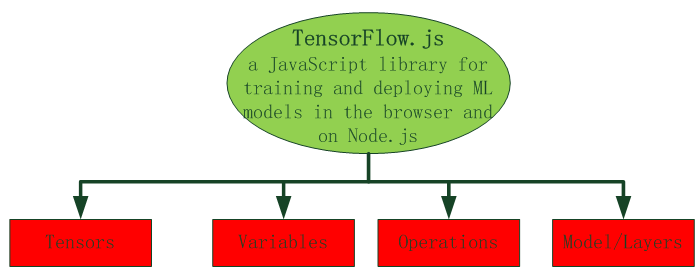
21.4.2 张量
张量(Tensor)是TensorFlow中的主要数据单位。张量包含一组数值,可以是任何形状:一维或多维。当你创建新的张量时,你还需要定义形状(shape)。你可以通过使用tensor函数并传入第二个参数来定义形状,如下所示:
|
1 |
const t1 = tf.tensor([1,2,3,4,2,4,6,8]), [2,4]); |
这是定义具有两行四列形状的张量。产生的张量如下所示
|
1 2 |
[[1,2,3,4], [2,4,6,8]] |
也可以让TensorFlow推断出张量的形状,如下列代码。
|
1 |
const t2 = tf.tensor([[1,2,3,4],[2,4,6,8]]); |
我们可以使用input.shape来检索张量的大小。
|
1 |
const tensor_s = tf.tensor([2,2]).shape; |
这里的形状为[2]。我们还可以创建具有特定大小的张量。例如,下面我们创建一个形状为[2,2]的零值张量。
|
1 |
const t_zeros = tf.zeros([2,3]); |
这行代码创建了以下张量
[[0,0,0],
[0,0,0]]
此外,你可以使用以下函数来增强代码可读性:
tf.scalar:只有一个值的张量
tf.tensor1d:具有一个维度的张量
tf.tensor2d:具有两个维度的张量
tf.tensor3d:具有三维的张量
tf.tensor4d:具有四个维度的张量,
下图为常见的几种张量示意图:
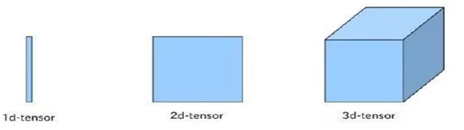
如表示标量:
|
1 |
const tensor = tf.scalar(2); |
如表示二维张量:
|
1 2 3 4 |
const c = tf.tensor2d([[1.0, 2.0, 3.0], [10.0, 20.0, 30.0]]); c.print(); // Output: [[1 , 2 , 3 ], // [10, 20, 30]] |
在TensorFlow.js中,所有张量都是不可变的。这意味着张量一旦创建,之后就无法改变。如果你执行一个更改量值的操作,总是会创建一个新的张量并返回结果值。
21.4.3 变量
张量(Tensors) 是不可变的,一旦创建,不能改变其值;而变量(variables) 则可以动态改变其值,主要用于在模型训练期间存储和更新值。您可以使用assign方法为现有变量指定新值:
|
1 2 3 4 5 6 7 |
const initialValues = tf.zeros([5]); const biases = tf.variable(initialValues); // initialize biases biases.print(); // output: [0, 0, 0, 0, 0] const updatedValues = tf.tensor1d([0, 1, 0, 1, 0]); biases.assign(updatedValues); // update values of biases biases.print(); // output: [0, 1, 0, 1, 0] |
变量主要用于在模型训练期间存储然后更新参数值。
21.4.4 操作
通过使用TensorFlow操作,你可以操纵张量的数据。由于张量运算的不变性,结果值总是返回一个新的张量。
TensorFlow.js提供了许多有用的操作,如square,add,sub和mul。你可以直接应用操作,如下所示:。
|
1 2 |
const t3 = tf.tensor2d([1,2], [3, 4]); const t3_squared = t3.square(); |
执行此代码后,新张量包含以下值:
[[1, 4 ],
[9, 16]]
21.4.5 内存管理
由于TensorFlow.js使用GPU来加速数学运算,因此在使用张量和变量时需要管理GPU内存。
TensorFlow.js提供了两个函数来帮助解决这个问题:dispose和tf.tidy。
dispose
我们可以在张量或变量上调用dispose来清除它并释放其GPU内存:
|
1 2 3 4 5 |
const x = tf.tensor2d([[0.0, 2.0], [4.0, 6.0]]); const x_squared = x.square(); x.dispose(); x_squared.dispose(); |
在进行大量张量操作时,使用dispose会很麻烦。 TensorFlow.js提供了另一个函数tf.tidy,它与JavaScript中的常规作用域起着类似的作用,但是对于GPU支持的张量。
