第4章 特征提取、转换和选择
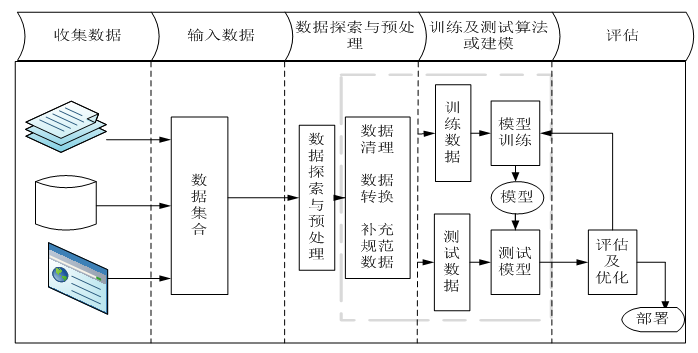
在实际机器学习项目中,我们获取的数据往往是不规范、不一致、有很多缺失数据,甚至不少错误数据,这些数据有时又称为脏数据或噪音,在模型训练前,务必对这些脏数据进行处理,否则,再好的模型,也只能脏数据进,脏数据出。
这章我们主要介绍对数据处理涉及的一些操作,主要包括:
特征提取
特征转换
特征选择
4.1 特征提取
特征提取一般指从原始数据中抽取特征。
4.1.1 词频-逆向文件频率(TF-IDF)
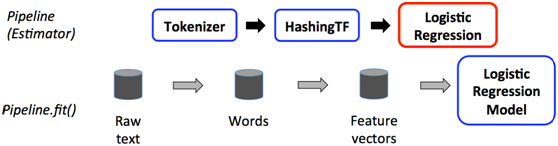
词频-逆向文件频率(TF-IDF)是一种在文本挖掘中广泛使用的特征向量化方法,它可以体现一个文档中词语在语料库中的重要程度。
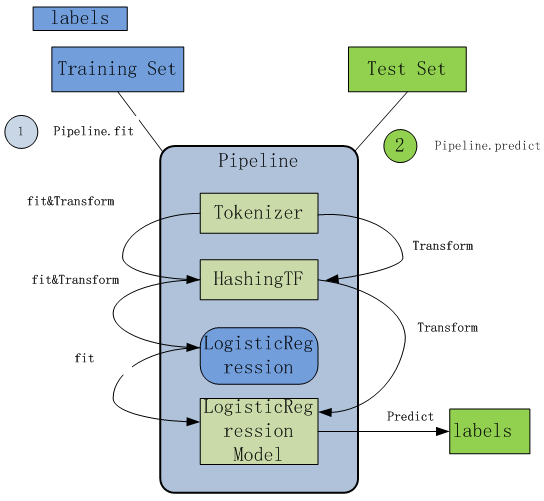
在下面的代码段中,我们以一组句子开始。首先使用分解器Tokenizer把句子划分为单个词语。对每一个句子(词袋),我们使用HashingTF将句子转换为特征向量,最后使用IDF重新调整特征向量。这种转换通常可以提高使用文本特征的性能。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import org.apache.spark.ml.feature.{HashingTF, IDF, Tokenizer} val sentenceData = spark.createDataFrame(Seq( (0, "Hi I heard about Spark"), (0, "I wish Java could use case classes"), (1, "Logistic regression models are neat") )).toDF("label", "sentence") val tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words") val wordsData = tokenizer.transform(sentenceData) val hashingTF = new HashingTF().setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(20) val featurizedData = hashingTF.transform(wordsData) // CountVectorizer也可获取词频向量 val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features") val idfModel = idf.fit(featurizedData) val rescaledData = idfModel.transform(featurizedData) rescaledData.select("features", "label").take(3).foreach(println) |
4.1.2 Word2Vec
Word2vec是一个Estimator,它采用一系列代表文档的词语来训练word2vecmodel。 在下面的代码段中,我们首先用一组文档,其中每一个文档代表一个词语序列。对于每一个文档,我们将其转换为一个特征向量。此特征向量可以被传递到一个学习算法。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import org.apache.spark.ml.feature.Word2Vec // 输入数据,每行为一个词袋,可来自语句或文档。 val documentDF = spark.createDataFrame(Seq( "Hi I heard about Spark".split(" "), "I wish Java could use case classes".split(" "), "Logistic regression models are neat".split(" ") ).map(Tuple1.apply)).toDF("text") //训练从词到向量的映射 val word2Vec = new Word2Vec() .setInputCol("text") .setOutputCol("result") .setVectorSize(3) .setMinCount(0) val model = word2Vec.fit(documentDF) val result = model.transform(documentDF) result.select("result").take(3).foreach(println) |
4.1.3 计数向量器
计数向量器(Countvectorizer)和计数向量器模型(Countvectorizermodel)旨在通过计数来将一个文档转换为向量。
以下用实例来说明计数向量器的使用。
假设有以下列id和texts构成的DataFrame:
|
1 2 3 4 |
id | texts ----|---------- 0 | Array("a", "b", "c") 1 | Array("a", "b", "b", "c", "a") |
每行text都是Array [String]类型的文档。调用fit,CountVectorizer产生CountVectorizerModel含词汇(a,b,c)。转换后的输出列“向量”包含:
调用的CountVectorizer产生词汇(a,b,c)的CountVectorizerModel,转换后的输出向量如下:
|
1 2 3 4 |
id | texts | vector ---|--------------------------------|--------------- 0 | Array("a", "b", "c") | (3,[0,1,2],[1.0,1.0,1.0]) 1 | Array("a", "b", "b", "c", "a") | (3,[0,1,2],[2.0,2.0,1.0]) |
每个向量代表文档的词汇表中每个词语出现的次数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
importorg.apache.spark.ml.feature.{CountVectorizer,CountVectorizerModel} val df = spark.createDataFrame(Seq( (0,Array("a","b","c")), (1,Array("a","b","b","c","a")) )).toDF("id","words") //从语料库中拟合CountVectorizerModel val cvModel:CountVectorizerModel=newCountVectorizer() .setInputCol("words") .setOutputCol("features") .setVocabSize(3) .setMinDF(2) .fit(df) //或者,用先验词汇表定义CountVectorizerModel val cvm =newCountVectorizerModel(Array("a","b","c")) .setInputCol("words") .setOutputCol("features") cvModel.transform(df).show(false) +---+---------------+-------------------------+ |id |words |features | +---+---------------+-------------------------+ |0 |[a, b, c] |(3,[0,1,2],[1.0,1.0,1.0])| |1 |[a, b, b, c, a]|(3,[0,1,2],[2.0,2.0,1.0])| +---+---------------+-------------------------+ |
4.2 特征转换
在机器学习中,数据处理是一件比较繁琐的事情,需要对原有特征做多种处理,如类型转换、标准化特征、新增衍生特征等等,需要耗费大量的时间和精力编写处理程序,不过,自从Spark推出ML后,情况大有改观,Spark ML包中提供了很多现成转换器,例如:StringIndexer、IndexToString、OneHotEncoder、VectorIndexer,它们提供了十分方便的特征转换功能,这些转换器类都位于org.apache.spark.ml.feature包下。
4.2.1分词器
分词器(Tokenization)将文本划分为独立个体(通常为单词)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
