文章目录
第5章 字典和集合
5.1 问题:当索引不能满足需求时
为了满足英文字典如英文:中文,或新华字典,如拼音:汉字等类似需求,Python提供了字典这种数据结构,这种结构类似于字典,它由一系列的键-值对构成,根据键查询或获取对应的值,这就非常方便了。
5.2 一个简单字典实例
字典由一系列键-值对构成,这些键-值对包含在一对花括号{}里,键-值对用逗号分隔,键与值用冒号分隔。在一个字典中,键是唯一的,值可以不唯一,键必须是不可变的,不能是列表、字典。因键-值对在字典中存储的位置是根据键计算得到的,如果修改键将修改其位置,这就可能导致键-值对丢失或无法找到。
不过键-值对中的值,既可重复,也可修改。
用字典表示类别与标签,键-值对中,键表示类别,值表示标签值。示例如下:
dict51={'小猫':1,'小狗':2,'黄牛':3,'水牛':3 ,'羊':4}
在字典dict51中,动物类别为键,值为对应的标签值,其中值3重复2次。
5.3 创建和维护字典
字典是Python中的重要数据结构,它是一系列的键-值对,通过键来找值。键必须是不可变的,如数字、字符串、元组等,不能是可变的对象,如列表、字典等。但值可以是Python的任何对象。
5.3.1 创建字典
创建字典有多种方法,如直接创建一个含键-值对的字典(先创建一个空字典,然后往空字典添加键-值对),通过函数dict创建字典等方法。字典对键的限制包括:键唯一、必须是不可变的,如元组、字符串等,不能是列表、字典等。
(1)直接创建含键-值对的字典
|
1 2 |
dict52={1:'one',2:'two',3:'three',4:'four',5:'five'} print(type(dict52)) |
(2)创建一个空字典
|
1 2 3 4 |
dict53={} print(type(dict53)) dict54=dict() print(type(dict54)) |
5.3.2 添加键-值对
字典是可修改的,所以,创建字典后,可以往里添加键-值对。
|
1 2 3 4 5 6 7 8 9 |
#往字典dict52添加键-值对 dict52[6]='six' #往空字典添加键-值对 dict53['red']=1 dict53['black']=2 dict53['blue']=3 #添加键为'other',值为列表[5,6,7] dict53['other']=[5,6,7] print(dict53) #{'red': 1, 'blue': 3, 'black': 2, 'other': [5, 6, 7]} |
用这些方法添加的字典,Python不关心其添加顺序,如果要关注添加顺序,可以使用OrderedDict()函数,用这个函数创建的字典,将按输入的先后顺序排序,具体使用方法后续将介绍。
5.3.3 修改字典中值
修改字典中值,可根据字典名及对应键来修改。
|
1 2 3 |
#把键为'black'关联的值改为4 dict53['black']=4 print(dict53) #{'red': 1, 'blue': 3, 'black': 4, 'other': [5, 6, 7]} |
修改字典指修改字典中键-值对中值。
5.3.4 删除字典中的键-值对
删除字典中的键-值对,需指明字典名及对应键,可以使用Python的内置函数del,这个函数将永久删除。
(1)删除一个键-值对
|
1 2 3 4 |
#删除字典中包含键为'black'的键-值对 del dict53['black'] print(dict53) # {'red': 1, 'blue': 3, 'other': [5, 6, 7]} len(dict53) # 3 |
(2)删除所有键-值对
删除字典中所有键-值对,也可以使用字典函数clear(),它清除所有键-值对,但会保留字典结构。del 字典名将删除整个字典,包括字典中所有键-值对和字典定义。
|
1 2 3 4 5 |
dict53.clear() print(dict53) #{} del dict53 print(dict53) #报错:ameError: name 'dict53' is not defined |
5.4 遍历字典
我们可以用for循环遍历列表、元组,同样,也可以遍历字典。不过遍历字典有点特别,因字典的元素是键-值对,遍历字典可以遍历所有的键-值对、键或值。
5.4.1 遍历字典所有的键-值对
利用字典函数items()可以遍历所有的键-值对。
|
1 2 3 4 5 6 7 8 |
#创建一个字典 dict55 = {'Google': 'www.google.com', 'baidu': 'www.baidu.com', 'taobao': 'www.taobao.com'} #打印字典的键-值对 print("字典值 :%s "%dict55.items()) #字典值 :dict_items([('Google', 'www.google.com'), ('baidu', 'www.baidu.com'), ('taobao', 'www.taobao.com')]) #遍历字典的所有键-值对 for key,value in dict55.items(): print(key,value) |
运行结果
字典值 :dict_items([('Google', 'www.google.com'), ('baidu', 'www.baidu.com'), ('taobao', 'www.taobao.com')])
Google www.google.com