tf.tidy执行一个函数并清除所创建的任何中间张量,释放它们的GPU内存。 它不会清除内部函数的返回值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
// tf.tidy takes a function to tidy up after const average = tf.tidy(() => { // tf.tidy will clean up all the GPU memory used by tensors inside // this function, other than the tensor that is returned. // // Even in a short sequence of operations like the one below, a number // of intermediate tensors get created. So it is a good practice to // put your math ops in a tidy! const y = tf.tensor1d([1.0, 2.0, 3.0, 4.0]); const z = tf.ones([4]); return y.sub(z).square().mean(); }); average.print() // Output: 3.5 |
使用tf.tidy将有助于防止应用程序中的内存泄漏。 它还可以用于更加谨慎地控制何时回收内存。
【注意】
传递给tf.tidy的函数应该是同步的,也不会返回Promise。 我们建议保留更新UI的代码或在tf.tidy之外发出远程请求。
tf.tidy不会清理变量。 变量通常持续到机器学习模型的整个生命周期,因此TensorFlow.js即使它们是在tf.tidy的情况下创建的,也不会清理它们。 但是,您可以手动调用dispose来清理。
21.4.6 模型和层
从概念上讲,模型是一种函数,给定一些输入将产生一些所需的输出。在TensorFlow.js中,有两种方法可以创建模型。 您可以直接使用ops来表示模型所做的事情。 例如:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
// Define function function predict(input) { // y = a * x ^ 2 + b * x + c // More on tf.tidy in the next section return tf.tidy(() => { const x = tf.scalar(input); const ax2 = a.mul(x.square()); const bx = b.mul(x); const y = ax2.add(bx).add(c); return y; }); } // Define constants: y = 2x^2 + 4x + 8 const a = tf.scalar(2); const b = tf.scalar(4); const c = tf.scalar(8); // Predict output for input of 2 const result = predict(2); result.print() // Output: 24 |
我们也可以使用高级API tf.model来构建层中的模型,这是深度学习中的流行方法。 以下代码构造了一个tf.sequential模型:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
const model = tf.sequential(); model.add( tf.layers.simpleRNN({ units: 20, recurrentInitializer: 'GlorotNormal', inputShape: [80, 4] }) ); const optimizer = tf.train.sgd(LEARNING_RATE); model.compile({optimizer, loss: 'categoricalCrossentropy'}); model.fit({x: data, y: labels}); |
其中units. 激活输出的数量。由于这是最后一层,这里涉及20个类别的分类任务。units的数据量指节点数。
TensorFlow.js中有许多不同类型的层。 如tf.layers.simpleRNN,tf.layers.gru和tf.layers.lstm等。
【注意】
利用TensorFlow.js构建网络时,第一层必须明确指定输入形状,其余的层默认从前面的层输入。如下示例代码:
(1)首先,用tf.sequential()实例化构建模型model
将使用Sequential模型(最简单的模型类型),其中张量将连续地从一层传递到下一层。
|
1 |
const model = tf.sequential(); |
(2)添加一个卷积层
|
1 2 3 4 5 6 7 8 |
model.add(tf.layers.conv2d({ inputShape: [28, 28, 1], kernelSize: 5, filters: 8, strides: 1, activation: 'relu', kernelInitializer: 'VarianceScaling' })); |
nputShape.将流入模型第一层的数据的形状。这里,我们的MNIST样本是28x28像素的黑白图像。图像数据的规范格式是[row,column,depth],所以我们在这里配置的形状是[28,28,1]——每个维度有28rowX28column个像素,而depth为1是因为我们的图像只有1个颜色通道。
kernelSize. 应用于输入数据的滑动卷积滤波器窗口的大小。在这里,我们设置kernelSize为5,它表示一个5x5的正方形卷积窗口。
filters. 应用于输入数据,大小为kernelSize的滤波器窗口的数量。在这里,我们将对数据应用8个过滤器。
strides. 滑动窗口的“步长” - 即每次在图像上移动时,滤波器将移动多少个像素。在这里,我们指定步幅为1,这意味着过滤器将以1像素为单位滑过图像。
activation.卷积完成后应用于数据的 激活函数。这里,我们使用了 Rectified Linear Unit (ReLU)函数,这是ML模型中非常常见的激活函数。
kernelInitializer. 用于随机初始化模型权重的方法,这对于训练动态是非常重要的。我们不会详细介绍初始化的细节,这里VarianceScaling是一个很不错的初始化器。
(2)添加一个池化层
|
1 2 3 4 |
model.add(tf.layers.maxPooling2d({ poolSize: [2, 2], strides: [2, 2] })); |
poolSize. 应用于输入数据的滑动窗口大小。在这里,我们设置poolSize为[2,2],这意味着池化层将对输入数据应用2x2窗口。
stride. 滑动窗口的“步长” - 即每次在输入数据上移动时,窗口将移动多少个像素。在这里,我们指定[2,2]的步长,这意味着滤波器将在水平和垂直两个方向上以2个像素为单位滑过图像。
【注意】
由于poolSize和strides都是2×2,所以池窗口将完全不重叠。这意味着池化层会将前一层的激活图的大小减半。
(3)再添加一个卷积层
重复使用层结构是神经网络中的常见模式。我们添加第二个卷积层到模型,并在其后添加池化层。请注意,在我们的第二个卷积层中,我们将滤波器数量从8增加到16。还要注意,我们没有指定inputShape,因为它可以从前一层的输出形状中推断出来。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
model.add(tf.layers.conv2d({ kernelSize: 5, filters: 16, strides: 1, activation: 'relu', kernelInitializer: 'VarianceScaling' })); model.add(tf.layers.maxPooling2d({ poolSize: [2, 2], strides: [2, 2] })); |
(4)添加一个展平层
我们添加一个 flatten层,将前一层的输出平铺到一个向量中。
|
1 |
model.add(tf.layers.flatten()); |
【注意】
展平层,既没有说明输入形状,也没有说明输出形状,这些形状都是从前层输出自动获取。
(5)输出层
最后,让我们添加一个 dense层(也称为全连接层),它将执行最终的分类。 在dense层前先对卷积+池化层的输出执行flatten也是神经网络中的另一种常见模式
|
1 2 3 4 5 |
model.add(tf.layers.dense({ units: 10, kernelInitializer: 'VarianceScaling', activation: 'softmax' })); |
units. 激活输出的数量。由于这是最后一层,我们正在做10个类别的分类任务(数字0-9),因此我们在这里使用10个units。 (有时units被称为神经元的数量)
kernelInitializer. 我们将对dense层使用与卷积层相同的VarianceScaling初始化策略。