importorg.apache.spark.ml.feature.{RegexTokenizer,Tokenizer} importorg.apache.spark.sql.functions._ val sentenceDataFrame = spark.createDataFrame(Seq( (0,"Hi I heard about Spark"), (1,"I wish Java could use case classes"), (2,"Logistic,regression,models,are,neat") )).toDF("id","sentence") val tokenizer =newTokenizer().setInputCol("sentence").setOutputCol("words") val regexTokenizer =newRegexTokenizer() .setInputCol("sentence") .setOutputCol("words") .setPattern("\\W")//或者使用 .setPattern("\\w+").setGaps(false) val countTokens = udf {(words:Seq[String])=> words.length } val tokenized = tokenizer.transform(sentenceDataFrame) tokenized.select("sentence","words") .withColumn("tokens", countTokens(col("words"))).show(false) +-----------------------------------+------------------------------------------+------+ |sentence |words |tokens| +-----------------------------------+------------------------------------------+------+ |Hi I heard about Spark |[hi, i, heard, about, spark] |5 | |I wish Java could use case classes |[i, wish, java, could, use, case, classes]|7 | |Logistic,regression,models,are,neat|[logistic,regression,models,are,neat] |1 | +-----------------------------------+------------------------------------------+------+ val regexTokenized = regexTokenizer.transform(sentenceDataFrame) regexTokenized.select("sentence","words") .withColumn("tokens", countTokens(col("words"))).show(false) +-----------------------------------+------------------------------------------+------+ |sentence |words |tokens| +-----------------------------------+------------------------------------------+------+ |Hi I heard about Spark |[hi, i, heard, about, spark] |5 | |I wish Java could use case classes |[i, wish, java, could, use, case, classes]|7 | |Logistic,regression,models,are,neat|[logistic, regression, models, are, neat] |5 | +-----------------------------------+------------------------------------------+------+ |
4.2.2 移除停用词
停用词为在文档中频繁出现,但未承载太多意义的词语,它们不应该被包含在算法输入中,所以会用到移除停用词(StopWordsRemover)。
示例:
假设我们有如下DataFrame,有id和raw两列
|
1 2 3 4 |
id | raw ------|---------- 0 | [I, saw, the, red, baloon] 1 | [Mary, had, a, little, lamb] |
通过对raw列调用StopWordsRemover,我们可以得到筛选出的结果列如下
|
1 2 3 4 |
id | raw | filtered ------|------------------------------------|-------------------- 0 | [I, saw, the, red, baloon] | [saw, red, baloon] 1 | [Mary, had, a, little, lamb]|[Mary, little, lamb] |
其中,“I”, “the”, “had”以及“a”被移除。
实现以上功能的详细代码:
|
1 2 3 4 5 6 7 8 9 10 11 |
import org.apache.spark.ml.feature.StopWordsRemover val remover = new StopWordsRemover() .setInputCol("raw") .setOutputCol("filtered") val dataSet = spark.createDataFrame(Seq( (0, Seq("I", "saw", "the", "red", "balloon")), (1, Seq("Mary", "had", "a", "little", "lamb")) )).toDF("id", "raw") remover.transform(dataSet).show(false) |
4.2.3 n-gram
一个n-gram是一个长度为整数n的字序列。NGram可以用来将输入转换为n-gram。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import org.apache.spark.ml.feature.NGram val wordDataFrame = spark.createDataFrame(Seq( (0, Array("Hi", "I", "heard", "about", "Spark")), (1, Array("I", "wish", "Java", "could", "use", "case", "classes")), (2, Array("Logistic", "regression", "models", "are", "neat")) )).toDF("id", "words") val ngram = new NGram().setN(2).setInputCol("words").setOutputCol("ngrams") val ngramDataFrame = ngram.transform(wordDataFrame) ngramDataFrame.select("ngrams").show(false) +------------------------------------------------------------------+ |ngrams | +------------------------------------------------------------------+ |[Hi I, I heard, heard about, about Spark] | |[I wish, wish Java, Java could, could use, use case, case classes]| |[Logistic regression, regression models, models are, are neat] | +------------------------------------------------------------------+ |
4.2.4 二值化
二值化,通过设置阀值,将连续型的特征转化为两个值。大于阀值为1,否则为0。
注:以下规范化操作一般是针对一个特征向量(dataFrame中的一个colum)来操作的。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import org.apache.spark.ml.feature.Binarizer val data = Array((0, 0.1), (1, 0.8), (2, 0.2)) val dataFrame = spark.createDataFrame(data).toDF("id", "feature") +---+-------+ | id|feature| +---+-------+ | 0| 0.1| | 1| 0.8| | 2| 0.2| +---+-------+ val binarizer: Binarizer = new Binarizer() .setInputCol("feature") .setOutputCol("binarized_feature") .setThreshold(0.5) val binarizedDataFrame = binarizer.transform(dataFrame) println(s"Binarizer output with Threshold = ${binarizer.getThreshold}") binarizedDataFrame.show() +---+-------+-----------------+ | id|feature|binarized_feature| +---+-------+-----------------+ | 0| 0.1| 0.0| | 1| 0.8| 1.0| | 2| 0.2| 0.0| +---+-------+-----------------+ |