baidu www.baidu.com
taobao www.taobao.com
5.4.2 遍历字典中所有的键
根据需要,也可以只遍历字典的所有键,遍历字典名或遍历字典函数keys()的值。
|
1 2 3 4 5 6 7 8 |
# 生成一个字典 dict56={'w1':[1,2,3,4],'w2':[5,6,7,8],'w3':[9,10,11,12]} #直接遍历字典名 for key in dict56: print(key) #遍历字典函数keys()的值,其结果与直接遍历字典名相同 for key in dict56.keys(): print(key) |
5.4.3 遍历字典中所有的值
遍历字典的所有键,使用字典函数keys(),遍历字典的所有值,使用字典函数values()。
|
1 2 3 |
#遍历字典的所有值 for v in dict56.values(): print(v) |
这节我们用到了很多字典函数,如items()、keys()、values()、clear()等,字典函数还有很多,你可以在交互式命令中调用dir(dict),可用的字典函数还有很多,这里就不一一介绍了。
5.5 集合
5.5.1 创建集合
创建集合可用直接使用一对花括号来创建,也可使用set函数把序列转换为集合。
(1)直接用{}创建集合
|
1 2 3 4 |
set51={1,2,3,4,5,6} #不能用这种方法创建空集合,以下创建的是空字典 set52={} print(type(set52)) |
(2)使用set()函数创建集合
使用set()函数创建集合,可以把列表、字符串、元组等转换为集合,同时自动去重。
|
1 2 3 4 5 6 7 |
lst51=[1,2,3,4,5,5,6,6,7,8,9] #使用set()函数创建集合 set53=set(lst51) print(set53) #{1, 2, 3, 4, 5, 6, 7, 8, 9} #创建空集合 set54=set() print(set54) # set() |
5.5.2 集合的添加和删除
集合是可变的,所以可以添加元素、删除元素。添加使用集合函数add()、删除使用集合函数remove()或pop()或clear()等。
(1)添加元素
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#创建一个空集合 set54=set() #往集合中添加元素 for i in range(5): set54.add(i) print(set54) #定义动物和标签构成的字典 dict57={'白猫':1,'黑猫':1,'狼狗':2,'哈巴狗':2,'小麻雀':3,'打麻雀':3} #把标签放在一个集合中,实现自动去重 set55=set() for value in dict57.values(): set55.add(value) print(set55) #{1, 2, 3} |
(2)删除元素
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#remove删除不存在的元素,将报错,所以先判断,然后再删除 i=10 if i in set54: set54.remove(i) print(set54) #使用discard,功能和remove一样,好处是没有的话,不会报错 set54.discard(10) #用pop删除,在list里默认删除最后一个,在set里随机删除一个 set54.pop() #清除所有元素 set54.clear() print(set54) |
5.6 字符串、列表、元组、字典和集合的异同
本书第3章、本章介绍了列表、元组、字典和集合等数据结构,下面通过表5-1比较这些数据结构的异同。
表5-1 列表、元组、字典及集合的异同

5.7 列表、集合及字典的推导式
在4.3小节我们简单介绍了列表推导式,这里我们介绍字典、集合推导式。什么叫推导式?它有哪些特点?如果觉得概念不好理解没关系,先来理解它的本质,推导式简单理解为把循环语句与判断语句或表达式放在一起作为一个句子。这个Python非常强大也是非常最受欢迎的特点之一,这个特点不但是程序简洁、而且逻辑更清晰和直观。
(1)列表的推导式:
如:[expr for val in collection [if condition]],这条语句转换为我们熟悉的方式就是;
result=[]
for val in collection:
[if condition:] ###条件不是必须的
result.append(expr)
|
1 2 |
list11=[1,2,4,7,8] [i*2 for i in list11 if i%2==0] |
运行结果:
[4, 8, 16]
(2)字典的推导式:
{key_expr:value_expr for val in collection [if condition]]}
|
1 2 3 4 5 6 7 8 9 |
#定义一个字典 d1={'red':10,'blue':20,'gree':30} #定义该字典的推导式 d2={len(key) for key in d1} print(d2) s1=['python','scala','hadoop','sparkml'] s2=[(k,v) for k,v in enumerate(s1)] print(s2) |
运行结果:
{3, 4}
[(0, 'python'), (1, 'scala'), (2, 'hadoop'), (3, 'sparkml')]