activation. 分类任务的最后一层的激活函数通常是 softmax。 Softmax将我们的10维输出向量归一化为概率分布,使得我们10个类中的每个都有一个概率值。
21.4.7 优化问题
这一部分,我们将学习如何解决优化问题。给定函数f(x),我们要求求得x=a使得f(x)最小化。为此,我们需要一个优化器。优化器是一种沿着梯度来最小化函数的算法。文献中有许多优化器,如SGD,Adam等等,这些优化器的速度和准确性各不相同。Tensorflowjs支持大多数重要的优化器。
我们将举一个简单的例子:f(x)=x⁶+2x⁴+3x²+x+1。函数的曲线图如下所示。可以看到函数的最小值在区间[-0.5,0]。我们将使用优化器来找出确切的值。
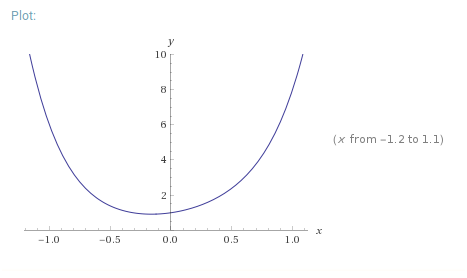
首先,我们定义要最小化的函数:
|
1 2 3 4 5 6 7 8 |
function f(x) { const f1 = x.pow(tf.scalar(6, 'int32')) //x^6 const f2 = x.pow(tf.scalar(4, 'int32')).mul(tf.scalar(2)) //2x^4 const f3 = x.pow(tf.scalar(2, 'int32')).mul(tf.scalar(3)) //3x^2 const f4 = tf.scalar(1) //1 return f1.add(f2).add(f3).add(x).add(f4) } |
现在我们可以迭代地最小化函数以找到最小值。我们将以a=2的初始值开始,学习率定义了达到最小值的速度。我们将使用Adam优化器:
|
1 2 3 4 5 6 7 |
function minimize(epochs, lr) { let y = tf.variable(tf.scalar(2)) //初始化,值为2 const optim = tf.train.adam(lr); //采用自适应优化器adam for(let i = 0 ; i < epochs ; i++) //开始优化 optim.minimize(() => f(y)); return y } |
使用值为0.9的学习速率,我们发现200次迭代后的最小值对应的y为-0.16092407703399658。
更多内容可参考:
https://js.tensorflow.org/tutorials/core-concepts.html
21.5设置项目(使用npm)
(1)在第一步中,我们需要设置项目。创建一个新的空目录。
|
1 |
$ mkdir tfjs01 |
(2)切换到新创建的项目文件夹
|
1 |
$ cd tfjs01 |
以下操作,都在该文件夹下
(3)创建一个package.json文件
在文件夹中,我们现在准备创建一个package.json文件,以便我们能够通过使用Node.js包管理器来管理依赖项:
|
1 |
$ npm init -y |
(4)安装Parcel捆绑器
因为我们将在项目文件夹中本地安装依赖项(例如Tensorflow.js库),所以我们需要为Web应用程序使用模块捆绑器(bundler)。为了尽可能简单,我们将使用Parcel Web应用程序捆绑器,因为Parcel不需要进行配置。让我们通过在项目目录中执行以下命令来安装Parcel捆绑器:
|
1 |
$ npm install -g parcel-bundler |
(5)创建两个空文件
接下来,让我们为我们的实现创建两个新的空文件:
|
1 |
$ touch index.html index.js |
(6)安装Bootstrap库
我们将Bootstrap库添加为依赖项,因为我们将为我们的用户界面元素使用一些Bootstrap CSS类:
|
1 |
$ npm install bootstrap |
(7)修改两个空文件
在index.html中,让我们插入以下基本html页面的代码:
|
1 2 3 4 5 6 7 8 9 10 |
<html> <body> <div class="container"> <b>Welcome to TensorFlow.js</b> <div id="output"></div> </div> <script src="./index.js"></script> </body> </html> |
另外,将以下代码添加到index.js
|
1 2 3 |
import 'bootstrap/dist/css/bootstrap.css'; document.getElementById('output').innerText = "Hello World"; |
我们将文本Hello World写入具有ID输出的元素,以在屏幕上查看第一个结果并获得正确处理JS代码的确认。
