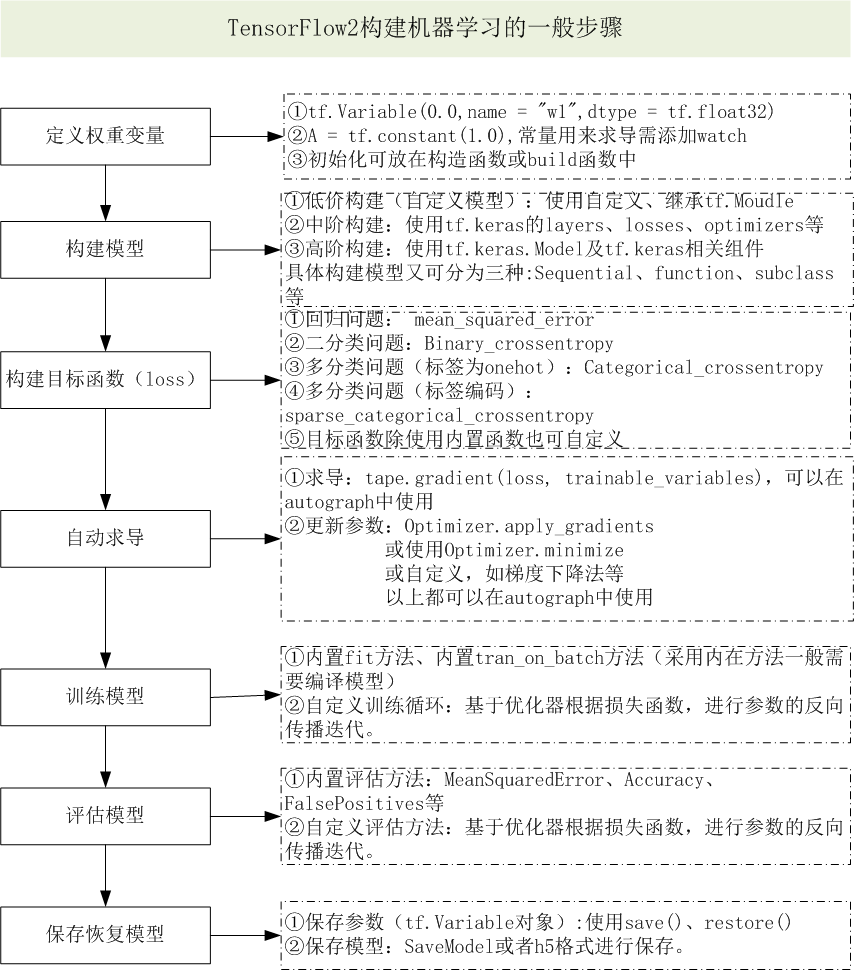
1.导入CIFAR-10数据集
CIFAR-10是由 Hinton 的学生 Alex Krizhevsky 和 Ilya Sutskever 整理的一个用于识别普适物体的小型数据集。一共包含 10 个类别的 RGB 彩色图片:飞机( a叩lane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )。图片的尺寸为 32×32,3个通道 ,数据集中一共有 50000 张训练圄片和 10000 张测试图片。 CIFAR-10数据集有3个版本,这里使用python版本。
1.1 导入需要的库
|
1 2 3 4 5 6 7 |
import os import math import numpy as np import pickle as p import tensorflow as tf import matplotlib.pyplot as plt %matplotlib inline |
1.2 定义批量导入数据的函数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
def load_CIFAR_batch(filename): """ load single batch of cifar """ with open(filename, 'rb')as f: # 一个样本由标签和图像数据组成 # (3072=32x32x3) # ... # data_dict = p.load(f, encoding='bytes') images= data_dict[b'data'] labels = data_dict[b'labels'] # 把原始数据结构调整为: BCWH images = images.reshape(10000, 3, 32, 32) # tensorflow处理图像数据的结构:BWHC # 把通道数据C移动到最后一个维度 images = images.transpose (0,2,3,1) labels = np.array(labels) return images, labels |
1.3 定义加载数据函数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
def load_CIFAR_data(data_dir): """load CIFAR data""" images_train=[] labels_train=[] for i in range(5): f=os.path.join(data_dir,'data_batch_%d' % (i+1)) print('loading ',f) # 调用 load_CIFAR_batch( )获得批量的图像及其对应的标签 image_batch,label_batch=load_CIFAR_batch(f) images_train.append(image_batch) labels_train.append(label_batch) Xtrain=np.concatenate(images_train) Ytrain=np.concatenate(labels_train) del image_batch ,label_batch Xtest,Ytest=load_CIFAR_batch(os.path.join(data_dir,'test_batch')) print('finished loadding CIFAR-10 data') # 返回训练集的图像和标签,测试集的图像和标签 return (Xtrain,Ytrain),(Xtest,Ytest) |
1.4 加载数据
|
1 2 |
data_dir = r'data\cifar-10-batches-py' (x_train,y_train),(x_test,y_test) = load_CIFAR_data(data_dir) |
运行结果
loading data\cifar-10-batches-py\data_batch_1
loading data\cifar-10-batches-py\data_batch_2
loading data\cifar-10-batches-py\data_batch_3
loading data\cifar-10-batches-py\data_batch_4
loading data\cifar-10-batches-py\data_batch_5
finished loadding CIFAR-10 data
1.5 可视化加载数据
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
label_dict = {0:"airplane", 1:" automobile", 2:"bird", 3:"cat", 4:"deer", 5:"dog", 6:"frog", 7:"horse", 8:"ship", 9:"truck"} def plot_images_labels(images, labels, num): total = len(images) fig = plt.gcf() fig.set_size_inches(15, math.ceil(num / 10) * 7) for i in range(0, num): choose_n = np.random.randint(0, total) ax = plt.subplot(math.ceil(num / 5), 5, 1 + i) ax.imshow(images[choose_n], cmap='binary') title = label_dict[labels[choose_n]] ax.set_title(title, fontsize=10) plt.show() plot_images_labels(x_train, y_train, 10) |