(3)集合的推导式:
{expr for val in collection [if condition]]}
|
1 2 3 4 5 6 7 8 |
#定义一个集合 set1={1,3,8,5,2,5,3} #查看该集合,可以看到结果已自动去掉重复元素3了 print(set1) #定义集合推导式 set2={i+10 for i in set1} print(set2) |
运行结果:
{1, 2, 3, 5, 8}
{11, 12, 13, 15, 18}
5.8迭代器和生成器
当列表、元组、字典、集合中的元素很多时,如几百万、几亿甚至更多,那么这些元素一次全面放在内存里,它们将占据大量的内存资源。是否有更好、更高效的存储方式呢?迭代器和生成器就为解决这一问题而提出的。采用迭代器和生成器,不会一次性把所有元素加载到内存,而是需要的时候才生成返回结果。它们既可存储很大数据、甚至无限数据,又无需多少资源。利用生成器或迭代器来存储数据的方式,在大数据处理、机器学习中经常使用。
我们前面介绍的序列、元组、字典及集合都是可迭代对象,用在for,while等语句中。
这些数据结构又称为容器,在容器上使用iter()就得到迭代器,利用next()函数就可持续取值,直到取完为止。生成器是迭代器,生成器我们后续将介绍,图5-1说明了生成器、迭代器、可迭代对象之间的关系。
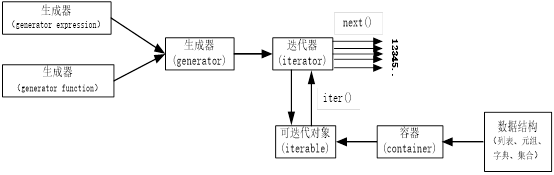
图5-1 Python可迭代对象、迭代器和生成器的关系图
(1)容器是一系列元素的集合,str、list、set、dict、file、sockets对象都可以看作是容器,容器都可以被迭代(用在for,while等语句中),因此它们被称为可迭代对象。
(2)可迭代对象实现了__iter__方法,该方法返回一个迭代器对象。
(3)迭代器持有一个内部状态的字段,用于记录下次迭代返回值,它实现了__next__和__iter__方法,迭代器不会一次性把所有元素加载到内存,而是需要的时候才生成返回结果。
(4)生成器是一种特殊的迭代器,它的返回值不是通过return而是用yield。
5.8.1 迭代器
用函数iter()可以把列表、元组、字典集合等对象转换为迭代器。迭代器是Python最强大的功能之一,是访问集合元素的一种方式。迭代器是一个可以记住遍历的位置的对象,迭代器对象使用next()函数,从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
(1)定义一个列表
|
1 2 3 |
lst51={10,20,30,40,50} for i in lst51: print(i,end=" ") |
(2)生成迭代器
对列表、元组、字典和集合,使用函数iter(),即可把转换为迭代器。
|
1 2 |
iter51=iter(lst51) print(type(iter51)) #set_iterator |
(3)从迭代器中取元素
|
1 2 3 4 5 |
while True: try: print (next(iter51),end=" ") except StopIteration: break |
这里是用来异常处理except,后续将介绍。其中使用next()从迭代器取数,直到没有数据(即StopIteration)触发语句break。
5.8.2 生成器
从图5-1可知,生成器可分为生成器函数、生成器表达式。生成器函数第6章将介绍,这里主要介绍生成器表达式。生成器表达式是列表推倒式的生成器版本,看起来像列表推导式,但是它返回的是一个生成器对象而不是列表对象。
生成器表示式与列表推导式相似,列表推导式是在中括号[]里,把中括号改为小括号()变成生成器。
|
1 2 3 4 5 6 7 8 |
#创建一个生成器 gen51 = (2*x+1 for x in range(10)) print(type(gen51)) #class 'generator' #用for循环从生成器取数据 for i in gen51: print(i,end=" ") #1 3 5 7 9 11 13 15 17 19 |
或用next()函数,从生成器next()逐一取数据,与for循环取数效果一样。
|
1 2 3 4 5 6 7 8 9 |
#创建一个生成器 gen51 = (2*x+1 for x in range(10)) #从生成器中,用next()逐一取数据 while True: try: print (next(gen51),end=" ") except StopIteration: break #1 3 5 7 9 11 13 15 17 19 |
5.9 练习
(1)创建一个字典,字典中包括3中动物名称,3种植物名称,以这些名称为键,动物对应的值都为1,植物对应的值都为2。遍历这个字典,把动物名称放在一个列表中,植物名称放在另一个列表中。
(2)编写一个Python脚本来生成一个字典,其中键是1到10之间的数字(都包括在内),值是键的平方。
(3)现有一个列表li = [1,3,'a','c'],有一个字典(此字典是动态生成的,可用dic={}模拟字典)
现在需要完成如下操作:
①如果该字典没有"k1"这个键,那就创建
这个"k1"键和对应的值(该键对应的值为空列表),并将列表li中的索引位为奇数对应的元素,添加到
"k1"这个键对应的空列表中。
②如果该字典中有"k1"这个键,且k1对应的value是列表类型,则不做任何操作。