
自己动手做大数据系统(第2版)
作者:飞谷云团队
编写时间:2020年2月(武汉加油、共克时艰)
交流QQ群:50926571

(镜像文件下载小程序)
- 前言
为帮助读者更好地阅读和理解《自己动手做大数据系统》(第二版)中的实操部分,本文档主要讲解了如何使用Docker容器集群来运行书中的演示程序。容器集群共包括12个实例
| 镜像名称 | 功能 | 运行服务名 |
| flink_single | Flink单节点服务 | StandaloneSessionClusterEntrypoint
TaskManagerRunner |
| hbase-master | Hadoop、HBase、Spark集群主节点服务
HBaseThriftServer服务 SparkThriftServer服务 演示程序Flask服务 |
NameNode
SecondaryNameNode HRegionServer ThriftServer Master ResourceManager SparkSubmit HMaster |
| hbase-slave1 | Hadoop、HBase、Spark集群从节点服务 | HMaster --backup
HRegionServer NodeManager DataNode CoarseGrainedExecutorBackend Worker |
| hbase-slave2 | Hadoop、HBase、Spark集群从节点服务
Hive metestore服务 |
上同hbase-slave1节点
多出来一个HiveMetaStore |
| kafka_single | 使用本机ZooKeeper服务的单节点Kafka Broker服务 | QuorumPeerMain
Kafka |
| mysql | 存储Hive元数据和演示程序数据的MySQL数据库 | mysqld |
| redis | 单节点Redis数据库 | redis-server |
| slave01 | 运行模拟站点2的Apache服务
收集本机web访问日志的flume agent服务 |
apache2
flume-ng |
| slave02 | 运行模拟站点1的Apache服务
收集本机web访问日志的flume agent服务 |
apache2
flume-ng |
| zoo1 |
为HBase提供ZooKeeper服务的集群 |
QuorumPeerMain |
| zoo2 | QuorumPeerMain | |
| zoo3 | QuorumPeerMain |
注意:
- 阅读本文档假设你已经掌握了简单的Docker操作知识。
- 本镜像文件只是保证书中演示项目正常运行,并没有包含书中全部章节的演示代码内容。
- 本镜像文件中各个组件的配置文件不具有通用性,不要直接用于任何生产环境。
- 由于Docker容器的特性限制,集群中任何一个节点上新增或修改文件后,Docker容器重启后都会还原成初始状态。请特别注意!!
- 宿主机上的/root/feiguyun_book2/volume目录下的hadoop、hbase、mysql、spark、zk这5个目录不要做任何改动,不要删除这5个目录,也不要删除或添加目录中的任何内容。
- 宿主机上的/root/feiguyun_book2/volume/code目录映射到镜像节点hbase-master的/code目录,存放在code目录下的内容在Docker容器重启后不会丢失。
第一章 Docker环境安装和容器启动
一、选择宿主机操作系统
宿主机系统选用CentOS 6.10或7.x,或者是Ubuntu 18.04 LTS。本文档使用的是CentOS 7.6版本。在宿主机上统一使用root用户完成Docker镜像安装。以下命令查看OS版本号。
- cat /etc/centos-release
CentOS Linux release 7.6.1810 (Core)
读者也可以在windows平台上先安装CentOS 的虚拟机,在虚拟机中运行Docker。本安装文档就是在虚拟机中测试完成的。无论使用实体机还是虚拟机作为宿主机,硬件资源最低需要硬盘为50G,内存为12G。
二、修改yum源
由于在安装docker服务时会先安装一些前置工具,可以把CentOS的yum源改成国内的。具体方法可参考网上资料。(https://www.cnblogs.com/wdjsbk/p/9629931.html)
三、在宿主机上安装Docker服务