4.2.5 主成分分析
主成分分析被广泛应用在各种统计学、机器学习问题中,是最常见的降维方法之一。
PCA在Spark2.0用法比较简单,只需要设置:
.setInputCol(“features”)//保证输入是特征值向量
.setOutputCol(“pcaFeatures”)//输出
.setK(3)//主成分个数
注意:PCA前一定要对特征向量进行规范化(标准化)!!!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
import org.apache.spark.ml.feature.PCA import org.apache.spark.ml.feature.PCAModel//不是mllib import org.apache.spark.ml.feature.StandardScaler import org.apache.spark.sql.Dataset import org.apache.spark.sql.Row import org.apache.spark.sql.SparkSession val rawDataFrame=spark.read.format("libsvm").load("file:///home/hadoop/bigdata/spark/data/mllib/sample_libsvm_data.txt") val scaledDataFrame=new StandardScaler() .setInputCol("features") .setOutputCol("scaledFeatures") .setWithMean(false)//对于稀疏数据(如本次使用的数据),不要使用平均值 .setWithStd(true) .fit(rawDataFrame) .transform(rawDataFrame) //PCA Model val pcaModel=new PCA().setInputCol("scaledFeatures") .setOutputCol("pcaFeatures") .setK(3)// .fit(scaledDataFrame) //进行PCA降维 pcaModel.transform(scaledDataFrame).select("label","pcaFeatures").show(10,false) //没有标准化特征向量,直接进行PCA主成分:各主成分之间值变化太大,有数量级的差别。 //标准化特征向量后PCA主成分,各主成分之间值基本上在同一水平上,结果更合理 +-----+-------------------------------------------------------------+ |label|pcaFeatures | +-----+-------------------------------------------------------------+ |0.0 |[-14.998868464839624,-10.137788261664621,-3.042873539670117] | |1.0 |[2.1965800525589754,-4.139257418439533,-11.386135042845101] | |1.0 |[1.0254645688925883,-0.8905813756164163,7.168759904518129] | |1.0 |[1.5069317554093433,-0.7289177578028571,5.23152743564543] | |1.0 |[1.6938250375084654,-0.4350617717494331,4.770263568537382] | |0.0 |[-15.870371979062549,-9.999445137658528,-6.521920373215663] //如何选择k值? val pcaModel=new PCA().setInputCol("scaledFeatures") .setOutputCol("pcaFeatures") .setK(50)// .fit(scaledDataFrame) var i=1 for( x<-pcaModel.explainedVariance.toArray){ println(i+"\t"+x+" ") i +=1 } //运行结果(前10行),随着k的增加,精度趋于平稳。 1 0.25934799275530857 2 0.12355355301486977 3 0.07447670060988294 4 0.0554545717486928 5 0.04207050513264405 6 0.03715986573644129 7 0.031350566055423544 8 0.027797304129489515 9 0.023825873477496748 10 0.02268054946233242 |
4.2.6 多项式展开
多项式展开(PolynomialExpansion)即通过产生n维组合将原始特征将特征扩展到多项式空间。下面的示例会介绍如何将你的特征集拓展到3维多项式空间。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
import org.apache.spark.ml.feature.PolynomialExpansion import org.apache.spark.ml.linalg.Vectors val data = Array( Vectors.dense(2.0, 1.0), Vectors.dense(0.0, 0.0), Vectors.dense(3.0, -1.0) ) val df = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features") val polyExpansion = new PolynomialExpansion() .setInputCol("features") .setOutputCol("polyFeatures") .setDegree(3) val polyDF = polyExpansion.transform(df) polyDF.show(false) +----------+------------------------------------------+ |features |polyFeatures | +----------+------------------------------------------+ |[2.0,1.0] |[2.0,4.0,8.0,1.0,2.0,4.0,1.0,2.0,1.0] | |[0.0,0.0] |[0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0] | |[3.0,-1.0]|[3.0,9.0,27.0,-1.0,-3.0,-9.0,1.0,3.0,-1.0]| +----------+------------------------------------------+ |
4.2.7 离散余弦变换
离散余弦变换(DCT)是与傅里叶变换相关的一种变换,它类似于离散傅立叶变换,但是只使用实数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
import org.apache.spark.ml.feature.DCT import org.apache.spark.ml.linalg.Vectors val data = Seq( Vectors.dense(0.0, 1.0, -2.0, 3.0), Vectors.dense(-1.0, 2.0, 4.0, -7.0), Vectors.dense(14.0, -2.0, -5.0, 1.0)) val df = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features") val dct = new DCT() .setInputCol("features") .setOutputCol("featuresDCT") .setInverse(false) val dctDf = dct.transform(df) dctDf.select("featuresDCT").show(false) +----------------------------------------------------------------+ |featuresDCT | +----------------------------------------------------------------+ |[1.0,-1.1480502970952693,2.0000000000000004,-2.7716385975338604]| |[-1.0,3.378492794482933,-7.000000000000001,2.9301512653149677] | |[4.0,9.304453421915744,11.000000000000002,1.5579302036357163] | +----------------------------------------------------------------+ |
4.2.8 字符串-索引变换
