文章目录
第3章 ChatGPT简介
3.1ChatGPT厚积薄发
最近,工智能公司OpenAI推出的ChatGPT风靡全球,其上线仅两个月,注册用户破亿。ChatGPT包含丰富的知识,不仅能更好地理解人类的问题和指令,流畅进行多轮对话,还在越来越多领域显示出解决各种通用问题和推理生成能力。许多人相信,ChatGPT不仅是新一代聊天机器人的突破,也将为信息产业带来巨大变革,也预示着AI技术应用将迎来大规模普及。
ChatGPT表现不俗?其背后的技术有哪些?
3.2 从GPT到GPT-3
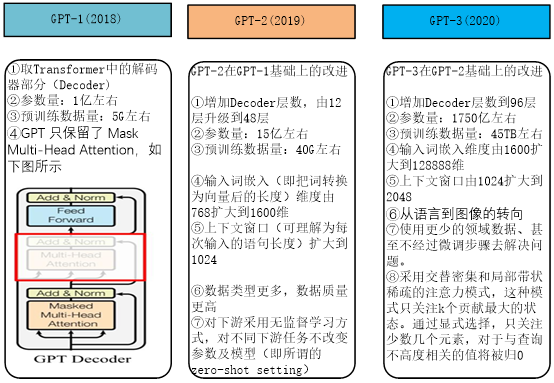
3.3 从GPT-3到ChatGPT的进化路线图
下图为从最初的GPT-3到GPT-3.5的进化路线图。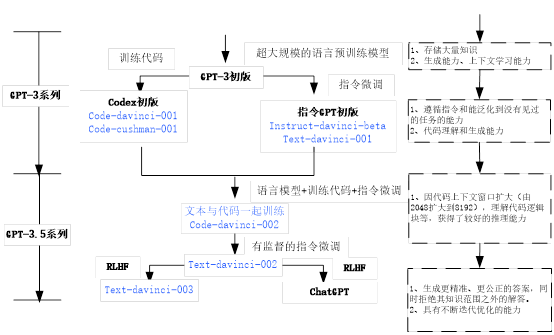
图1 GPT-3初版到ChatGPT的进化路线图
其中text—davinci—002是在code—davinci—002的基础上使用InstructGPT训练方法改进的。GPT-3.5在GPT-3的基础上加入了代码的能力,ChatGPT的代码训练中,很多数据来自于类似Stack Overflow这样一些代码问答的网站,所以我们会发现它做简单的任务其实做得还蛮好的。
从图1可知,GPT-3为ChatGPT打下了扎实的基础,但codex、RLHF等技术新增很多新功能,挖掘了GPT-3的潜力。
3.4 使GPT-3初版升级到ChatGPT的多项关键技术
从图1可知,这两项关键技术是代码训练(Codex)、RLHF及TAMER等
1、Codex
Codex 模型系列是 GPT-3 系列的后代,它经过了自然语言和数十亿行代码的训练。 该模型系列精通十几种语言,包括 C# JavaScript、Go、Perl、PHP、Ruby、Swift、TypeScript、SQL甚至Shell,但最擅长 Python。
你可以使用Codex完成各种任务,包括:
将注释转换为代码
在上下文中补全下一行代码或函数
为你提供一些知识,例如为应用程序查找有用的库或 API 调用
添加注释
重写代码以提高效率
Codex如何训练的呢?
首先,在GITHub数据上预训练模型。这个模型可以合理地表征人类编码空间,可以极大地减少搜索量级。使用带tempering的GOLD目标函数,结合编程竞赛数据集,微调模型。可有进一步降低搜索空间,给每个编程题目生成一个较大的样本集;过滤这个样本集,得到一个较小的候选结果集。
然后,进行代码补全,代码补全这个任务的特殊性:具体来说,传统的NLP任务,生成的结果越接正确答案,那么模型得分越高,但是代码不是这样的,代码但凡有一点点小Bug,都可能造成毁灭性的结果。所以对于代码补全任务,判断生成代码的正确与否就是使用的单元测试(unit test)。
针对代码补全这样一个特殊问题,作者提出了一个pass@k的一个指标,生成k个结果,只要有一个通过就算通过(k如果比较大,就会对模型的能力过度乐观,当k比较大的时候,虽然模型分数比较高,但是在使用时,会给用户返回一大堆代码,让用户去选,这个也是很难的,所以说需要排算法,但这个分数并没有反映排序)。
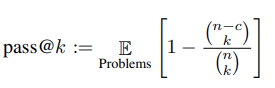
评估Codex模型使用了Github及HumanEval等数据集。
在预训练过程中引入程序代码,和文本一起参与预训练,以此进一步增强大型语言模型(Large Language Model,LLM)的推理能力。这个结论从不少论文的实验部分都可以得出。如图3所示。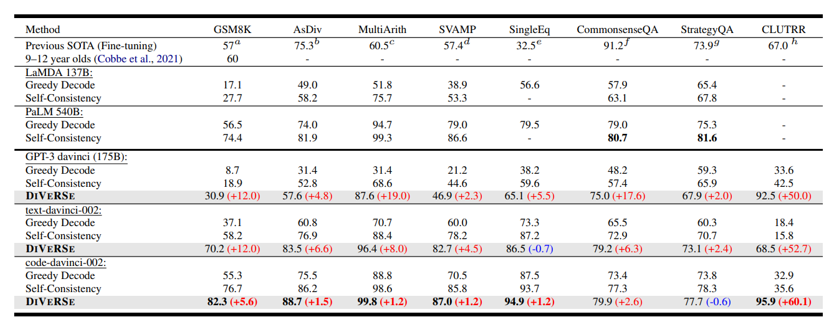
