1 分类特征传统处理方法
分类(Categorical)特征常被称为离散特征、分类特征,数据类型通常是object类型,而机器学习模型通常只能处理数值数据,所以需要对Categorical数据转换成Numeric特征。
Categorical特征又有两类,我们需要理解它们的具体含义并进行对应的转换。
(1)有序(Ordinal)类型:
这种类型的Categorical存在着自然的顺序结构,如果你对Ordinal 类型数据进行排序的话,可以是增序或者降序,比如在衣服型号这个特征中具体的值可能有:S、M、L、XL等衣服尺码,其中S:(Small)表示小 ,M(Middle)表示中 ,L(Large)表示大,XL(extra large)表示加大尺码,它们之间有XL>L>M>S的大小关系。
(2)常规(Nominal)类型或无序类型:
这种是常规的Categorical类型,不能对Nominal类型数据进行排序,这类特征无谁大谁小之分。比如颜色特征可能的值有:red、yellow、blue、black等,我们不能说red>yellow>blue>black。
对于Ordinal和Nominal类型数据有不同的方法将它们转换成数字。
1.1 处理有序类型
对于Ordinal类型数据可以使用OrdinalEncoder、LabelEncoder进行编码处理,功能相同,都将每一个类别的特征转换成一个新的整数(0到类别数n-1之间)。例如S、M、L、XL等衣服尺码这四个类别进行OrdinalEncoder(或LabelEncoder)处理后会映射成0、1、2、3,这样数据间的自然大小关系也会保留下来。以下数据集data_set共有4列,这4列从左到右分别表示型号、颜色、性别、标签。其中型号为有序类别,其它都是常规类别。这些都是字符,现在利用sklearn中预处理模块preprocessing,把型号转换为数字,具体代码如下:
(1)导入数据
|
1 2 3 4 5 6 |
from sklearn.preprocessing import OrdinalEncoder,LabelEncoder,OneHotEncoder import numpy as np import numpy as np data_set=np.array([['L','red','Female','yes'],['M','red','Male','no'],['M','yellow','Female','yes'],['XL','blue','Male','no']]) |
data_set的结果如下
array([['L', 'red', 'Female', 'yes'],
['M', 'red', 'Male', 'no'],
['M', 'yellow', 'Female', 'yes'],
['XL', 'blue', 'Male', 'no']], dtype='<U6')
(2)进行转换
|
1 2 3 4 5 6 |
x1 = data_set[:,0] #获取第1列数据 x1=x1.reshape(-1,1) #转换为2D,transform传递的X一定要是2D的,即 #(samples,features) oe = OrdinalEncoder() #实例化 ord=oe.fit(x1) #导入数据 oe.transform(x1) #转换后的数据为:array([[0],[1],[1],[]2]) oe.categories_ #属性.categories_查看类别特征究竟有多少类别 |
1.2 处理常规类型
1.1节用OrdinalEncoder、OrdinalEncoder把分类变量型号转换为数字,同样可以把颜色、性别、标签等这些属于常规类型的特征转换为整数(0到类别数n-1之间)。具体代码如下:
1.2.1 把标签转换为数字
使用LabelEncoder把标签特征转换为数字。
|
1 2 3 4 5 |
y = data_set[:,-1] #获取最后一列数据 le = LabelEncoder() #实例化 le.fit_transform(y) #也可以直接fit_transform一步到位 le.classes_ #属性.classes_查看标签中究竟有多少类别['no', 'yes'] label #查看获取的结果label[1, 0, 1, 0] |
1.2.2 把颜色、性别转换为数字
|
1 2 3 4 |
x2 = data_set[:,1:-1] #获取第2、3列数据 oe = OrdinalEncoder() #实例化 ord=oe.fit_transform(x2) #导入数据并进行转换 print(ord) |
运行结果如下:
[[1. 0.]
[1. 1.]
[2. 0.]
[0. 1.]]