字符串—索引变换(StringIndexer)是将字符串列编码为标签索引列。示例数据为一个含有id和category两列的DataFrame
id | category
----|----------
0 | a
1 | b
2 | c
3 | a
4 | a
5 | c
category是有3种取值的字符串列(a、b、c),使用StringIndexer进行转换后我们可以得到如下输出,其中category作为输入列,categoryIndex作为输出列:
id | category | categoryIndex
----|----------|---------------
0 | a | 0.0
1 | b | 2.0
2 | c | 1.0
3 | a | 0.0
4 | a | 0.0
5 | c | 1.0
a获得索引0,因为它是最频繁的,随后是具有索引1的c和具有索引2的b。
如果测试数据集中比训练数据集多了一个d类:
id | category
----|----------
0 | a
1 | b
2 | c
3 | d
如果您没有设置StringIndexer如何处理未看见的标签(默认值)或将其设置为“错误”,则会抛出异常。 但是,如果您调用了setHandleInvalid(“skip”),d类将不出现,结果为以下数据集:
id | category | categoryIndex
----|----------|---------------
0 | a | 0.0
1 | b | 2.0
2 | c | 1.0
以下是使用StringIndexer的一个示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import org.apache.spark.ml.feature.StringIndexer val df = spark.createDataFrame( Seq((0, "a"), (1, "b"), (2, "c"), (3, "a"), (4, "a"), (5, "c")) ).toDF("id", "category") val indexer = new StringIndexer() .setInputCol("category") .setOutputCol("categoryIndex") val indexed = indexer.fit(df).transform(df) indexed.show() +---+--------+-------------+ | id|category|categoryIndex| +---+--------+-------------+ | 0| a| 0.0| | 1| b| 2.0| | 2| c| 1.0| | 3| a| 0.0| | 4| a| 0.0| | 5| c| 1.0| +---+--------+-------------+ |
4.2.9 索引-字符串变换
与StringIndexer对应,索引—字符串变换(IndexToString)是将指标标签映射回原始字符串标签。
id | categoryIndex
----|---------------
0 | 0.0
1 | 2.0
2 | 1.0
3 | 0.0
4 | 0.0
5 | 1.0
应用IndexToString,将categoryIndex作为输入列,将originalCategory作为输出列,我们可以检索我们的原始标签(它们将从列的元数据中推断):
id | categoryIndex | originalCategory
----|---------------|-----------------
0 | 0.0 | a
1 | 2.0 | b
2 | 1.0 | c
3 | 0.0 | a
4 | 0.0 | a
5 | 1.0 | c
以下是以上整个过程的一个实例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
import org.apache.spark.ml.attribute.Attribute import org.apache.spark.ml.feature.{IndexToString, StringIndexer} val df = spark.createDataFrame(Seq( (0, "a"), (1, "b"), (2, "c"), (3, "a"), (4, "a"), (5, "c") )).toDF("id", "category") val indexer = new StringIndexer() .setInputCol("category") .setOutputCol("categoryIndex") .fit(df) val indexed = indexer.transform(df) println(s"Transformed string column '${indexer.getInputCol}' " + s"to indexed column '${indexer.getOutputCol}'") indexed.show() val inputColSchema = indexed.schema(indexer.getOutputCol) println(s"StringIndexer will store labels in output column metadata: " + s"${Attribute.fromStructField(inputColSchema).toString}\n") val converter = new IndexToString() .setInputCol("categoryIndex") .setOutputCol("originalCategory") val converted = converter.transform(indexed) println(s"Transformed indexed column '${converter.getInputCol}' back to original string " + s"column '${converter.getOutputCol}' using labels in metadata") converted.select("id", "categoryIndex", "originalCategory").show() |
4.2.10 独热编码
独热编码(OneHotEncoder)将标签指标映射为二值向量,其中最多一个单值。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
import org.apache.spark.ml.feature.{OneHotEncoder, StringIndexer} val df = spark.createDataFrame(Seq( (0, "a"), (1, "b"), (2, "c"), (3, "a"), (4, "a"), (5, "c") )).toDF("id", "category") val indexer = new StringIndexer() .setInputCol("category") .setOutputCol("categoryIndex") .fit(df) val indexed = indexer.transform(df) val encoder = new OneHotEncoder() .setInputCol("categoryIndex") .setOutputCol("categoryVec") .setDropLast(false) val encoded = encoder.transform(indexed) encoded.show() |
【说明】
1、OneHotEncoder缺省状态下将删除最后一个分类或把最后一个分类作为0.
//示例
|
1 2 3 4 5 6 |
import org.apache.spark.ml.feature.{OneHotEncoder, StringIndexer} val fd = spark.createDataFrame( Seq((1.0, "a"), (1.5, "a"), (10.0, "b"), (3.2, "c"),(3.8,"c"))).toDF("x","c") val ss =new StringIndexer().setInputCol("c").setOutputCol("c_idx") val ff = ss.fit(fd).transform(fd) ff.show() |
显示结果如下:
+----+---+-----+
| x| c|c_idx|
+----+---+-----+
| 1.0| a| 0.0|
| 1.5| a| 0.0|
|10.0| b| 2.0|
| 3.2| c| 1.0|
| 3.8| c| 1.0|
+----+---+-----+
最后一个分类为b,通过OneHotEncoder变为向量后,已被删除。
|
1 2 3 |
val oe = new OneHotEncoder().setInputCol("c_idx").setOutputCol("c_idx_vec") val fe = oe.transform(ff) fe.show() |
显示结果如下:
+----+---+-----+-------------+
| x| c|c_idx| c_idx_vec|
+----+---+-----+-------------+
| 1.0| a| 0.0|(2,[0],[1.0])|
| 1.5| a| 0.0|(2,[0],[1.0])|
