第7章 面向对象编程
7.1 问题:如何实现不重复造轮子?
7.2 类与实例
在面向对象编程中,首先编写类,然后,基于类创建实例对象,并根据需要给每个对象一些其它特性。
7.2.1 创建类
创建类的格式如下:
class class_name:
'''类的帮助信息''' #类文档字符串
statement #类体
定义类无需def关键字,类名后也无需小括号(),如果要继承其它类,要添加小括号,类的继承后面将介绍。
下面以创建表示人的类,它保存人的基本信息及使用这些信息的方法。
|
1 2 3 4 5 6 7 8 9 |
#创建一个表示人的类 class Person: '''表示人的基本信息''' #定义类的构造函数,初始化类的基本信息 def __init__(self,name,age): self.name= name self.age=age def display(self): print("person(姓名:{},年龄:{})".format(self.name,self.age)) |
创建类要注意的几个问题:
①按约定,在Python中,类的首字母一般大写
②方法__init__()
类中的函数称为方法,__init__()是一个特殊方法,init的前后都是两个下划线,被称为类的构造函数或初始化方法,实例化类时将自动调用该方法。
在方法__init__()中,有三个形参,分别是self、name、age,其中self表示实例本身,而且必须放在其它形参的前面,调用方法时,该参数将自动传入,所以调用方法时,无需写这个实参。self与实例的关系,如图7-1所示。
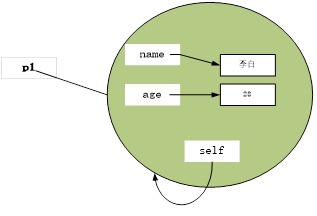
图7-1 self表示实例本身
③形参name、age
把这两个形参,分别赋给两个带self前缀的两个变量,即self.name、self.age。带self前缀的变量,将与实例绑定,类中的所有方法都可调用它们。这样的变量又称为实例属性。
④方法display()
方法display()只有一个self形参,它引用了两个实例属性。
7.2.2 创建类的实例
其它编程语言实例化类一般用关键字 new,但在 Python 中无需这个关键字,类的实例化类似函数调用方式。以下将类Person实例化,并通过 __init__() 方法接收参数、初始化参数。
|
1 2 |
#创建第一个实例 p1=Person("李白",28) |
根据类Person创建实例p1,使用实参"李白",28调用方法__init__()。访问实例中的方法或属性,使用实例名加句点的方法即可,比如方法name属性及display()方法。
|
1 2 3 4 |
#访问实例属性 p1.name #'李白' #调用实例方法 p1.display() #person(姓名:李白,年龄:28) |
根据实参可以创建不同的实例
|
1 2 3 4 5 6 7 |
#创建第二个实例 p2=Person("欧阳修",30) #访问实例属性 print(p2.name) print(p2.age) #调用实例方法 p2.display() |
7.2.3 访问属性
属性根据在类中定义的位置,又可分为类的属性和实例属性。类属性是定义在类中,但在各方法外的属性。实例属性是方法内,带self前缀的属性。
(1)创建类
在类Person定义一个类属性percount,如下列代码。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#创建一个表示人的类 class Person: '''表示人的基本信息''' pernum=0 #类属性 #定义类的构造函数,初始化类的基本信息 def __init__(self,name,age): self.name= name self.age=age Person.pernum+=1 def display(self): self.state=10 print("person(姓名:{},年龄:{})".format(self.name,self.age)) def display_pernum(self): print(self.state) print(Person.pernum) |
(2)实例化并访问类属性和实例属性
|
1 2 3 4 5 6 7 |
p3=Person("杜甫",32) #实例化 print(p3.pernum) #通过实例访问类属性 p3.display_pernum() #调用实例方法 p4=Person("王安石",42) #实例化 print(Person.pernum) #通过类名访问类属性 print(p4.pernum) #通过实例访问类属性 p4.display_pernum() #调用实例方法 |
类属性可以通过类名或实例名访问。
7.2.4 访问限制
类Person中pernum是类的属性,因各实例都可访问,又称为类的公有属性,公有属性各实例可以访问,也可以修改。如下例
|
1 2 |
p5.pernum=10 print(p5.pernum) #10 |
这样对一些属性就不安全了,为了提高一些类属性或实例属性的安全级别,可以设置私有属性,只要命名时,加上两个下划线为前缀即可,如:__percount。私有属性只能在类内部访问,实例不能访问。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
class Person: '''表示人的基本信息''' pernum=0 #类属性 __percount=1000 #定义类的私有属性 #定义类的构造函数,初始化类的基本信息 def __init__(self,name,age): self.name= name self.age=age Person.pernum+=1 self.__pwd=123456 ##实例私有属性 def display(self): print("person(姓名:{},年龄:{})".format(self.name,self.age)) def display_pernum(self): print(Person.pernum) |
类的私有属性__percount、实例的私有属性__pwd只能在类的内部使用,实例及类的外部不能访问。
7.2.5类的专有方法
__init__ : 构造函数,在生成对象时调用
__del__ : 析构函数,释放对象时使用
7.3 继承
继承是面向对象的重要特征之一,继承是两个类或者多个类之间的父子关系,子进程继承了父进程的所有公有实例变量和方法。继承实现了代码的重用。重用已经存在的数据和行为,减少代码的重新编写,python在类名后用一对圆括号表示继承关系, 括号中的类表示父类,如果父类定义了__init__方法。带双下划线 __ 的方法都是特殊方法,除了 __init__ 还有很多,几乎所有的特殊方法(包括 __init__)都是隐式调用的(不直接调用)。则子类必须显示地调用父类的__init__方法,如果子类需要扩展父类的行为,可以添加__init__方法的参数。下面演示继承的实现
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