在表示颜色这一列中,我们使用[0,1,2]代表了三个不同的颜色,然而这种转换是正确的吗?[0,1,2]这三个数字在算法看来,是连续且可以计算的,这三个数字相互不等,有大小,甚至有着可以相加相乘的联系。所以算法会把颜色,性别这样的常规分类特征,都误会成是有序特征这样的分类特征,把本来互相平等、独立的颜色特征误认为有大小的区分,如blue>yellow>red,blue的重要性是yellow颜色的2倍,这显然是不合理的。因此,我们把分类转换成数字的时候,忽略了数字中自带的数学性质,所以给算法传达了一些不准确的信息,而这会影响我们的建模。如何解决这个问题?
对于Nominal类型数据可以使用OneHotEncoder进行编码处理,尽量向算法传达最准确的信息。
1.2.3 使用OneHotEncoder方法
对于常规类别特征采用独热编码(One-Hot)方式处理,可以保证特征的基本属性,向算法专递最准确的信息。one-hot如何做到这点的呢?首先我们来了解一下one-hot编码的原理。
独热编码会为每个离散值创建一个哑特征(dummy feature)。什么是哑特征呢?举例来说,对于‘颜色’这一特征中的‘blue’,我们将其编码为[blue=1,yellow=0,red=0],同理,对于‘yellow’,我们将其编码为[blue=0,yellow=1,red=0],特点就是向量只有一个1,其余均为0,故称之为one-hot。即把颜色特征转换成如下表示:
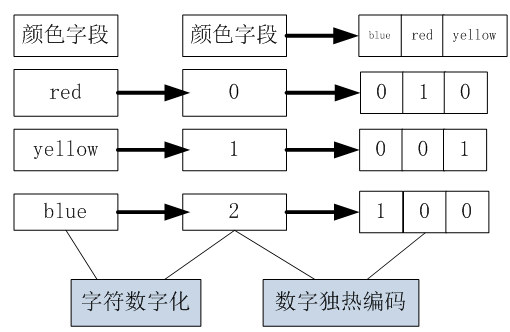
图1-1 one-hot编码示意图
从图1-1可知,独热编码进行了如下转换:
①把字符类型转换为数字类型。
②把一个字段(颜色字段)变成3个字段(字段个数为颜色的类别总数)
③对新创建的3个字段,颜色对应位置的值置为1,其它2列位置的都是0。
这么做的目的是为了保证每一个离散取值的“无序性、公平性、彼此正交性”。
下面我们用代码实现颜色和性别字段的one-hot转换。
(1)把字符转换为数字
|
1 2 3 4 |
x2 = data_set[:,1:-1] #获取第2、3列数据 oe=OrdinalEncoder() #实例化 x2=oe.fit_transform(x2) #先把字符转换为数字型 print(x2) |
打印结果如下:
[[1. 0.]
[1. 1.]
[2. 0.]
[0. 1.]]
(2)把数字转换为独热编码
|
1 2 3 |
oh = OneHotEncoder(categories='auto') #实例化 x3=oh.fit_transform(x2).toarray() #导入数据并进行转换 print(x3) |
打印结果如下:
[[0. 1. 0. 1. 0.]
[0. 1. 0. 0. 1.]
[0. 0. 1. 1. 0.]
[1. 0. 0. 0. 1.]]