|10.0| b| 2.0| (2,[],[])|
| 3.2| c| 1.0|(2,[1],[1.0])|
| 3.8| c| 1.0|(2,[1],[1.0])|
+----+---+-----+-------------+
与其他特征组合为特征向量后,将置为0,请看下例
|
1 2 3 |
val assembler = new VectorAssembler().setInputCols(Array("x", "c_idx", "c_idx_vec")).setOutputCol("features") val vecDF: DataFrame = assembler.transform(fe) vecDF.show(false) |
显示结果如下:
+----+---+-----+-------------+------------------+
|x |c |c_idx|c_idx_vec |features |
+----+---+-----+-------------+------------------+
|1.0 |a |0.0 |(2,[0],[1.0])|[1.0,0.0,1.0,0.0] |
|1.5 |a |0.0 |(2,[0],[1.0])|[1.5,0.0,1.0,0.0] |
|10.0|b |2.0 |(2,[],[]) |[10.0,2.0,0.0,0.0]|
|3.2 |c |1.0 |(2,[1],[1.0])|[3.2,1.0,0.0,1.0] |
|3.8 |c |1.0 |(2,[1],[1.0])|[3.8,1.0,0.0,1.0] |
+----+---+-----+-------------+------------------+
如果想不删除最后一个分类,可添加setDropLast(False)。
|
1 2 3 |
oe.setDropLast(false) val fl = oe.transform(ff) fl.show() |
显示结果如下:
+----+---+-----+-------------+
| x| c|c_idx| c_idx_vec|
+----+---+-----+-------------+
| 1.0| a| 0.0|(3,[0],[1.0])|
| 1.5| a| 0.0|(3,[0],[1.0])|
|10.0| b| 2.0|(3,[2],[1.0])|
| 3.2| c| 1.0|(3,[1],[1.0])|
| 3.8| c| 1.0|(3,[1],[1.0])|
+----+---+-----+-------------+
与其他特征向量结合后,情况如下:
|
1 2 |
val vecDFl: DataFrame = assembler.transform(fl) vecDFl.show(false) |
显示结果如下:
+----+---+-----+-------------+----------------------+
|x |c |c_idx|c_idx_vec |features |
+----+---+-----+-------------+----------------------+
|1.0 |a |0.0 |(3,[0],[1.0])|(5,[0,2],[1.0,1.0]) |
|1.5 |a |0.0 |(3,[0],[1.0])|(5,[0,2],[1.5,1.0]) |
|10.0|b |2.0 |(3,[2],[1.0])|[10.0,2.0,0.0,0.0,1.0]|
|3.2 |c |1.0 |(3,[1],[1.0])|[3.2,1.0,0.0,1.0,0.0] |
|3.8 |c |1.0 |(3,[1],[1.0])|[3.8,1.0,0.0,1.0,0.0] |
+----+---+-----+-------------+----------------------+
2、如果分类中出现空字符,需要进行处理,如设置为"None",否则会报错。
4.2.11 向量-索引变换
在下面的例子中,我们读取一个标记点的数据集,然后使用VectorIndexer来决定哪些特征应该被视为分类。我们将分类特征值转换为它们的索引。这个变换的数据然后可以被传递到诸如DecisionTreeRegressor的处理分类特征的算法。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import org.apache.spark.ml.feature.VectorIndexer val data = spark.read.format("libsvm").load("file:///home/hadoop/bigdata/spark/data/mllib/sample_libsvm_data.txt") val indexer = new VectorIndexer() .setInputCol("features") .setOutputCol("indexed") .setMaxCategories(10) val indexerModel = indexer.fit(data) val categoricalFeatures: Set[Int] = indexerModel.categoryMaps.keys.toSet println(s"Chose ${categoricalFeatures.size} categorical features: " + categoricalFeatures.mkString(", ")) // Create new column "indexed" with categorical values transformed to indices val indexedData = indexerModel.transform(data) indexedData.show() +-----+--------------------+--------------------+ |label| features| indexed| +-----+--------------------+--------------------+ | 0.0|(692,[127,128,129...|(692,[127,128,129...| | 1.0|(692,[158,159,160...|(692,[158,159,160...| | 1.0|(692,[124,125,126...|(692,[124,125,126...| | 1.0|(692,[152,153,154...|(692,[152,153,154...| | 1.0|(692,[151,152,153...|(692,[151,152,153...| | 0.0|(692,[129,130,131...|(692,[129,130,131...| |
4.2.12交互式
例子,假设我们有以下DataFrame的列“id1”,“vec1”和“vec2”
id1|vec1 |vec2
---|--------------|--------------
1 |[1.0,2.0,3.0] |[8.0,4.0,5.0]
2 |[4.0,3.0,8.0] |[7.0,9.0,8.0]
3 |[6.0,1.0,9.0] |[2.0,3.0,6.0]
4 |[10.0,8.0,6.0]|[9.0,4.0,5.0]
5 |[9.0,2.0,7.0] |[10.0,7.0,3.0]
6 |[1.0,1.0,4.0] |[2.0,8.0,4.0]
应用与这些输入列的交互,然后interactionedCol作为输出列包含:
id1|vec1 |vec2 |interactedCol
---|--------------|--------------|------------------------------------------------------
1 |[1.0,2.0,3.0] |[8.0,4.0,5.0] |[8.0,4.0,5.0,16.0,8.0,10.0,24.0,12.0,15.0]
2 |[4.0,3.0,8.0] |[7.0,9.0,8.0] |[56.0,72.0,64.0,42.0,54.0,48.0,112.0,144.0,128.0]
3 |[6.0,1.0,9.0] |[2.0,3.0,6.0] |[36.0,54.0,108.0,6.0,9.0,18.0,54.0,81.0,162.0]
4 |[10.0,8.0,6.0]|[9.0,4.0,5.0] |[360.0,160.0,200.0,288.0,128.0,160.0,216.0,96.0,120.0]
5 |[9.0,2.0,7.0] |[10.0,7.0,3.0]|[450.0,315.0,135.0,100.0,70.0,30.0,350.0,245.0,105.0]
6 |[1.0,1.0,4.0] |[2.0,8.0,4.0] |[12.0,48.0,24.0,12.0,48.0,24.0,48.0,192.0,96.0]
以下是实现以上转换的具体代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
