文章目录
6.1 概述
从2013 google推出最初的一种Word Embedding(即word2vec)后,其发展非常迅速,尤其近些年对Word Embedding的应用和拓展,取得了非常大的进步。
Embedding的起源,应该追溯到Word2Vec,Word2Vec是一种Word Embedding。由于Word Embedding克服了传统整数向量、One-Hot向量的耗资源、对语句表现能力差等不足,Word Embedding在最近几年发展和创新不断,从最初的Word Embedding,已发展成Sequence Embedding、catategorial data Embedding、Graph Embedding等等。应用也从当初的自然语言处理(NLP)到传统机器学习、自然语言处理、推荐系统、广告、搜索排序等领域,并大大提升了这些应用的性能。
Embedding尤其在NLP方面,近些年取得巨大进步。可以说是最近几年在NLP领域最大的突破就在Word Embedding方面。如将替换RNN\LSTM的Transformer或Transformer-XL,在很多下游复杂任务上已超越人类平均水平的BERT、XLNET模型等等。而这些算法或模型的应用开始在推荐、传统机器学习、视觉处理、NLP方面开始爆发!难怪有人说Embedding时代已来临!
以下我用图形这种简单明了的方式,简单介绍一下Embedding的历史及最近几年的突破性进展,希望能给大家进一步学习提供参考。
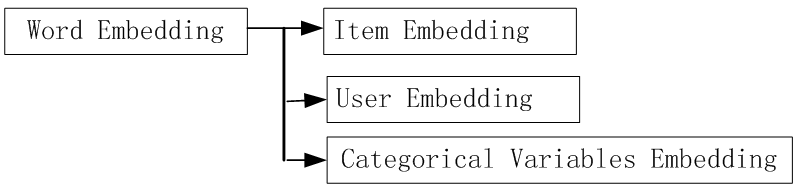
6.2Embedding在Entity领域的拓展
Entity Embedding是推荐系统、计算广告领域最近非常流行的做法,是从word2vec等一路发展而来的Embedding技术的最新延伸;
Entity Embedding中的Categorical Variable Embedding已成为贯通传统机器学习与深度学习的桥梁。
6.3 Embedding在NLP领域的最新进展
贪心学院2020-2-15至2020-2-22日5次公开课
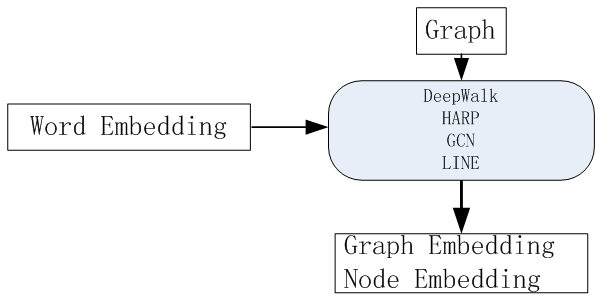
6.4 在Graph领域的拓展
Graph Embedding是推荐系统、计算广告领域最近非常流行的做法,是从word2vec等一路发展而来的Embedding技术的最新延伸;
Graph Embedding已经有很多大厂将Graph Embedding应用于实践后取得了非常不错的线上效果。
6.5 Embedding 应用到机器学习中
Embedding的起源和火爆都是在NLP中的,经典的word2vec都是在做word embedding这件事情,而真正首先在结构数据探索embedding的是在kaggle上的《Rossmann Store Sales》中的用简单特征工程取得第3名的解决方案(前两名为该领域的专业人士,采用了非常复杂的特征工程),作者在比赛完后为此方法整理一篇论文放在了arXiv,文章名:《Entity Embeddings of Categorical Variables》。
6.6Embedding在推荐领域的超级应用
1、[Item2Vec] Item2Vec-Neural Item Embedding for Collaborative Filtering (Microsoft 2016)
这篇论文是微软将word2vec应用于推荐领域的一篇实用性很强的文章。该文的方法简单易用,可以说极大拓展了word2vec的应用范围,使其从NLP领域直接扩展到推荐、广告、搜索等任何可以生成sequence的领域。
2、[Airbnb Embedding] Real-time Personalization using Embeddings for Search Ranking at Airbnb (Airbnb 2018)
Airbnb的这篇论文是KDD 2018的best paper,在工程领域的影响力很大,也已经有很多人对其进行了解读。简单来说,Airbnb对其用户和房源进行embedding之后,将其应用于搜索推荐系统,获得了实效性和准确度的较大提升。文中的重点在于embedding方法与业务模式的结合,可以说是一篇应用word2vec思想于公司业务的典范。