前3列为颜色,后2列为性别。
【说明】OneHotEncoder是sklearn方法,pandas有一个对于方法,即get_dummies,它可直接把字符转换为oneHot编码。具体使用可参考如下博客:
https://blog.csdn.net/maymay_/article/details/80198468
对于Nominal类型数据可以使用独热编码(OneHotEncoder)有其合理的一面,但也有很多不足,如当遇到大数据,一个特征的类别很多几百,甚至几千或更多,而且这样的特征还有很多,如此一来,把这些特征转换成one-hot编码后,特征数将非常巨大!此外,这种方法只是简单把类别数据转换成0或1,无法准确反应这些特征内容隐含的一些规则或这些类别的分布信息,如一个表示地址的特征,可能包括北京、上海、杭州、美国纽约、华盛顿、洛杉矶,东京、大阪等等,这些属性具有一定分布特性,北京、上海、杭州之间的距离较近,而上海与纽约之间的距离应该比较远,诸如此类问题,one-hot是无法表示的。
是否有更有好、更有效的处理方法呢?有,就是接下来将介绍的Learned Embedding方法。
2 使用Embendding方法处理分类特征
2.1传统处理方法的不足
(1)无法真是反应特征的含义
如果仅仅把分类特征转换为数字,可能将无序变成有序,有序的变成可运算(如把M,X,XL转变为0、1、2,那么1+1=2,即X+X=XL,这显然不合逻辑)。
(2)容易导致维度暴增
如果把分类特征转换为one-hot编码,虽然可以使常规分类特征表现更公平、独立,但极易导致维度暴增。如比如阿里上的商品维度就至少是千万量级的,而且这样的商品很多,如果采用one-hot编码,则维度马上变成亿级以上。如果处理语言,词汇量更是几千、几万。除了维度暴增,还导致矩阵的极端稀疏,而太过稀疏数据不利于在机器学习或深度学习中提升性能或增强其泛化能力的。
(3)无法揭示特征内部的规则
很多商品、地址、词汇分类特征,其内容往往包含很多规则,如商品之间的层次关系、地址之间的依赖关系、词汇之间的相似性等,无法通过简单数字化来表达。
2.2 Embedding方法简介
近几年,从计算机视觉到自然语言处理再到时间序列预测,神经网络、深度学习的应用越来越广泛。在深度学习的应用过程中,Embedding 这样一种将离散变量转变为连续向量的方式为传统机器学习、神经网络在各方面的应用带来了极大的扩展。该技术目前主要有两种应用,NLP 中常用的Word Embedding以及用于类别数据的Entity Embedding。
简单来说,Embedding就是用一个低维的向量表示一个事物,可以是一个词、一个类别特征(如商品,电影、物品等)或时间序列特征等。这个Embedding向量通过学习可更准确的表示对应特征的内在含义,使距离相近的向量对应的物体有相近的含义,如图1-2所示
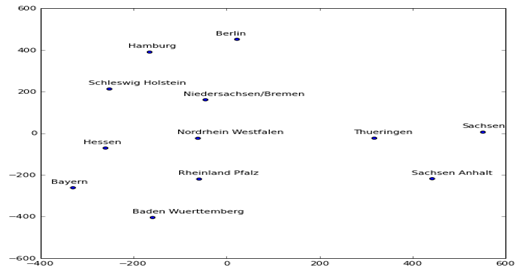
图1-2 可视化销售地址的Embedding
图1-2 是一个有关销售地址的Embedding图形,这是通过神经网络不断学习,得到有关销售地址的Embedding向量,具体代码实现方法后续将介绍。
Embedding往往放在神经网络的第一层,Embedding层可以训练过程不断更新,可以学习到对应特征的内在关系,含Embedding的网络结构可参考图1-3,所以Embedding有时又称为Learned Embedding。一个模型学习到的learned Embedding,也可以被其他模型重用。
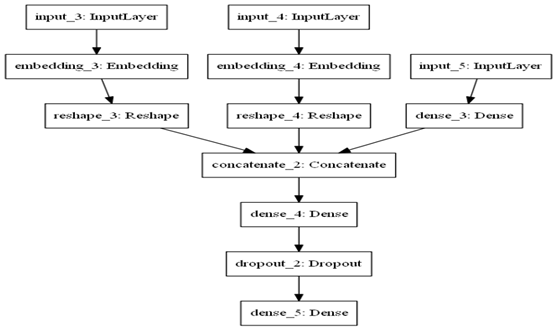
图1-3 含Embedding层的神经网络结构图
图1-3把两个分类特征(input_3,input_4)转换为Embedding后,与连续性输入特征(input_5)合并在一起,然后,连接全连接层等。在训练过程中,Embedding向量不断更新。
Embedding的灵感来自Word2Vec,但与Word2Vec有些不同,Word2Vec是google于2013年开源的一个计算词向量的工具。
目前各大深度学习平台都提供了Embedding层:
PyTorch1+的Embedding层是:
torch.nn.Embedding(m,n),
TensorFlow2+的Embedding层为:
tf.layers.Embedding(vocab_size, embedding_dim, input_length=maxlen),
keras的是:
keras.layers.Embedding(input_dim, output_dim, embeddings_initializer='uniform', embeddings_regularizer=None, activity_regularizer=None, embeddings_constraint=None, mask_zero=False, input_length=None)
2.3 Embedding的拓展