依次运行以下命令
3-1. yum install -y yum-utils device-mapper-persistent-data lvm2
3-2. yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
3-3. yum makecache fast
3-4. rpm --import https://mirrors.aliyun.com/docker-ce/linux/centos/gpg
四、安装docker-ce服务
4-1. yum install docker-ce
4-2. usermod -aG docker $(whoami)
4-3. systemctl enable docker.service
4-4. systemctl start docker.service
五、在宿主机上安装docker-compose服务
5-1. yum install epel-release -y
5-2. yum install -y python-pip
5-3. python -m pip install --upgrade pip -i https://pypi.douban.com/simple
5-4. pip --version
pip 20.0.2 from /usr/lib/python2.7/site-packages/pip (python 2.7)
5-5. yum install python-devel
5-6. yum groupinstall "Development Tools"
5-7. yum install -y gcc g++ kernel-devel
5-8. pip install docker-compose -i https://pypi.douban.com/simple
最后查看docker-compose版本号
5-9. docker-compose -version
docker-compose version 1.25.4, build unknown
六、加载镜像文件和启动容器实例
6-1. 在/root目录下创建文件夹feiguyun_book2,把百度云盘下载的所有tar.gz文件放入该文件夹下。从读者QQ群文件中下载docker-compose.yml文件放入文件夹feiguyun_book2。把从读者QQ群文件中下载的code文件夹放入/root/feiguyun_book2/volume/目录下
6-2. 进入/root/feiguyun_book2目录,运行docker images命令,确保没有任何镜像文件;运行docker ps命令,确保没有任何镜像进程运行。如下图:

6-3. 加载镜像文件,在/root/feiguyun_book2目录下,依次运行以下命令
docker load < 1
docker load < 2
docker load < 3
docker load < 4
docker load < 5
docker load < 6
docker load < 7
docker load < 8
docker load < 9
注意:当镜像文件比较大时,加载文件会比较慢
6-4. 加载完成后,查看所有镜像文件列表

6-5.使用命令 docker network create hadoop-docker 创建网络
6-6. 创建mysql数据库表存放目录。在feiguyun_book2目录下运行以下两个命令行
mkdir volume/mysql
chown -R 999 volume/mysql/
6-7. docker-compose up -d 启动Docker镜像服务
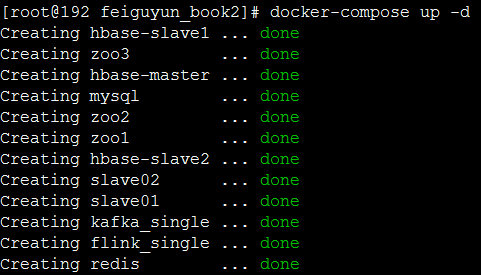
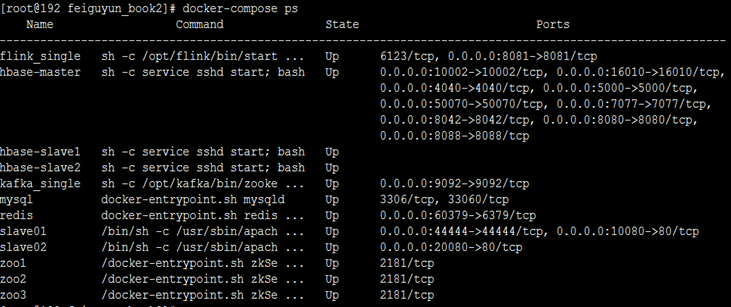
6-7. docker-compose ps查看所有镜像进程启动情况,如下图所示
第二章 大数据环境初始化及启动、验证
一、格式化HDFS。只需要运行一次
在/root/feiguyun_book2目录下运行命令:
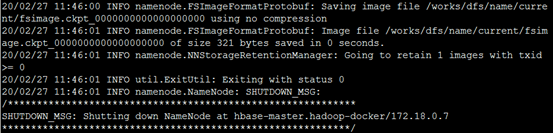
- docker-compose exec hbase-master hdfs namenode -format
最后运行的结果如下所示
二、初始化Hive元数据库。只需要运行一次
