1.1大模型Emergent Abilities(新兴能力)现象
模型规模达到某个阈值时,模型对某些问题的处理性能呈现快速增长。这个过程类似于水加热到100度的过程。
目前一些大模型已达或接近这个阈值,个人觉得这些技术或方法功不可没:
一、软件方面
1.BP算法
2.注意力机制
3.强化学习
强化学习一大贡献就是弥补了传统机器学习评估标准的不足,传统机器学习一般基于损失函数进行评估,希望预测与标签的差平方(或两者的分布近似度)越小越好。这种评估方式是一种绝对值的近似,不利于输出多样性的结果。而强化学习采用奖励或评分的方式,看重的是输出与期望值的对齐程度。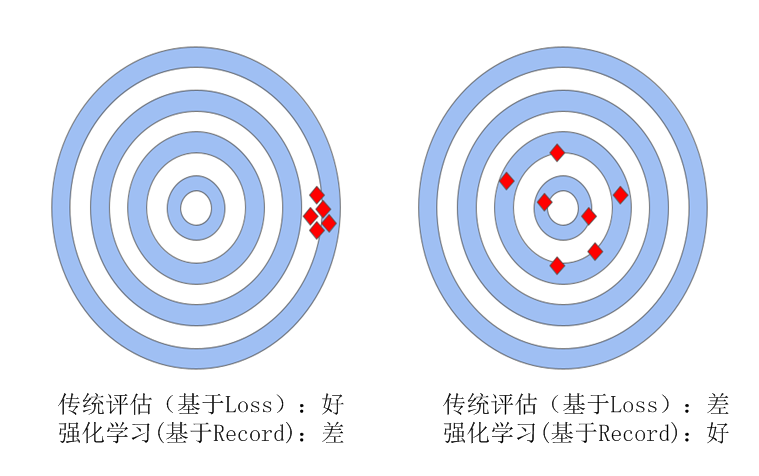
4.大数据平台,如PyTorch,TensorFlow,及CUDA架构等
5.GEMM
二、硬件方面
GPU、TPU等地助力。
1.2 几种正助力拓展序列长度的几种算法
(1)FlashAttention,FlashAttention-2
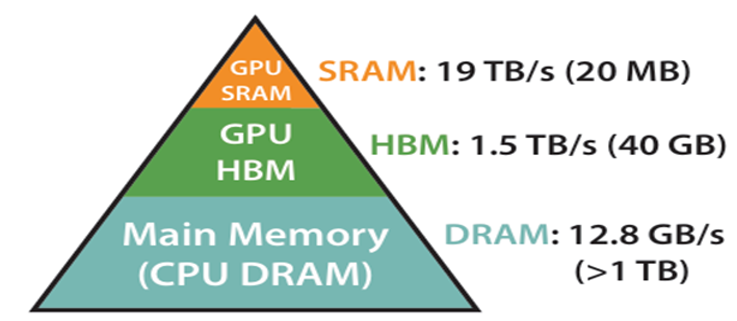