近些年Embedding发展很快,可以说很多内容都可表示为Embedding,从最初的word2vec到类别特征可以表示为Embedding(又成为Entity Embedding),时间序列数据可以表示Sequnce Embedding,目前推荐系统经常使用的Item Embedding和User Embedding,和目前的研究热点之一的Graph Embedding等等。可以说万物都可Embedding,目前Embedding已成为深度学习的基本操作。
2.4 Embedding方法的巨大威力
(1)Embedding在各种比赛中取得名列前茅
在结构化数据上运用神经网络时,Entiry Embedding表现的很好。 例如,在Kaggle竞赛”预测出租车的距离问题”上获得第1名的解决方案,就是使用Entiry Embedding来处理每次乘坐的分类元数据(Alexandre de Brébisson,2015)。 同样,预测Rossmann药店销售任务的获得第3名的解决方案使用了比前两个方案更简单的方法: 使用简单的前馈神经网络, 再加上类别变量的Entity Embedding。它包括超过1000个类别的变量,如商店ID(Guo&Berkahn,2016),作者把比赛结果汇总在一篇论文中(Entity Embeddings of Categorical Variables),在论文作者使用Embedding对传统机器学习与神经网络进行纵向和横行的比较,结果如表1-1。
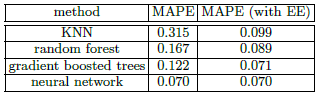
表1-1的结果对原打乱,然后取10%的测试数据。
从表1-1可以看出,如果不使用EE(Entity Embedding),神经网络的性能优于传统机器学习,如果使用EE,效果就更加明显。

表1-2 不打乱原数据,从最新的数据中取10%作为测试数据。
(2)Embedding是现代推荐系统中重要部分
微软的 Deep Crossing、Google 的 Wide&Deep 、YouTube深度学习推荐系统、阿里 DIN(2018 年)、华为 DeepFM系统、美团的推荐系统等等都把Embedding作为其重要组件。图1-4 为Google Wide&Deep(2016 年)的架构图。

图1-4 Google Wide&Deep架构图
3、小试牛刀:使用Embedding处理类别特征
本实例使用breast-cancer1数据集(下载),共有10列,其中前9列为分类特征,最后1列为标签,共有285行数据。
主要步骤如下:
(1)导入需要的模块
(2)定义导入数据的函数
首先,数据中含?的项替换为nan值,然后删除含nan的行。然后把前9列放入X,最后1列放入y
(3)先把类别特征数字化,然后在转换为长度都为10的Embedding向量
(4)合并这些Embedding向量
(5)构建模型,模型结构如1-5所示。
模型结构图1-5所示
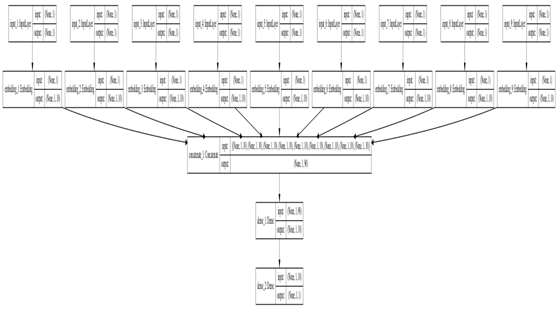
图1-5
(6)训练及评估模型
通过一般分类特征处理方法及使用传统机器学习该数据集能获得74%左右的精度,这里得到77%左右的精度。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 |
from numpy import unique from pandas import read_csv import numpy as np from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from tensorflow.keras.models import Model from tensorflow.keras.layers import Input from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Embedding from tensorflow.keras.layers import concatenate from tensorflow.keras.utils import plot_model #屏蔽警告信息 import warnings warnings.filterwarnings('ignore') # 定义导入数据函数 def load_dataset(filename): # load the dataset as a pandas DataFrame data = read_csv(filename, header=None) #删除含值为?的行 data = data.replace(to_replace='?',value=np.nan) data = data.dropna(how = 'any') # retrieve numpy array dataset = data.values # split into input (X) and output (y) variables X = dataset[:, :-1] y = dataset[:,-1] # format all fields as string X = X.astype(str) # 把标签数据转换为2D数据 y = y.reshape((len(y), 1)) return X, y # 先把各特征转换为数字 def prepare_inputs(X_train, X_test): X_train_enc, X_test_enc = list(), list() # label encode each column for i in range(X_train.shape[1]): le = LabelEncoder() le.fit(X_train[:, i]) # encode train_enc = le.transform(X_train[:, i]) test_enc = le.transform(X_test[:, i]) # store X_train_enc.append(train_enc) X_test_enc.append(test_enc) return X_train_enc, X_test_enc # 把标签列转换为数字 def prepare_targets(y_train, y_test): le = LabelEncoder() le.fit(y_train) y_train_enc = le.transform(y_train) y_test_enc = le.transform(y_test) return y_train_enc, y_test_enc # 加载数据 X, y = load_dataset(r'D:\python-script\py\data\breast-cancer1.csv') # 划分数据 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # prepare input data X_train_enc, X_test_enc = prepare_inputs(X_train, X_test) # prepare output data y_train_enc, y_test_enc = prepare_targets(y_train, y_test) # make output 3d y_train_enc = y_train_enc.reshape((len(y_train_enc), 1, 1)) y_test_enc = y_test_enc.reshape((len(y_test_enc), 1, 1)) # 把特征转换为长度为10的向量 in_layers = list() em_layers = list() for i in range(len(X_train_enc)): # calculate the number of unique inputs n_labels = len(unique(X_train_enc[i])) # define input layer in_layer = Input(shape=(1,)) # define embedding layer em_layer = Embedding(n_labels, 10)(in_layer) # store layers in_layers.append(in_layer) em_layers.append(em_layer) # 合并所用embedding向量 merge = concatenate(em_layers) dense = Dense(10, activation='relu', kernel_initializer='he_normal')(merge) output = Dense(1, activation='sigmoid')(dense) model = Model(inputs=in_layers, outputs=output) # compile the keras model model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 把模型保存到磁盘 plot_model(model, show_shapes=True, to_file='embeddings.png') # fit the keras model on the dataset model.fit(X_train_enc, y_train_enc, epochs=20, batch_size=16, verbose=2) # 评估模型 _, accuracy = model.evaluate(X_test_enc, y_test_enc, verbose=0) print('Accuracy: %.2f' % (accuracy*100)) |
运行结果如下:
Epoch 15/20
184/184 - 0s - loss: 0.4477 - accuracy: 0.7989
Epoch 16/20
184/184 - 0s - loss: 0.4399 - accuracy: 0.8152
Epoch 17/20
184/184 - 0s - loss: 0.4351 - accuracy: 0.8152
Epoch 18/20
184/184 - 0s - loss: 0.4305 - accuracy: 0.8043
Epoch 19/20
184/184 - 0s - loss: 0.4250 - accuracy: 0.8043
Epoch 20/20
184/184 - 0s - loss: 0.4212 - accuracy: 0.8043
Accuracy: 77.17