Hive的元数据存放在mysql节点的数据库中,需要先创建可以连接mysql数据库的账户。在/root/feiguyun_book2目录下运行命令:
2-1. docker-compose exec mysql bash
进入到mysql 节点,使用cli工具进入数据库(下面红色部分是输入的命令内容)
root@mysql:/# mysql -u root -p
Enter password: ****** <root用户的密码是hadoop>
进入后输入如下红色部分:
mysql> use mysql;
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'hadoop' WITH GRANT OPTION;
mysql> FLUSH PRIVILEGES;
mysql> select host,user from user;
+-----------+---------------+
| host | user |
+-----------+---------------+
| % | docker |
| % | root |
| localhost | mysql.session |
| localhost | mysql.sys |
| localhost | root |
+-----------+---------------+
5 rows in set (0.00 sec)
运行完成,可以退出mysql 节点。
2-2. 在feiguyun_book2目录下输入以下命令,初始化hive数据库表数据
docker-compose exec hbase-master schematool -dbType mysql -initSchema
最后运行结果如下

三、启动Hadoop服务
在/root/feiguyun_book2目录下运行命令:
3-1. docker-compose exec hbase-master start-dfs.sh
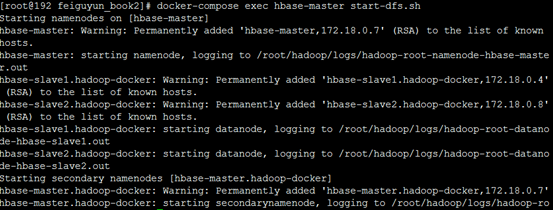
3-2. docker-compose exec hbase-master start-yarn.sh
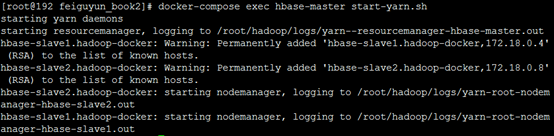
验证yarn服务和dfs服务
docker-compose exec hbase-master bash 输入命令进入hbase-master节点,在该节点中输入命令:
cd /root/hadoop/share/hadoop/mapreduce
3-4. hadoop jar hadoop-mapreduce-examples-2.7.7.jar pi 3 10
最后可以看到输出以下内容:
Estimated value of Pi is 3.60000000000000000000
四、启动Hive metastore服务
在/root/feiguyun_book2目录下运行命令:
docker-compose exec hbase-slave2 bash
进入hbase-slave2节点,启动服务,运行如下命令:
cd /root/hive/bin
4-1. nohup ./hive --service metastore&
启动后可以进入hive验证一下服务
在/root/feiguyun_book2目录下运行命令:
docker-compose exec hbase-master bash
进入hbase-master节点,启动hive cli,使用如下步骤:
[root@hbase-master /]# which hive
/root/hive/bin/hive
[root@hbase-master /]# hive
hive> show databases;
OK
default
Time taken: 1.767 seconds, Fetched: 1 row(s)
hive> exit;
五、启动HBase服务
在/root/feiguyun_book2目录下运行命令:
docker-compose exec hbase-master bash
进入hbase-master节点,启动服务,运行如下命令:
cd /root/hbase/bin
5-1. ./start-hbase.sh
启动后等待15秒左右,启动hbase shell,使用如下步骤:
[root@hbase-master /]# which hbase
/root/hbase/bin/hbase