3、 [Airbnb Embedding] Real-time Personalization using Embeddings for Search Ranking at Airbnb (Airbnb 2018)
Airbnb的这篇论文是KDD 2018的best paper,在工程领域的影响力很大,也已经有很多人对其进行了解读。简单来说,Airbnb对其用户和房源进行embedding之后,将其应用于搜索推荐系统,获得了实效性和准确度的较大提升。文中的重点在于embedding方法与业务模式的结合,可以说是一篇应用word2vec思想于公司业务的典范。
4、[Alibaba Embedding] Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba (Alibaba 2018)
阿里巴巴在KDD 2018上发表的这篇论文是对Graph Embedding非常成功的应用。从中可以非常明显的看出从一个原型模型出发,在实践中逐渐改造,最终实现其工程目标的过程。这个原型模型就是上面提到的DeepWalk,阿里通过引入side information解决embedding问题非常棘手的冷启动问题,并针对不同side information进行了进一步的改造形成了最终的解决方案。
5、Behavior Sequence Transformer for E-commerce Recommendation in Alibaba(阿里2019)
近日,阿里巴巴搜索推荐事业部发布了一项新研究,首次使用强大的 Transformer 模型捕获用户行为序列的序列信号,供电子商务场景的推荐系统使用。该模型已经部署在淘宝线上,实验结果表明,与两个基准线对比,在线点击率(CTR)均有显著提高。
6.7 Embedding协助NLP极大提升性能
从简单的 Word2Vec,ELMo,GPT,BERT,XLNet到ALBERT, 这几乎是NLP过去10年最为颠覆性的成果。
1、BERT
BERT是一种基于Transformer Encoder来构建的一种模型,它整个的架构其实是基于DAE(Denoising Autoencoder)的,这部分在BERT文章里叫作Masked Lanauge Model(MLM)。MLM并不是严格意义上的语言模型,因为整个训练过程并不是利用语言模型方式来训练的。BERT随机把一些单词通过MASK标签来代替,并接着去预测被MASK的这个单词,过程其实就是DAE的过程。BERT有两种主要训练好的模型,分别是BERT-Small和BERT-Large, 其中BERT-Large使用了12层的Encoder结构。 整个的模型具有非常多的参数。
BERT在2018年提出,当时引起了爆炸式的反应,因为从效果上来讲刷新了非常多的记录,之后基本上开启了这个领域的飞速的发展。
2、XLNET
XLNet震惊了NLP领域,这种语言建模的新方法在20个NLP任务上的表现优于强大的BERT,并且在18个任务中获得了最先进的结果。
3、ALBERT
谷歌Lab近日发布了一个新的预训练模型"ALBERT"全面在SQuAD 2.0、GLUE、RACE等任务上超越了BERT、XLNet再次刷新了排行榜!ALBERT是一种轻量版本的BERT,利用更好的参数来训练模型,但是效果却反而得到了很大提升!ALBERT的核心思想是采用了两种减少模型参数的方法,比BERT占用的内存空间小很多,同时极大提升了训练速度,更重要的是效果上也有很大的提升!
6.8 Embedding表示为何如此重要?
1、它体量小,但能量大(是维度较少,但为连续性数值的向量);
2、它能在循环中不断学习(学习中能学到很多数据中很多内在规则或特性),下图为在训练完之后,学到的一些特性。
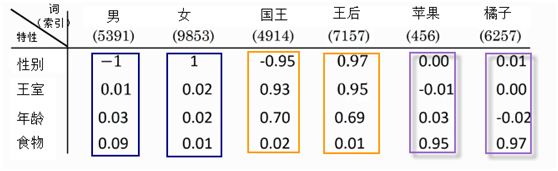
通过学习,如国王这个词,通过学习,能获取性能、王室等重要信息,而不仅仅是这个词的数字表示。