import org.apache.spark.ml.feature.Interaction import org.apache.spark.ml.feature.VectorAssembler val df = spark.createDataFrame(Seq( (1, 1, 2, 3, 8, 4, 5), (2, 4, 3, 8, 7, 9, 8), (3, 6, 1, 9, 2, 3, 6), (4, 10, 8, 6, 9, 4, 5), (5, 9, 2, 7, 10, 7, 3), (6, 1, 1, 4, 2, 8, 4) )).toDF("id1", "id2", "id3", "id4", "id5", "id6", "id7") val assembler1 = new VectorAssembler(). setInputCols(Array("id2", "id3", "id4")). setOutputCol("vec1") val assembled1 = assembler1.transform(df) val assembler2 = new VectorAssembler(). setInputCols(Array("id5", "id6", "id7")). setOutputCol("vec2") val assembled2 = assembler2.transform(assembled1).select("id1", "vec1", "vec2") val interaction = new Interaction() .setInputCols(Array("id1", "vec1", "vec2")) .setOutputCol("interactedCol") val interacted = interaction.transform(assembled2) interacted.show(truncate = false) |
4.2.13正则化
以下示例演示如何加载libsvm格式的数据集,然后将每行标准化为具有单位L1范数和单位L∞范数。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
import org.apache.spark.ml.feature.Normalizer import org.apache.spark.ml.linalg.Vectors val dataFrame = spark.createDataFrame(Seq( (0, Vectors.dense(1.0, 0.5, -1.0)), (1, Vectors.dense(2.0, 1.0, 1.0)), (2, Vectors.dense(4.0, 10.0, 2.0)) )).toDF("id", "features") // 使用L^1正规化向量 val normalizer = new Normalizer() .setInputCol("features") .setOutputCol("normFeatures") .setP(1.0) val l1NormData = normalizer.transform(dataFrame) println("Normalized using L^1 norm") l1NormData.show() //使用L^∞正规化向量.. val lInfNormData = normalizer.transform(dataFrame, normalizer.p -> Double.PositiveInfinity) println("Normalized using L^inf norm") lInfNormData.show() |
4.2.14规范化(StandardScaler)
以下示例演示如何以libsvm格式加载数据集,然后规范化每个要素的单位标准偏差。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import org.apache.spark.ml.feature.StandardScaler val dataFrame = spark.read.format("libsvm").load("file:///u01/bigdata/spark/data/mllib/sample_libsvm_data.txt") val scaler = new StandardScaler() .setInputCol("features") .setOutputCol("scaledFeatures") .setWithStd(true) .setWithMean(false) //通过拟合StandardScaler来计算汇总统计 val scalerModel = scaler.fit(dataFrame) //标准化每个特征使其有单位标准偏差 val scaledData = scalerModel.transform(dataFrame) scaledData.show() |
4.2.15最大值-最小值缩放
下面的示例展示如果读入一个libsvm形式的数据以及调整其特征值到[0,1]之间。
调用示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import org.apache.spark.ml.feature.MinMaxScaler import org.apache.spark.ml.linalg.Vectors val dataFrame = spark.createDataFrame(Seq( (0, Vectors.dense(1.0, 0.1, -1.0)), (1, Vectors.dense(2.0, 1.1, 1.0)), (2, Vectors.dense(3.0, 10.1, 3.0)) )).toDF("id", "features") val scaler = new MinMaxScaler() .setInputCol("features") .setOutputCol("scaledFeatures") //进行汇总统计并生成MinMaxScalerModel val scalerModel = scaler.fit(dataFrame) //将每个特征重新缩放至[min,max]范围 val scaledData = scalerModel.transform(dataFrame) println(s"Features scaled to range: [${scaler.getMin}, ${scaler.getMax}]") scaledData.select("features", "scaledFeatures").show() |
显示结果如下:
Features scaled to range: [0.0, 1.0]
+--------------+--------------+
| features|scaledFeatures|
+--------------+--------------+
|[1.0,0.1,-1.0]| [0.0,0.0,0.0]|
| [2.0,1.1,1.0]| [0.5,0.1,0.5]|
|[3.0,10.1,3.0]| [1.0,1.0,1.0]|
+--------------+--------------+
4.2.16最大值-绝对值缩放
以下示例演示如何加载libsvm格式的数据集,然后将每个特征重新缩放到[-1,1]。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import org.apache.spark.ml.feature.MaxAbsScaler import org.apache.spark.ml.linalg.Vectors val dataFrame = spark.createDataFrame(Seq( (0, Vectors.dense(1.0, 0.1, -8.0)), (1, Vectors.dense(2.0, 1.0, -4.0)), (2, Vectors.dense(4.0, 10.0, 8.0)) )).toDF("id", "features") val scaler = new MaxAbsScaler() .setInputCol("features") .setOutputCol("scaledFeatures") // 进行汇总统计并生成MaxAbsScalerModel val scalerModel = scaler.fit(dataFrame) // rescale each feature to range [-1, 1] val scaledData = scalerModel.transform(dataFrame) scaledData.select("features", "scaledFeatures").show() |
运行结果如下:
+--------------+----------------+
| features| scaledFeatures|
+--------------+----------------+
|[1.0,0.1,-8.0]|[0.25,0.01,-1.0]|
|[2.0,1.0,-4.0]| [0.5,0.1,-0.5]|
|[4.0,10.0,8.0]| [1.0,1.0,1.0]|
+--------------+----------------+
4.2.17离散化重组