(8)启动程序及web服务
最后,让我们通过使用parcel命令启动构建程序和开发的Web服务:
|
1 |
$ parcel index.html |
你现在应该可以在浏览器中通过URL http://localhost:1234打开网站。结果应与你在以下截图中看到的内容对应:
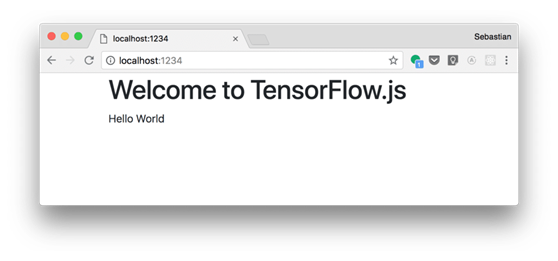
【注意】
以上步骤我们也可用yarn执行,npm与yarn的对应关系及优缺点,可参考:
https://juejin.im/entry/5a73ca7d6fb9a063435ea9ad
http://www.fly63.com/article/detial/554
21.6设置项目(使用yarn)
(1)在第一步中,我们需要设置项目。创建一个新的空目录。
|
1 |
$ mkdir tfjs02 |
(2)切换到新创建的项目文件夹
|
1 |
$ cd tfjs02 |
以下操作,都在该文件夹下
(3)创建一个package.json文件
在文件夹中,我们现在准备创建一个package.json文件,以便我们能够通过使用Node.js包管理器来管理依赖项:
|
1 |
$ yarn init -y |
(4)安装Parcel捆绑器
Parcel 是一个 web 应用打包工具, 与其他工具的区别在于开发者的使用体验。它利用多核处理器提供了极快的速度, 并且不需要任何配置。
因为我们将在项目文件夹中本地安装依赖项(例如Tensorflow.js库),所以我们需要为Web应用程序使用模块捆绑器(bundler)。为了尽可能简单,我们将使用Parcel Web应用程序捆绑器,因为Parcel不需要进行配置。让我们通过在项目目录中执行以下命令来安装Parcel捆绑器:
|
1 |
$ yarn global add parcel-bundler |
(5)创建两个空文件
接下来,让我们为我们的实现创建两个新的空文件:
|
1 |
$ touch index.html index.js |
(6)安装Bootstrap库
我们将Bootstrap库添加为依赖项,因为我们将为我们的用户界面元素使用一些Bootstrap CSS类:
|
1 |
$ yarn add bootstrap |
将生成一个文件(yarn.lock)和一个文件夹(node_modules)
(7)修改两个空文件
在index.html中,让我们插入以下基本html页面的代码:
|
1 2 3 4 5 6 7 8 9 10 |
<html> <body> <div class="container"> Welcome to TensorFlow.js <div id="output"></div> </div> <script src="./index.js"></script> </body> </html> |
另外,将以下代码添加到index.js
|
1 2 |
import 'bootstrap/dist/css/bootstrap.css'; document.getElementById('output').innerText = "Hello World"; |
我们将文本Hello World写入具有ID输出的元素,以在屏幕上查看第一个结果并获得正确处理JS代码的确认。
(8)启动程序及web服务
最后,让我们通过使用parcel命令启动构建程序和开发的Web服务:
|
1 |
$ parcel index.html |
执行该命令,将生成一个dist文件夹,同时更新相关文件。
你现在应该可以在浏览器中通过URL http://localhost:1234打开网站。当文件改变时它仍然会自动重建并支持热替换。结果应与你在以下截图中看到的内容对应:
【说明】
21.7实例详解
本实例利用tensorflow.js定义一个模型,该模型模拟一条直线(y=2x-1),然后,根据训练好的模型,在浏览器上,输入一个值,实时预测值,新体验,很不错哦!
(1)添加ensorflow.js
为了Tensorflow.js添加到项目中,我们再次使用NPM并在项目目录中执行以下命令
|
1 |
$ npm install @tensorflow/tfjs |
这将下载并将其安装到node_modules文件夹中。成功执行此命令后,我们现在可以通过在文件顶部添加以下import语句来导入index.js中的Tensorflow.js库:
|
1 |
import * as tf from '@tensorflow/tfjs'; |
当我们将TensorFlow.js导入为tf后,我们就可以通过在代码中使用tf对象来访问TensorFlow.js API。
(2)定义模型
现在TensorFlow.js已经可用,让我们从一个简单的机器学习练习开始。下面的示例应用程序涵盖的机器学习脚本是公式Y = 2X-1,这是个线性回归。