图3 有关codex的试验数据
从图3给出的实验数据,来自于论文“On the Advance of Making Language Models Better Reasoners”,其中GPT-3 davinci就是标准的GPT-3模型,基于纯文本训练;code-davinci-002(OpenAI内部称为Codex)是同时在Code和NLP数据上训练的模型。如果比较两者效果,可以看出,不论采用具体哪种推理方法,仅仅是从纯文本预训练模型切换到文本和Code混合预训练模型,在几乎所有测试数据集合上,模型推理能力都得到了巨大的效果提升。
2、RLHF
人类反馈强化学习(Reinforcement Learning from Human Feedback,RHFL)模型将预训练语言模型按照人类反馈进一步微调以符合人类偏好,利用人类反馈信息直接优化模型。Open AI 采用了人类反馈强化学习作为ChatGPT和核心训练方式,并称其是“能有效提升通用人工智能系统与人类意图对齐的技术”。RLHF 的训练包括三个核心步骤:
(1)预训练语言模型(也可以使用额外文本进行微调,监督微调新模型可以让模型更 加遵循指令提示,但不一定符合人类偏好)。
(2)对模型根据提示(prompt)生成的文本进行质量标注,由人工标注者按偏好从最 佳到最差进行排名,利用标注文本训练奖励模型,从而学习到了人类对于模型根据给定提 示生成的文本序列的偏好性。
(3)使用强化学习进行微调,确保模型输出合理连贯的文本片段,并且基于奖励模型 对模型输出的评估分数提升文本的生成质量。
详细过程如图4所示。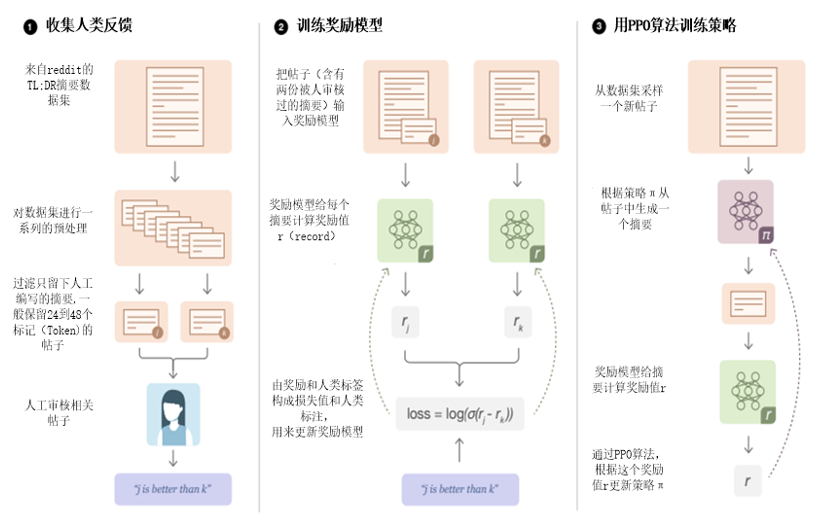
图4 RHFL的训练过程,
原图来自:Learning to summarize from human feedback
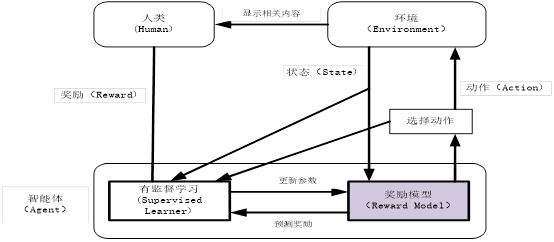
3、TAMER
TAMER(Training an Agent Manually via Evaluative Reinforcement,评估式强化人工训练代理)框架。该框架将人类标记引入到智能体(即强化学习中的Agents)的学习循环中,可以通过人类向Agents提供奖励反馈(即指导Agents进行训练),从而快速达到训练任务目标。其架构图如下所示。
3.5 ChatGPT训练过程

3.6 ChatGPT不断迭代的路线图
图5 ChatGPT不断迭代的路线图
3.7ChatGPT的不足
尽管ChatGPT在上下文对话能力甚至编程能力上表现出色,完成了大众对人机对话机器人由“人工智障”到“人工智能”的突破,我们也要看到,ChatGPT仍然有一些局限性,还需不断迭代进步。
(1)ChatGPT在其未经大量语料训练的领域缺乏“人类常识”和引申能力,甚至会一本正经的“胡说八道”。
(2)ChatGPT无法处理复杂冗长或者特别专业的语言结构。对于来自金融、自然科学或医学等专业领域的问题,如果没有进行足够的语料“喂食”,ChatGPT可能无法生成适当的回答。
(3)ChatGPT还没法在线的把新知识纳入其中,而出现一些新知识就去重新预训练GPT模型也是不现实的。
(4)训练ChatGPT需要耗费非常大量的算力,成本还是很大的。
3.8 ChatGPT应用场景
ChatGPT能够提供高效的信息获取方式,有望成为重要的生产工具,潜在应用领域广泛。业界普遍认为,ChatGPT将在智能办公、智慧科研、智慧教育、智慧医疗及游戏、新闻等领域迅速落地。在金融、传媒、文娱、电商等领域,ChatGPT可以为各类消费群体提供个性化、高质量的服务,解锁多领域智慧应用。