[root@hbase-master /]# hbase shell
hbase(main):001:0> status
1 active master, 1 backup masters, 3 servers, 0 dead, 0.6667 average load
看到HBase节点状态都正常,顺便把两个表创建了,如下红色部分命令:
hbase(main):002:0> create 'rpt_artcl',{NAME=>'cf', VERSIONS=>3, COMPRESSION=>'GZ'}
0 row(s) in 5.7520 seconds
=> Hbase::Table - rpt_artcl
hbase(main):003:0> create 'access_log',{NAME=>'cf', VERSIONS=>3, COMPRESSION=>'GZ'}
0 row(s) in 2.4530 seconds
=> Hbase::Table - access_log
hbase(main):004:0> list
TABLE
access_log
rpt_artcl
2 row(s) in 0.0690 seconds
=> ["access_log", "rpt_artcl"]
最后使用exit退出HBase shell
【注】如果输入status命令显示ZooKeeper服务错误,请先查看文档最后“故障排除”中的解决办法。
在hbase-master节点启动Hbase thrift server服务
在/root/hbase/bin目录下运行命令
5-2. sh hbase-daemon.sh start thrift
六、启动Spark服务
在/root/feiguyun_book2目录下运行命令:
6-1. docker-compose exec hbase-master start-all.sh
启动后,登录hbase-slave2(或hbase-master、hbase-slave1)节点上验证spark服务
cd /root/spark/
6-2. ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://hbase-master.hadoop-docker:7077 examples/jars/spark-examples_2.11-2.4.1.jar 10
运行最后可以看到输出的Pi值如下,说明Spark正常使用
Pi is roughly 3.141452
七、启动SparkThriftServer服务
在/root/feiguyun_book2目录下运行命令:
docker-compose exec hbase-master bash 进入hbase-master节点后,运行下面红色命令
7-1. hdfs dfs -chmod -R 777 /tmp
7-2. cd /root/spark/sbin/
7-3. ./start-thriftserver.sh --hiveconf hive.server2.thrift.http.port=10000 --master spark://hbase-master.hadoop-docker:7077 --jars $HIVE_HOME/lib/hive-hbase-handler-2.3.4.jar,$HIVE_HOME/lib/hbase-client-1.4.9.jar,$HIVE_HOME/lib/hbase-common-1.4.9.jar,$HIVE_HOME/lib/hbase-server-1.4.9.jar,$HIVE_HOME/lib/hbase-protocol-1.4.9.jar,$HIVE_HOME/lib/guava-12.0.1.jar,$HIVE_HOME/lib/htrace-core-3.2.0-incubating.jar
验证sparkThriftServer服务
登录hbase-slave2(或hbase-master、hbase-slave1)节点,输入下面红色部分
[root@hbase-slave2 /]# cd /root/spark/bin
[root@hbase-slave2 bin]# ./beeline
Beeline version 1.2.1.spark2 by Apache Hive
beeline> !connect jdbc:hive2://hbase-master:10000/
Connecting to jdbc:hive2://hbase-master:10000/