此函数返回给定X对应的Y值。如果绘制点(X,Y),你将得到一条直线,如下所示:
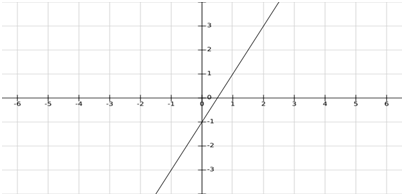
接下来我们将使用来自该函数的输入数据(X,Y)并使用这些数字训练模型。然后使用训练好的模型,根据新的X值来预测Y值。期望从模型返回的Y结果接近函数返回的精确值。
让我们创建一个非常简单的神经网络来实现。此模型只需处理一个输入值和一个输出值:
|
1 2 3 |
// Define a machine learning model for linear regression const model = tf.sequential(); model.add(tf.layers.dense({units: 1, inputShape: [1]})); |
首先,我们通过调用tf.sequential方法创建一个新的模型实例。得到一个新的序列模型。其中一层的输出是下一层的输入,即模型是层的简单“堆叠”,没有分支或跳过。
创建好模型后,我们准备通过调用model.add来添加第一层。通过调用tf.layers.dense将新层传递给add方法。这会创建一个稠密层或全连接层。在稠密层中,层中的每个节点都连接到前一层中的每个节点。对于我们的示例,只需向神经网络添加一个具有一个输入和输出形状的密集层就足够了。
在下一步中,我们需要为模型指定损失函数和优化函数。
|
1 2 |
// Specify loss and optimizer for model model.compile({loss: 'meanSquaredError', optimizer: 'sgd'}); |
通过将配置对象传递给模型实例的编译方法来完成。配置对象包含两个属性:
loss:这里我们使用meanSquaredError损失函数。通常,损失函数用于将一个或多个变量的值映射到表示与该值相关联的一些“损失”的实数上。如果训练模型,它会尝试最小化损失函数的结果。估计量的均方误差是误差平方的平均值 - 即估计值与估计值之间的平均平方差。
optimizer:要使用的优化器函数。我们的线性回归机器学习任务使用的是sgd函数。Sgd代表Stochastic Gradient Descent,它是一个适用于线性回归任务的优化器函数。
现在模型已配置完成,接下来将训练模型。
(3)训练模型
为了用函数Y=2X-1的值训练模型,我们定义了两个形状为6,1的张量。第一张量xs包含x值,第二张量ys包含相应的y值:
|
1 2 3 |
// Prepare training data const xs = tf.tensor2d([-1, 0, 1, 2, 3, 4], [6, 1]); const ys = tf.tensor2d([-3, -1, 1, 3, 5, 7], [6, 1]) |
把这两个张量传递给调用的model.fit方法来训练模型
|
1 2 |
// Train the model model.fit(xs, ys, {epochs: 500}).then(() => {}); |
对于第三个参数,我们传递一个对象,该对象包含一个名为epochs的属性,该属性设置为值500。此处指定的数字是指定TensorFlow.js通过训练集的次数。
fit方法的结果是一个Promise,所以我们注册一个回调函数,该函数在训练结束时被激活。
(4)预测
现在让我们在这个回调函数中执行最后一步,并根据给定的x值预测y值
|
1 2 3 4 5 |
// Train the model model.fit(xs, ys, {epochs: 500}).then(() => { // Use model to predict values model.predict(tf.tensor2d([5], [1,1])).print(); }); |
使用model.predict方法完成预测。该方法以张量的形式接收输入值作为参数。在这个特定情况下,我们在内部创建一个只有一个值(5)的张量并将其传递给预测。通过调用print函数,我们确保将结果值打印到控制台,如下所示:
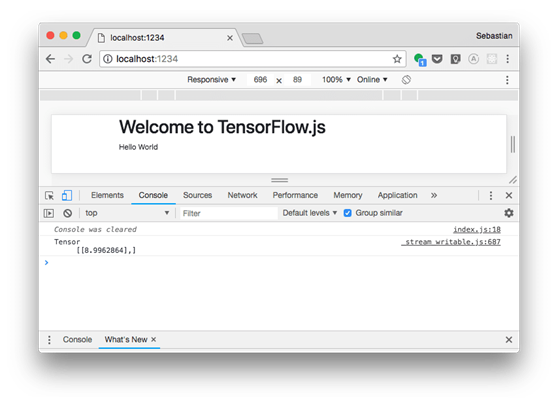
输出显示预测值为8.9962864并且非常接近9(如果x设置为5,函数Y=2X-1的Y值为9)
(5)优化界面
已上面经实现的示例是使用固定输入值进行预测(5)并将结果输出到浏览器控制台。让我们引入一个更复杂的用户界面,让用户能够输入用于预测的值。在index.html中添加以下代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