以下示例演示如何将双列列存储到另一个索引列的列中。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import org.apache.spark.ml.feature.Bucketizer val splits = Array(Double.NegativeInfinity, -0.5, 0.0, 0.5, Double.PositiveInfinity) val data = Array(-999.9, -0.5, -0.3, 0.0, 0.2, 999.9) val dataFrame = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features") val bucketizer = new Bucketizer() .setInputCol("features") .setOutputCol("bucketedFeatures") .setSplits(splits) // 把原来的数据转换为箱式索引 val bucketedData = bucketizer.transform(dataFrame) println(s"Bucketizer output with ${bucketizer.getSplits.length-1} buckets") bucketedData.show() |
运行结果如下:
+--------+----------------+
|features|bucketedFeatures|
+--------+----------------+
| -999.9| 0.0|
| -0.5| 1.0|
| -0.3| 1.0|
| 0.0| 2.0|
| 0.2| 2.0|
| 999.9| 3.0|
+--------+----------------+
4.2.18元素乘积
下面的示例演示了如何使用变换向量值来变换向量
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import org.apache.spark.ml.feature.ElementwiseProduct import org.apache.spark.ml.linalg.Vectors //创建一些向量数据; 也适用于稀疏向量。 val dataFrame = spark.createDataFrame(Seq( ("a", Vectors.dense(1.0, 2.0, 3.0)), ("b", Vectors.dense(4.0, 5.0, 6.0)))).toDF("id", "vector") val transformingVector = Vectors.dense(0.0, 1.0, 2.0) val transformer = new ElementwiseProduct() .setScalingVec(transformingVector) .setInputCol("vector") .setOutputCol("transformedVector") //创建新列,可批量转换向量。 transformer.transform(dataFrame).show() |
运行结果如下:
+---+-------------+-----------------+
| id| vector|transformedVector|
+---+-------------+-----------------+
| a|[1.0,2.0,3.0]| [0.0,2.0,6.0]|
| b|[4.0,5.0,6.0]| [0.0,5.0,12.0]|
+---+-------------+-----------------+
4.2.19 SQL转换器
假设我们有以下DataFrame和列id,v1和v2
id | v1 | v2
----|-----|-----
0 | 1.0 | 3.0
2 | 2.0 | 5.0
这是SQLTransformer "SELECT *, (v1 + v2) AS v3, (v1 * v2) AS v4 FROM __THIS__":语句的输出。
id | v1 | v2 | v3 | v4
----|-----|-----|-----|-----
0 | 1.0 | 3.0 | 4.0 | 3.0
2 | 2.0 | 5.0 | 7.0 |10.0
以下是实现以上结果的具体代码:
|
1 2 3 4 5 6 7 8 9 |
import org.apache.spark.ml.feature.SQLTransformer val df = spark.createDataFrame( Seq((0, 1.0, 3.0), (2, 2.0, 5.0))).toDF("id", "v1", "v2") val sqlTrans = new SQLTransformer().setStatement( "SELECT *, (v1 + v2) AS v3, (v1 * v2) AS v4 FROM __THIS__") sqlTrans.transform(df).show() |
4.2.20向量汇编
例子
假设我们有一个带有id,hour,mobile,userFeatures和clicked列的DataFrame:
id | hour | mobile | userFeatures | clicked
----|------|--------|------------------|---------
0 | 18 | 1.0 | [0.0, 10.0, 0.5] | 1.0
userFeatures是一个包含三个用户特征的向量列。我们希望将hour,mobile和userFeatures合并成一个称为特征的单一特征向量,并使用它来预测是否被点击。如果我们将VectorAssembler的输入列设置为hour,mobile和userFeatures,并将列输出到特征,则在转换后,我们应该得到以下DataFrame:
id | hour | mobile | userFeatures | clicked | features
----|------|--------|------------------|---------|-----------------------------
0 | 18 | 1.0 | [0.0, 10.0, 0.5] | 1.0 | [18.0, 1.0, 0.0, 10.0, 0.5]
以下是实现上述功能的代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import org.apache.spark.ml.feature.VectorAssembler import org.apache.spark.ml.linalg.Vectors val dataset = spark.createDataFrame( Seq((0, 18, 1.0, Vectors.dense(0.0, 10.0, 0.5), 1.0)) ).toDF("id", "hour", "mobile", "userFeatures", "clicked") val assembler = new VectorAssembler() .setInputCols(Array("hour", "mobile", "userFeatures")) .setOutputCol("features") val output = assembler.transform(dataset) println("Assembled columns 'hour', 'mobile', 'userFeatures' to vector column 'features'") output.select("features", "clicked").show(false) |
4.2.21分位数离散化
示例:
假设我们有如下DataFrame包含id,hour:
id | hour
----|------
0 | 18.0
----|------
1 | 19.0
----|------
2 | 8.0
----|------
3 | 5.0
----|------
4 | 2.2
hour是Double类型的连续特征。我们希望将连续特征变成一个分级特征。给定numBuckets = 3,我们可得到以下DataFrame:
id | hour | result
----|------|------
0 | 18.0 | 2.0
----|------|------
1 | 19.0 | 2.0
----|------|------
2 | 8.0 | 1.0
----|------|------
3 | 5.0 | 1.0
----|------|------
4 | 2.2 | 0.0
实现以上功能的scala代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import org.apache.spark.ml.feature.QuantileDiscretizer val data = Array((0, 18.0), (1, 19.0), (2, 8.0), (3, 5.0), (4, 2.2)) val df = spark.createDataFrame(data).toDF("id", "hour") val discretizer = new QuantileDiscretizer() .setInputCol("hour") .setOutputCol("result") .setNumBuckets(3) val result = discretizer.fit(df).transform(df) result.show() |
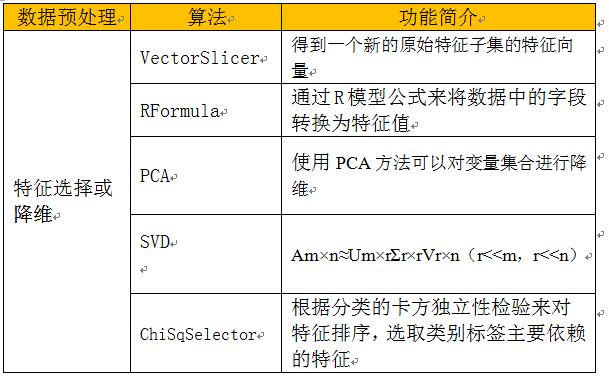
4.3 特征选择
特征选择(Feature Selection)是从特征向量中选择那些更有效的特征,组成新的、更简单有效的特征向量的过程。它在数据分析中常用使用,尤其在高维数据分析中,可以剔除冗余或影响不大的特征,提升模型的性能。
4.3.1 向量机
假设我们有一个DataFrame与列userFeatures:
userFeatures