FlashAttention从软件和硬件两个方面对Transformer模型进行优化,软件方面采用了分块、在线softmax,重计算(一种类似于Python迭代器的思路,用规则或算法表示数据,而不实际存在大数据);硬件方法,充分考虑了GPU的架构特点,如A100,H100等HBM,SRAM等优缺点。
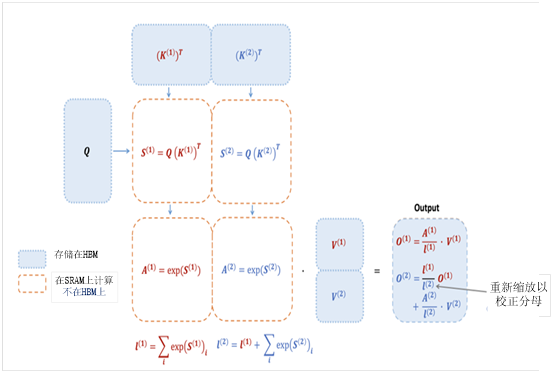
HBM,SRAM等优缺点
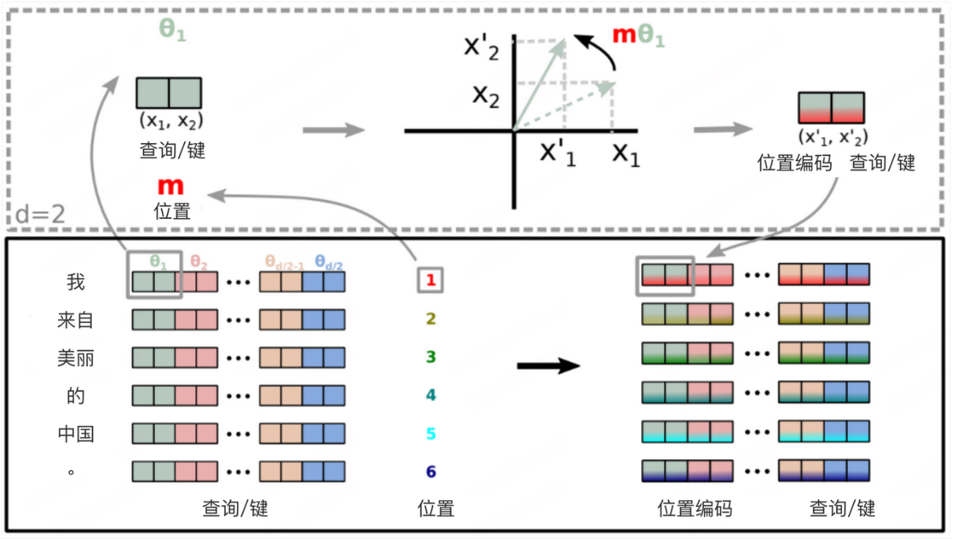
(2)Learned、Relative、RoPE等位置编码方法
(3)多种注意力机制
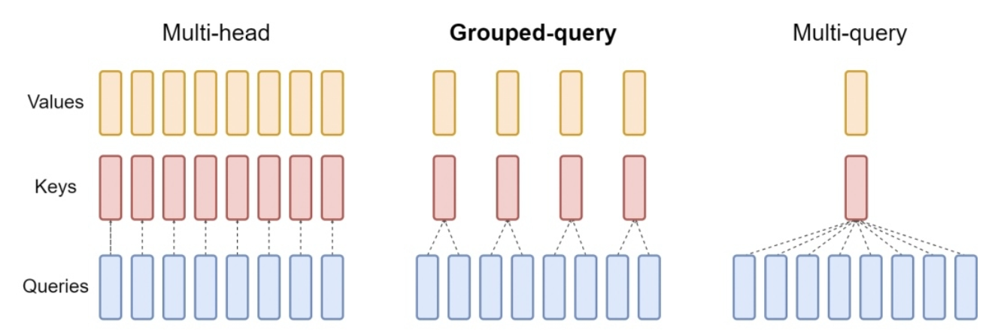
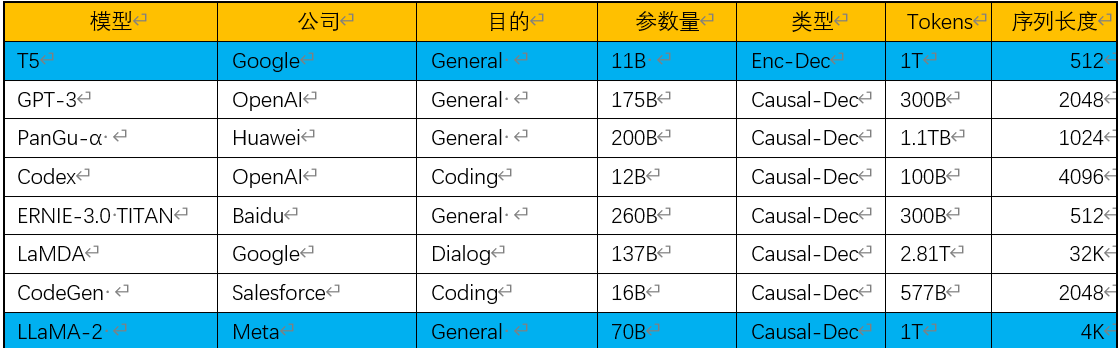
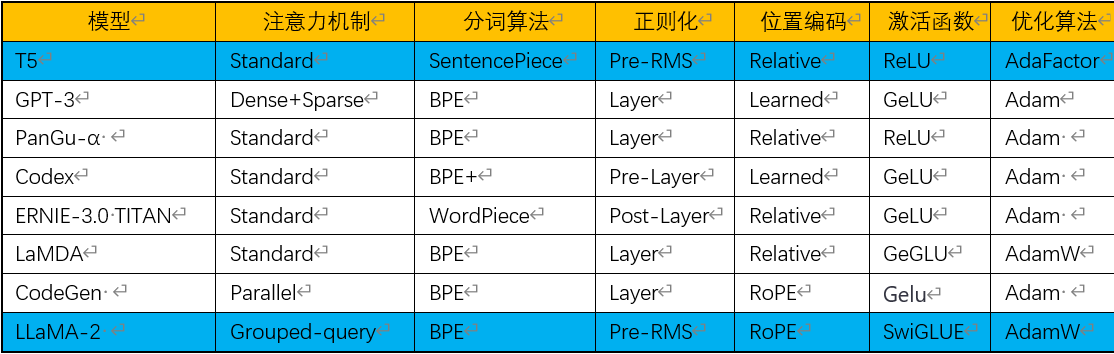
1.3.各种大模型使用技术概览
下面我选择8个比较典型的大模型,统计了它们使用的一些技术,供大家参考。
————————————————
版权声明:本文为CSDN博主「wumg3000」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wumg3000/article/details/135242873