运行结果

2 .数据预处理并设置超参数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
x_train = x_train.astype('float32') / 255.0 x_test = x_test.astype('float32') / 255.0 train_num = len(x_train) num_classes = 10 learning_rate = 0.0002 batch_size = 64 training_steps = 20000 display_step = 1000 conv1_filters = 32 conv2_filters = 64 fc1_units = 256 |
3.使用tf.data构建数据管道
|
1 2 3 |
AUTOTUNE = tf.data.experimental.AUTOTUNE train_data = tf.data.Dataset.from_tensor_slices((x_train, y_train)) train_data = train_data.shuffle(5000).repeat(training_steps).batch(batch_size).prefetch(buffer_size=AUTOTUNE) |
4.构建模型
使用子类方法自定义模型结构的一般步骤:

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
class MyCNN(tf.keras.Model): def __init__(self): super().__init__() self.conv1 = tf.keras.layers.Conv2D( filters=32, # 卷积层神经元(卷积核)数目 kernel_size=[3, 3], # 感受野大小 padding='same', # padding策略(vaild 或 same) activation=tf.nn.relu # 激活函数 ) self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2) self.conv2 = tf.keras.layers.Conv2D( filters=64, kernel_size=[3, 3], padding='same', activation=tf.nn.relu ) self.pool2 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2) self.flatten = tf.keras.layers.Reshape(target_shape=(8 * 8 * 64,)) self.dense1 = tf.keras.layers.Dense(units=256, activation=tf.nn.relu) self.dense2 = tf.keras.layers.Dense(units=10) def call(self, inputs): x = self.conv1(inputs) # [batch_size, 32, 32, 3] x = self.pool1(x) # [batch_size, 32, 32, 32] x = self.conv2(x) # [batch_size, 16, 16, 64] x = self.pool2(x) # [batch_size, 8, 8, 64] x = self.flatten(x) # [batch_size, 8 * 8 * 64] x = self.dense1(x) # [batch_size, 256] x = self.dense2(x) # [batch_size, 10] output = tf.nn.softmax(x) return output #为使用summary时能显示tensor的shape def model01(self): x = tf.keras.Input(shape=(32, 32, 3)) return tf.keras.Model(inputs=[x], outputs=self.call(x)) |
5.训练模型
(1)实例化模型
model = MyCNN()
(2)查看模型的详细结构
model.model01().summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 32, 32, 3)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 32, 32, 32) 896