------------------
[0.0, 10.0, 0.5]
userFeatures是一个包含三个用户特征的向量列。假设userFeature的第一列全部为零,因此我们要删除它并仅选择最后两列。 VectorSlicer使用setIndices(1,2)选择最后两个元素,然后生成一个名为features的新向量列:
userFeatures | features
------------------|-----------------------------
[0.0, 10.0, 0.5] | [10.0, 0.5]
假设userFeatures有输入属性,如[“f1”,“f2”,“f3”],那么我们可以使用setNames(“f2”,“f3”)来选择它们。
userFeatures | features
------------------|-----------------------------
[0.0, 10.0, 0.5] | [10.0, 0.5]
["f1", "f2", "f3"] | ["f2", "f3"]
以下是实现向量选择的一个scala代码示例
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import org.apache.spark.sql.Row import org.apache.spark.sql.types.StructType val data = Arrays.asList( Row(Vectors.sparse(3, Seq((0, -2.0), (1, 2.3)))), Row(Vectors.dense(-2.0, 2.3, 0.0)) ) val defaultAttr = NumericAttribute.defaultAttr val attrs = Array("f1", "f2", "f3").map(defaultAttr.withName) val attrGroup = new AttributeGroup("userFeatures", attrs.asInstanceOf[Array[Attribute]]) val dataset = spark.createDataFrame(data, StructType(Array(attrGroup.toStructField()))) val slicer = new VectorSlicer().setInputCol("userFeatures").setOutputCol("features") slicer.setIndices(Array(1)).setNames(Array("f3")) // or slicer.setIndices(Array(1, 2)), or slicer.setNames(Array("f2", "f3")) val output = slicer.transform(dataset) output.show(false) |
运行结果:
+--------------------+-------------+
|userFeatures |features |
+--------------------+-------------+
|(3,[0,1],[-2.0,2.3])|(2,[0],[2.3])|
|[-2.0,2.3,0.0] |[2.3,0.0] |
+--------------------+-------------+
4.3.2 R公式
示例:
假设我们有一个DataFrame含有id,country, hour和clicked四列:
id | country |hour | clicked
---|---------|------|---------
7 | "US" | 18 | 1.0
8 | "CA" | 12 | 0.0
9 | "NZ" | 15 | 0.0
如果我们使用RFormula公式clicked ~ country+ hour,则表明我们希望基于country和hour预测clicked,通过转换我们可以得到如下DataFrame:
id | country |hour | clicked | features | label
---|---------|------|---------|------------------|-------
7 | "US" | 18 | 1.0 | [0.0, 0.0, 18.0] | 1.0
8 | "CA" | 12 | 0.0 | [0.0, 1.0, 12.0] | 0.0
9 | "NZ" | 15 | 0.0 | [1.0, 0.0, 15.0] | 0.0
以下是实现上述功能的scala代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import org.apache.spark.ml.feature.RFormula val dataset = spark.createDataFrame(Seq( (7, "US", 18, 1.0), (8, "CA", 12, 0.0), (9, "NZ", 15, 0.0) )).toDF("id", "country", "hour", "clicked") val formula = new RFormula() .setFormula("clicked ~ country + hour") .setFeaturesCol("features") .setLabelCol("label") val output = formula.fit(dataset).transform(dataset) output.select("features", "label").show() |
4.3.3 卡方特征选择
示例:
假设我们有一个DataFrame含有id,features和clicked三列,其中clicked为需要预测的目标:
id | features | clicked
---|-----------------------|---------
7 | [0.0, 0.0, 18.0, 1.0] | 1.0
8 | [0.0, 1.0, 12.0, 0.0] | 0.0
9 | [1.0, 0.0, 15.0, 0.1] | 0.0
如果我们使用ChiSqSelector并设置numTopFeatures为1,根据标签clicked,features中最后一列将会是最有用特征:
id | features | clicked | selectedFeatures
---|-----------------------|---------|------------------
7 | [0.0, 0.0, 18.0, 1.0] | 1.0 | [1.0]
8 | [0.0, 1.0, 12.0, 0.0] | 0.0 | [0.0]
9 | [1.0, 0.0, 15.0, 0.1] | 0.0 | [0.1]
使用ChiSqSelector的scala代码示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import org.apache.spark.ml.feature.ChiSqSelector import org.apache.spark.ml.linalg.Vectors val data = Seq( (7, Vectors.dense(0.0, 0.0, 18.0, 1.0), 1.0), (8, Vectors.dense(0.0, 1.0, 12.0, 0.0), 0.0), (9, Vectors.dense(1.0, 0.0, 15.0, 0.1), 0.0) ) val df = spark.createDataset(data).toDF("id", "features", "clicked") val selector = new ChiSqSelector() .setNumTopFeatures(1) .setFeaturesCol("features") .setLabelCol("clicked") .setOutputCol("selectedFeatures") val result = selector.fit(df).transform(df) println(s"ChiSqSelector output with top ${selector.getNumTopFeatures} features selected") result.show() |
结果显示:
+---+------------------+-------+----------------+
| id| features|clicked|selectedFeatures|
+---+------------------+-------+----------------+
| 7|[0.0,0.0,18.0,1.0]| 1.0| [18.0]|
| 8|[0.0,1.0,12.0,0.0]| 0.0| [12.0]|
| 9|[1.0,0.0,15.0,0.1]| 0.0| [15.0]|
+---+------------------+-------+----------------+
4.4 小结
本章主要介绍了对数据特征或变量的一些常用操作,包括特征提取,特征转换以及特征选择等方法,这些任务在实际项目中往往花费大量时间和精力,尤其要自己编写这方面的代码或函数,更是如此,Spark ML目前提供了很多现成函数,有效使用这些函数将有助于提供我们开发效率,同时使我们有更多时间优化或提升模型性能。下一章我们将介绍优化或提升模型性能一些方法。