Enter username for jdbc:hive2://hbase-master:10000/: root
Enter password for jdbc:hive2://hbase-master:10000/: ****
(注意:这里的登录账户是运行 beeline的用户的用户名和密码, root用户的密码是root)
SLF4J: ... ...
Connected to: Spark SQL (version 2.4.1)
Driver: Hive JDBC (version 1.2.1.spark2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hbase-master:10000/> show databases;
+-------------------------+--+
| databaseName |
+-------------------------+--+
| default |
+-------------------------+--+
1 row selected (2.507 seconds)
0: jdbc:hive2://hbase-master:10000/> !q
Closing: 0: jdbc:hive2://hbase-master:10000/
第三章 演示程序数据初始化及运行步骤
一、初始化Hive表
在/root/feiguyun_book2目录下运行命令:
docker-compose exec hbase-master bash 进入节点后,运行下面命令
- hive -f /code/source-code/ch4/create-tables.hql
运行后,如果没有出错,可以进入beeline客户端查看所有创建的表,共10张。如下图所示:
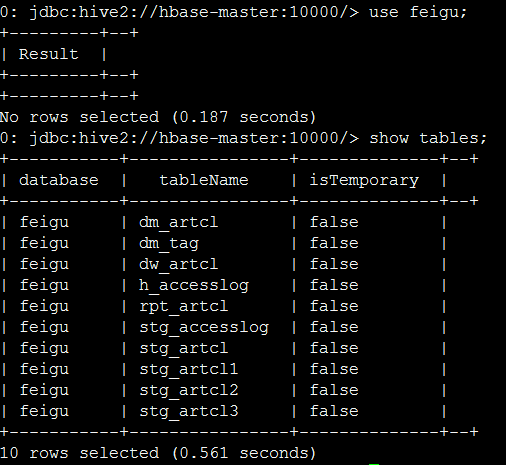
二、运行数据导入程序
在/root/feiguyun_book2目录下运行命令:
docker-compose exec hbase-master bash 进入hbase-master节点后,运行下面命令
2-1. cd /code/source-code/ch4/etl_job/
2-2. chmod +x artcl_hive2hbase/hive2hbase.sh
2-3. python3.6 run.py 20200220 ß参数20200220也可以改成其他任意日期
初始化脚本会运行大概7分钟,最终把数据插入到HBase中。以下是运行截图。
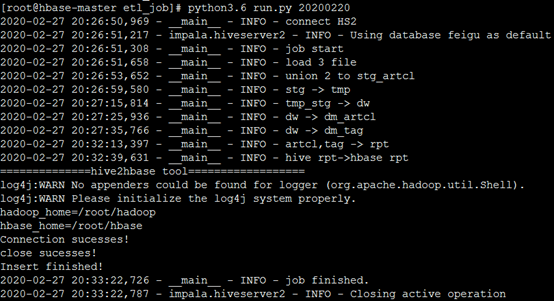
正常执行完毕后,可以进入HBase中查看记录数量,如下所示
hbase(main):001:0> count 'rpt_artcl'
90 row(s) in 1.7790 seconds
=> 90
运行导入数据程序只需执行一次,无需更换成其他日期重复运行,因为输入数据是固定的。
三、启动Flask前端查看数据
在hbase-master节点上运行下面命令
python36 /code/ch7/flask_app/run.py
运行后不要关闭该窗口。然后在宿主机上打开浏览器,输入http://宿主机IP地址:5000/index 比如我的宿主机IP地址是192.168.1.4,则可以输入 http://192.168.1.4:5000/index
进入演示程序后,可以进入“检索抓取文章”页面,输入时间段进行检索,如下所示
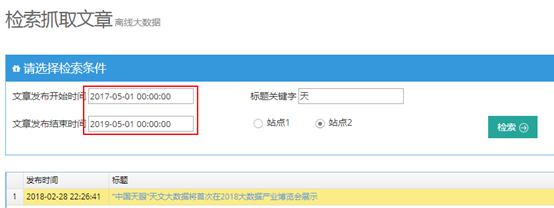
时间段请选择2017-5-1至2019-5-1之间的日期,其他日期段没有数据。
四、确认两个模拟网站正常访问
比如我的宿主机IP地址是192.168.1.4,则可以在浏览器中输入以下网址查看模拟新闻站点
http://192.168.1.4:10080/site1.com/
http://192.168.1.4:20080/site2.com/
五、创建kafka主题
进入宿主机/root/feiguyun_book2目录,输入以下命令
docker exec -it kafka_single bash
进入后创建weblog主题,如下命令
5-1. kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic weblog