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 16, 16, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 16, 16, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 8, 8, 64) 0
_________________________________________________________________
reshape (Reshape) (None, 4096) 0
_________________________________________________________________
dense (Dense) (None, 256) 1048832
_________________________________________________________________
dense_1 (Dense) (None, 10) 2570
_________________________________________________________________
tf_op_layer_Softmax (TensorF [(None, 10)] 0
=================================================================
Total params: 1,070,794
Trainable params: 1,070,794
Non-trainable params: 0
(3)编译及训练模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])
epochs = 10
batch_size = 64
learning_rate = 0.0002
train_history = model.fit(x_train, y_train,
validation_split=0.2,
epochs=epochs,
#steps_per_epoch=100,
batch_size=batch_size,
verbose=1)
运行结果
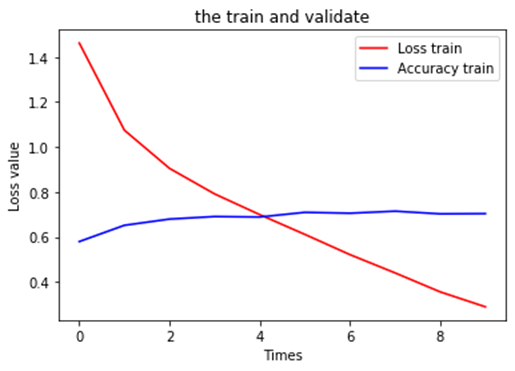
Train on 40000 samples, validate on 10000 samples
Epoch 1/10
40000/40000 [==============================] - 5s 113us/sample - loss: 1.4482 - accuracy: 0.4811 - val_loss: 1.1808 - val_accuracy: 0.5889
Epoch 2/10
40000/40000 [==============================] - 2s 53us/sample - loss: 1.0530 - accuracy: 0.6291 - val_loss: 1.0052 - val_accuracy: 0.6466
Epoch 3/10
40000/40000 [==============================] - 2s 51us/sample - loss: 0.9031 - accuracy: 0.6814 - val_loss: 0.9358 - val_accuracy: 0.6751
Epoch 4/10
40000/40000 [==============================] - 2s 50us/sample - loss: 0.7926 - accuracy: 0.7207 - val_loss: 0.8919 - val_accuracy: 0.6909
Epoch 5/10
40000/40000 [==============================] - 2s 53us/sample - loss: 0.6966 - accuracy: 0.7573 - val_loss: 0.8932 - val_accuracy: 0.6904
Epoch 6/10
40000/40000 [==============================] - 2s 50us/sample - loss: 0.6029 - accuracy: 0.7889 - val_loss: 0.8699 - val_accuracy: 0.7036
Epoch 7/10
40000/40000 [==============================] - 2s 51us/sample - loss: 0.5131 - accuracy: 0.8210 - val_loss: 0.8832 - val_accuracy: 0.7092
Epoch 8/10
40000/40000 [==============================] - 2s 52us/sample - loss: 0.4263 - accuracy: 0.8533 - val_loss: 0.9517 - val_accuracy: 0.7028
Epoch 9/10
40000/40000 [==============================] - 2s 53us/sample - loss: 0.3407 - accuracy: 0.8815 - val_loss: 0.9970 - val_accuracy: 0.7065
Epoch 10/10