<html> <body> <div class="container" style="padding-top: 20px"> <div class="card"> <div class="card-header"> <strong>使用TensorFlow.js简单示例 - 线性回归</strong> </div> <div class="card-body"> <label>输入值:</label> <input type="text" id="inputValue" class="form-control"><br> <button type="button" class="btn btn-primary" id="predictButton" disabled>正在训练模型, 请稍等 ...</button><br><br> 预测结果: </span> <span class="badge badge-secondary" id="output"></span> </div> </div> </div> <script src="./index.js"></script> </body> </html> |
这里我们使用各种Bootstrap CSS类,向页面添加输入和按钮元素,并定义用于输出结果的区域。
我们还需要在index.js中做一些更改:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import * as tf from '@tensorflow/tfjs'; import 'bootstrap/dist/css/bootstrap.css'; // Define a machine learning model for linear regression const model = tf.sequential(); model.add(tf.layers.dense({units: 1, inputShape: [1]})); // Specify loss and optimizer for model model.compile({loss: 'meanSquaredError', optimizer: 'sgd'}); // Prepare training data const xs = tf.tensor2d([-1, 0, 1, 2, 3, 4], [6, 1]); const ys = tf.tensor2d([-3, -1, 1, 3, 5, 7], [6,1]); // Train the model and set predict button to active model.fit(xs, ys, {epochs: 500}).then(() => { // Use model to predict values document.getElementById('predictButton').disabled = false; document.getElementById('predictButton').innerText = "Predict"; }); // Register click event handler for predict button document.getElementById('predictButton').addEventListener('click', (el, ev) => { let val = document.getElementById('inputValue').value; let val_num = Number(val); document.getElementById('output').innerText = model.predict(tf.tensor2d([val_num], [1,1])); }); |
注册了预测按钮的click事件的事件处理程序。在此函数内部,读取input元素的值(通过number函数把输入值转换为数据类型)并调用model.predict方法。此方法返回的结果将插入具有id输出的元素中。
现在的结果应该如下所示:
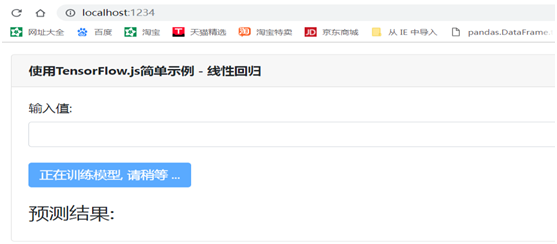
现在我们根据训练好的模型,输入值(x),就可实时预测Y值了!。单击“ Predict ”按钮完成预测。结果会直接显示在网站上。
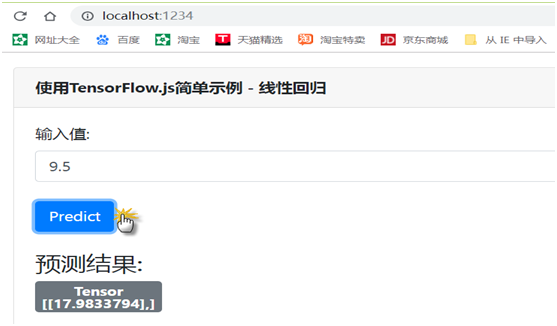
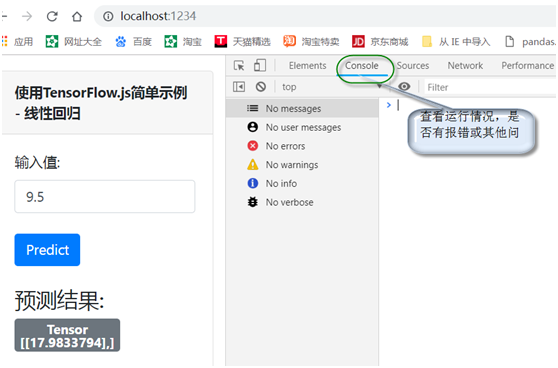
(6)查看运行情况
通过管理平台(console),查看运行情况。
参考文档:
https://js.tensorflow.org/
https://cloud.tencent.com/developer/article/1346798