class Fruit: def __init__(self, color): self.color = color print("fruit's color: %s"%self.color) def grow(self): print("grow ...") class Apple(Fruit): #继承了父类 def __init__(self,color): #显示调用父类的__init__方法 #Fruit.__init__(self, color) super().__init__(color) print("apple's color: %s"% self.color) class Banana(Fruit): #继承了父类 def __init__(self, color): #显示调用父类的__init__方法 Fruit.__init__(self, color) print("banana's color: %s"% self.color) def grow(self): #覆盖了父类的grow方法 print("banana grow...") if __name__ == "__main__": apple = Apple("red") apple.grow() banana = Banana("yellow") banana.grow() |
运行结果:
fruit's color: red
apple's color: red
grow ...
fruit's color: yellow
banana's color: yellow
banana grow...
7.4 调用父类的init方法
子类(派生类)并不会自动调用父类(基类)的init方法,需要在子类中调用父类的init函数。
(1)如果子类没有定义自己的初始化函数,父类的初始化函数会被默认调用;但是如果要实例化子类的对象,则只能传入父类的初始化函数对应的参数,否则会出错。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#定义父类:Parent class Parent(object): def __init__(self, name): self.name = name print("create an instance of:", self.__class__.__name__) print("name attribute is:", self.name) #定义子类Child ,继承父类Parent class Child(Parent): pass #子类实例化时,由于子类没有初始化,此时父类的初始化函数就会默认被调用 #且必须传入父类的参数name c = Child("init Child") |
(2)如果子类定义了自己的初始化函数,而在子类中没有显示调用父类的初始化函数,则父类的属性不会被初始化
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
class Parent(object): def __init__(self, name): self.name = name print("create an instance of:", self.__class__.__name__) print("name attribute is:", self.name) #子类继承父类 class Child(Parent): #子类中没有显示调用父类的初始化函数 def __init__(self): print("call __init__ from Child class") #c = Child("init Child") #print() #将子类实例化 c = Child() print(c.name) #将报错'Child' object has no attribute 'name' |
在子类中没有显示调用父类的初始化函数,则父类的属性不会被初始化,因而此时调用子类中name属性不存在:
AttributeError: ‘Child’ object has no attribute ‘name’
(3)如果子类定义了自己的初始化函数,在子类中显示调用父类,子类和父类的属性都会被初始化。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
class Parent(object): def __init__(self, name): self.name = name print("create an instance of:", self.__class__.__name__) print("name attribute is:", self.name) class Child(Parent): def __init__(self): print("call __init__ from Child class") super(Child,self).__init__("data from Child") #要将子类Child和self传递进去 #c = Child("init Child") #print() d = Parent('tom') c = Child() print(c.name) |
子类定义了自己的初始化函数,显示调用父类,子类和父类的属性都会被初始化的输出结果:
create an instance of: Parent
name attribute is: tom
call __init__ from Child class
create an instance of: Child
name attribute is: data from Child
data from Child
(4) 调用父类的init方法
方法1,父类名硬编码到子类
|
1 2 3 4 5 6 7 8 9 10 |
class Foo(object): def __init__(self): self.val = 1 class Foo2(Foo): def __init__(self): Foo.__init__(self) print(self.val) if __name__ == '__main__': foo2 = Foo2() |
方法2,利用super调用
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
class FooParent(object): def __init__(self): self.parent = 'I\'m the parent.' print ('Parent') def bar(self,message): print ("%s from Parent" % message) class FooChild(FooParent): def __init__(self): # super(FooChild,self) 首先找到 FooChild 的父类(就是类 FooParent),然后把 FooChild 转换为类 FooParent 的对象 super(FooChild,self).__init__() print ('Child') def bar(self,message): super(FooChild, self).bar(message) print ('Child bar fuction') print (self.parent) if __name__ == '__main__': fooChild = FooChild() fooChild.bar('HelloWorld') |
运行结果
Parent
Child
HelloWorld from Parent
Child bar fuction
I'm the parent.