5-2. kafka-topics.sh --list --zookeeper localhost:2181
以下是命令运行截图

创建后退出该节点即可。
六、启动两个Flume Agent客户端
进入宿主机/root/feiguyun_book2目录,输入以下命令
docker-compose exec slave01 bash
进入slave01节点后,在根目录输入如下命令,启动后不要关闭窗口
6-1. flume-ng agent --conf /opt/flume/conf/ --f /opt/weblog2kafka.conf --name a1 -Dflume.root.logger=INFO,console
在宿主机中启动新的terminal,进入/root/feiguyun_book2目录
docker-compose exec slave02 bash
进入slave02节点后,在根目录输入如下命令,启动后不要关闭窗口
6-2. flume-ng agent --conf /opt/flume/conf/ --f /opt/weblog2kafka.conf --name a1 -Dflume.root.logger=INFO,console
七、启动Flink并加载job
容器中Flink服务默认自动启动,只需要打开浏览器查看WebUI即可,比如我的宿主机IP地址是192.168.1.4,则可以在浏览器中输入http://192.168.1.4:8081/
参照本书11.5章节介绍的步骤,把flink2hbase_docker.jar提交作业至Flink(flink2hbase_docker.jar文件在QQ群文件中可以获得),如下图所示
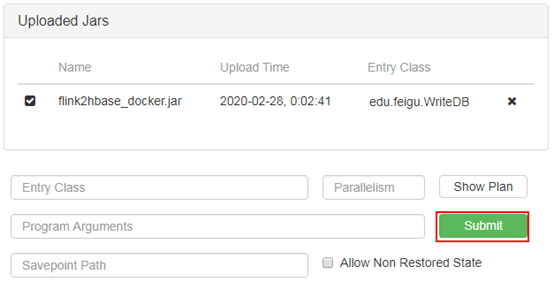
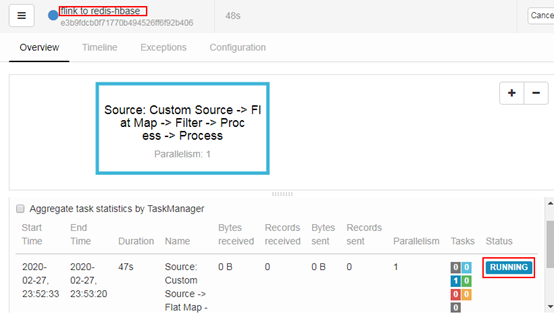
八、运行站点模拟访问程序
在宿主机上打开浏览器,输入http://宿主机IP地址:5000/ pvchart,比如我的宿主机IP地址是192.168.1.4,则可以输入 http://192.168.1.4:5000/pvchart
点击开始模拟按钮,会刷新图表20秒,如下图所示
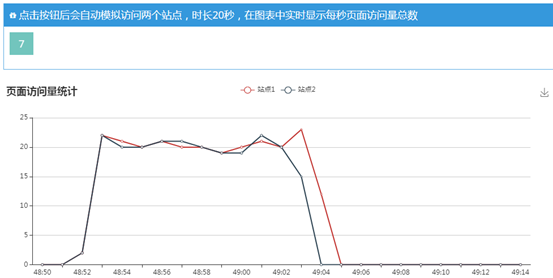
演示完成后,可以到“检索访问日志”页面查看刚才模拟访问的页面地址,在http://192.168.1.4:5000/access_log 页面,如下所示。注意查询开始结束时间要选择刚才模拟访问的时间段,其他区间可能没有数据。
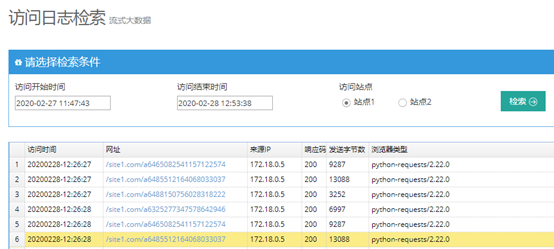
九、运行词云图生成和统计程序
根据刚才模拟访问的日志,可以生成关键字词云图,访问地址是 http://192.168.1.4:5000/wordcloud,注意查询开始结束时间要选择刚才模拟访问的时间段,如下所示:
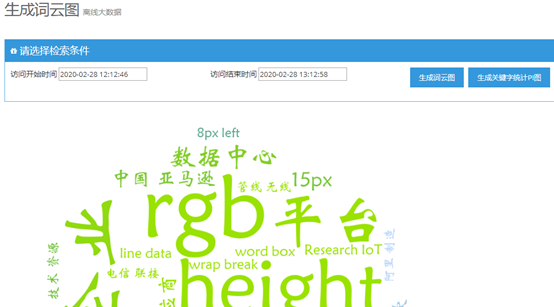
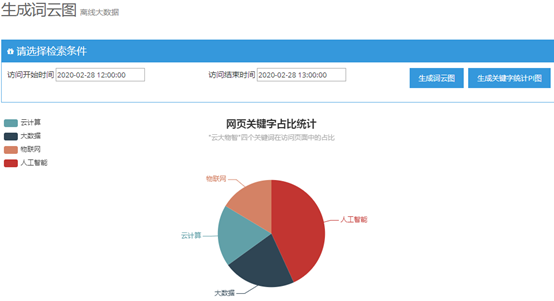
注意:其中的英文单词是未被剔除的HTML标签,有兴趣的读者可以完善自己的stopwords停用词典。如下图是生成访问关键字占比统计,时间段同样要选择刚才模拟访问的20秒。
第四章 如何关闭服务
一、关闭大数据组件服务步骤
离线大数据组件主要安装在hbase-master节点上,下面的操作都在hbase-master上运行:
cd /root/hbase/bin
./hbase-daemon.sh stop thrift
./stop-hbase.sh
cd /root/spark/sbin
./stop-thriftserver.sh
./stop-all.sh
cd /root/hadoop/sbin
./stop-yarn.sh
./stop-dfs.sh
流式大数据组件的服务不用手动关闭。
二、关闭容器集群
确认关闭hbase-master上的服务后,可以进入宿主机关闭容器集群服务。
在/root/feiguyun_book2目录下运行命令:
docker-compose down 如下所示

注意事项:
关闭容器集群后如果要再次启动,只需要在/root/feiguyun_book2目录下执行
docker-compose up -d
启动命令即可,不需要再次执行格式化HDFS和初始化Hive元数据库。
“非习劳无以进业”---- 希望您能通过以上步骤的指引,顺利运行演示程序,并最终学有所获!!