40000/40000 [==============================] - 2s 52us/sample - loss: 0.2693 - accuracy: 0.9078 - val_loss: 1.0540 - val_accuracy: 0.7090
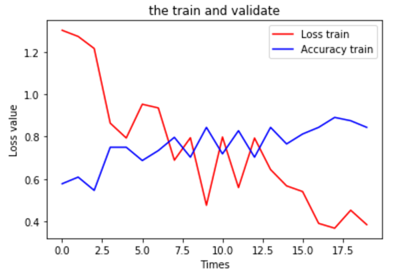
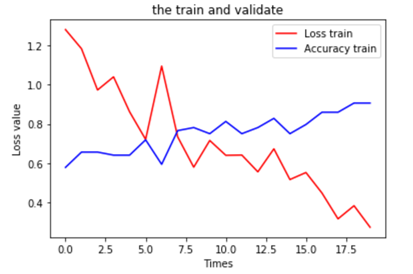
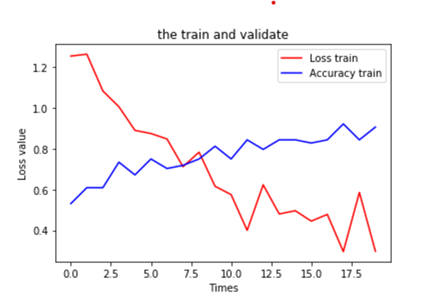
6.可视化运行结果
|
1 2 3 4 5 6 7 |
plt.title('the train and validate') plt.xlabel('Times') plt.ylabel('Loss value') plt.plot(train_history.history['loss'], color=(1, 0, 0), label='Loss train') plt.plot(train_history.history['val_accuracy'], color=(0, 0, 1), label='Accuracy train') plt.legend(loc='best') plt.show() |
7.测试模型
|
1 2 |
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2) print('test_loss:', test_loss,'\ntest_acc:', test_acc,'\nmetrics_names:', model.metrics_names) |
运行结果
10000/10000 - 1s - loss: 1.1505 - accuracy: 0.6936
test_loss: 1.1505295364379884
test_acc: 0.6936
metrics_names: ['loss', 'accuracy']
8.保存恢复整个模型
(1)保存模型参数及网络结构等
可以使用两种格式将整个模型保存到磁盘:TensorFlow SavedModel 格式和较早的 Keras H5 格式。 tensorflow官方推荐使用 SavedModel 格式。它是使用 model.save() 时的默认格式,这种保存方式适合Sequential, Functional Model, or Model subclass。
|
1 |
model.save('my_model') |
(2)恢复模型
|
1 |
newmodel = keras.models.load_model('my_model') |
(3)检查恢复模型的结构
|
1 |
newmodel.summary() |
运行结果
Model: "my_cnn_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_2 (Conv2D) multiple 896
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 multiple 0
_________________________________________________________________
conv2d_3 (Conv2D) multiple 18496
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 multiple 0
_________________________________________________________________
reshape_1 (Reshape) multiple 0
_________________________________________________________________
dense_2 (Dense) multiple 1048832
_________________________________________________________________
dense_3 (Dense) multiple 2570
=================================================================
Total params: 1,070,794
Trainable params: 1,070,794
Non-trainable params: 0
_______________________________
与原模型结构完全一致!
(4)基于恢复模型进行测试
|
1 2 |
test_loss, test_acc = newmodel.evaluate(x_test, y_test, verbose=2) print('test_loss:', test_loss,'\ntest_acc:', test_acc,'\nmetrics_names:', model.metrics_names) |
运行结果
10000/10000 - 1s - loss: 1.1488 - accuracy: 0.6936
test_loss: 1.1488204129219055
test_acc: 0.6936
metrics_names: ['loss', 'accuracy']
模型精度与原模型完全一致!