1.项目概述
运行环境tensorflow2.x,使用VOC2007数据集实现Faster-RCNN目标检测算法。 本文将详细介绍并讲解算法的每个模块和每个函数的功能,并可视化一张图片在训练和测试过程中 的变化情况。 Faster RCNN首次提出了anchor机制,后续大量流行的SSD、R-CNN、Fast RCNN、Faster RCNN、Mask RCNN和RetinaNet等等 模型都是在建立在anchor基础上的,而yolov3、yolov5等模型尽管对anchor做了一些调整,但出发点不变, 都是从anchor的三个任务和参数化坐标出发,因此,Faster RCNN很重要。
本项目基于2.4+版本的tensorflow,使用VOC2007数据集实现Faster-RCNN目标检测算法。接下来将详细讲解Faster-RCNN算法的每个模块的主要功能,期间通过可视化一张图片在训练和测试过程中如何变化的。
整个Faster-RCNN算法的网络架构图
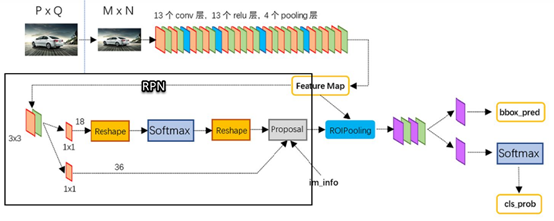
2.数据描述
VOC2007数据集的结构如下:

各个目录含义如下:
1、Annotations中存储的是.xml文件,即标注数据,标注了影像中的目标类型以及边界框bbox;
2、ImageSet中存储的都是一些txt文件,其实就是各个挑战任务所使用的图片序号,VOC比赛是将所有的图片存在一起,然后不同的挑战任务使用的图片就用一个txt存储使用图片的文件名即可;
3、JPEGImages文件夹中存储了数据集的所有图片;
4、SegmentationClass存储了类别分割的标注png。
5、SegmentationObject存储了实例分割的标注png。 其中类别分割与实例分割的区别是类别分割只区分物体的类别,同样类别的两个不同物体的像素分配同一个值;而实例分割不只区分目标的类别,而且同样类别的两个不同的对象,也要进行区分。例如两个人,在类别分割中都标注为person,而实例分割就需要分割为person1、person2.
VOC2007数据集的更大介绍可参考:https://www.codenong.com/cs106063597/
3.项目流程
1.导入需要的模块
2.导入数据
3.提取特征
4.恢复模型权重参数
5.可视化训练后的特征图
6.实现RPN网络
7.实现RoI Pooling
8.可视化最后结果
3.1 导入需要的模块
|
1 2 3 4 5 6 7 8 9 10 11 12 |
from utils.config import Config from model.fasterrcnn import FasterRCNNTrainer, FasterRCNN from model.fasterrcnn import _fast_rcnn_loc_loss import tensorflow as tf import numpy as np from utils.data import Dataset from utils.nms import nms import matplotlib.pyplot as plt %matplotlib inline |
3.2 导入数据
|
1 2 3 4 5 6 7 8 |
#导入VOC2007数据集 dataset = Dataset(config) #获取数据集中第11张图片和对应的标签 img, bboxes, labels, scale = dataset[11] for x in (img, bboxes, labels): print('shape:', x.shape, 'max:', tf.reduce_max(x).numpy(), 'min:', tf.reduce_min(x).numpy()) print(scale) |
第11张图片基本信息说明:
1、img的shape为(1, 600, 900, 3)分别代表了batch维度,图片的高和宽,通道数;
2、bboxes的类别数及坐标信息,shape为(n, 4),这里n表示该图片所含的类别总数,最大为20,不包括背景;
3、labels的shape为(n,),该图片所含的类别总数,类别代码,这里6表示汽车。
|
1 2 3 4 5 6 7 8 9 10 |
#数据集中20中类别 VOC_BBOX_LABEL_NAMES = ( 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor') #可视化原图及标注等信息 from utils.data import vis #可视化图片及目标位置 vis(img[0], bboxes, labels) |
运行结果:

3.3 特征提取
这里使用VGG16作为主干网络(backbone),经过backbone之后,输出为特征图,其形状为(1, 38, 57, 512),1代表batch size,38和57代表特征图的高度和宽度,数值上为原来(600, 900)的1/16(中间会有向下取整操作),512代表通道数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import datetime from utils.config import Config from model.fasterrcnn import FasterRCNNTrainer, FasterRCNN import tensorflow as tf from utils.data import Dataset physical_devices = tf.config.experimental.list_physical_devices('GPU') assert len(physical_devices) > 0, "Not enough GPU hardware devices available" tf.config.experimental.set_memory_growth(physical_devices[0], True) config = Config() config._parse({}) print("读取数据中....") dataset = Dataset(config) frcnn = FasterRCNN(21, (7, 7)) print('model construct completed') |
待续……