(完)
附录 故障排除
一、Hadoop启动失败
Hadoop集群启动后,可以分别登录hbase-master,hbase-slave1,hbase-slave2三个节点,依次查看Java进程是否正确。如果HDFS或MapReduce无法正常运行,可在hbase-master节点手动关闭dfs和yarn服务,尝试再次启动。
二、HBase启动失败
在虚拟机作为宿主机的场景下,经常会出现HBase首次启动失败,hbase-master节点上的HMaster进程启动后自动消失,进入hbase shell客户端使用status查看状态会提示ZooKeeper服务出错。
出现这种错误的原因是由于系统资源紧张,ZooKeeper集群和HBase通讯出故障。zoo1,zoo2,zoo3三个节点的ZooKeeper服务都是随着Docker服务自动启动的,不必手动运行。当HBase服务启动失败时,可以先进入hbase-slave1和hbase-slave2节点,使用kill命令杀掉HRegionServer服务,最后进入hbase-master节点,运行:
cd /root/hbase/bin/
./stop-hbase.sh
关闭HBase服务,再使用 ./start-hbase.sh 启动,往往就正常了。
三、Spark启动失败
Spark启动失败的情况比较少见,可以尝试关闭后再启动。或者可以修改hbase-master节点上Spark启动脚本里面内存使用量,由于本演示程序只使用Spark作为Hive的计算引擎这一个特性,可以把内存使用量调小,比如定义成256M。
四、初始化Hive表错误
Hive表DDL都定义在create-tables.hql文件中,只需要运行一次。如果第一次运行失败,再次运行前,要修改create-tables.hql文件,注释掉 create database feigu 这行。
五、运行数据导入程序错误
运行该步骤前要确保Hive metastore和HBase服务及SparkThriftServer服务都已正常启动,否则会报错。
六、运行站点模拟访问程序错误
点击开始模拟按钮后会出现坐标轴,但没有生成折线。出现这种错误要依次排查3处:
- 模拟新闻站点运行是否正常
打开浏览器,访问slave01或slave02的新闻站点,同时进入slave01或slave02的终端,运行 tail -f /var/log/apache2/access.log 看是否有日志输出。
- Kafka中weblog主题是否正常接收到数据
如果flume-ng可以收到日志数据,则进入kafka_single节点的终端,启动一个消费者
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic weblog --from-beginning
来订阅weblog主题的数据,看是否有数据输出
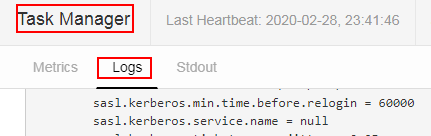
- Flink作业是否运行正常
如果kafka主题可以接收到数据,要排查Flink作业日志输出,在WebUI上查看TaskManager的Logs中是否有异常抛出,如下所示
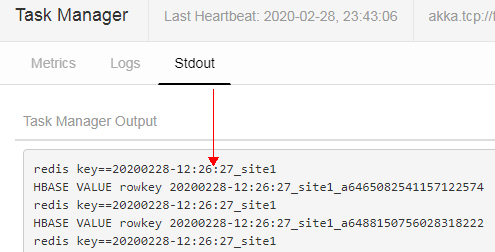
然后再查看Stdout页面中是否打印出如下内容
七、其他问题
可以在QQ群50926571中提问,或是在feiguyunai上发帖求助。