7.5 把类放在模块中
为了永久保存函数,需要把函数存放在模块中。同样,要保存类,也需要把定义类的脚本保存到模块中,使用时,根据需要导入相关内容。
7.5.1 导入类
把定义类Person及Student的代码,保存在当前目录的文件名为class_person的py文件中。通过import语句可以导入我们需要的类或方法或属性等。
|
1 2 3 4 5 6 |
#导入模块中Student类 from class_person import Student as st #实例化类 s2=st("江东",23,"清华大学") #调用s2中实例方法 s2.display() #Student(姓名:江东,年龄:23,所在大学:清华大学) |
7.5.2 在一模块中导入另一个模块
创建名为train_class.py的主程序,存放在当前目录下,在主程序中导入模块class_person中的Student类,具体代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
#导入模块class_person中的Student类 from class_person import * def main(): #输入一所大学名称 str=input("输入一所大学名称: ") #实例化st类 s1=st("张华",21,str) #调用display方法 s1.display() ##判断是否以主程序形式运行 if __name__=='__main__': main() |
在命令行运行该主程序:
|
1 2 3 4 5 |
$python train_class.py 输入一所大学名称: 清华大学 Student(姓名:张华,年龄:21,所在大学:清华大学) 在Jupyter notebook运行该主程序 |
|
1 |
run train_class.py |
输入一所大学名称: 清华大学
Student(姓名:张华,年龄:21,所在大学:清华大学)
7.6 实例1:使用类和包
这节通过几个实例来加深大家对Python相关概念的理解和使用。
7.6.1 概述
创建一个Person父类,两个继承这个父类的子类:Student和Tencher,它们之间的关系如图7-3 所示。

图7-3 类之间的继承关系
7.6.2 实例功能介绍
(1)创建Person类
属性有姓名、年龄、性别,创建方法displayinfo,打印这个人的信息。
(2)创建Student类
继承Person类,属性所在大学college,专业profession,重写父类displayinfo方法,调用父类方法打印个人信息外,将学生的学院、专业信息也打印出来。
(3)创建Teacher类
继承Person类,属性所在学院college,专业profession,重写父类displayinfo方法,调用父类方法打印个人信息外,将老师的学院、专业信息也打印出来。
(4)创建二个学生对象,分别打印其详细信息
(5)创建一个老师对象,打印其详细信息
7.6.3 代码实现
代码放在当前目录的createclasses,具体包括存放__init__.py和classes.py。另外,在
当前目录存放主程序run_inst.py。以下是各模块的详细实现。
(1)模块classes.py的代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
'''创建类''' class Person: '''定义父类Person''' def __init__(self,name,age,sex): self.name=name self.age=age self.sex=sex #定义方法,显示基本信息 def displayinfo(self): print("{},{},{})".format(self.name,self.age,self.sex)) #定义Student子类,继承Person类,新增两个参数std_college,std_profession class Student(Person): '''定义子类Student,集成Person类''' def __init__(self,name,age,sex,std_college,std_profession): super(Student,self).__init__(name,age,sex) self.std_college=std_college self.std_profession=std_profession #重写方法,显示学生基本信息 def displayinfo(self): #重写父类中displayinfo方法 print("Student({},{},{},{},{}))".format(self.name,self.age,self.sex,self.std_college,self.std_profession)) #定义子类Teacher,继承Person类,新增两个参数tch_college,tch_profession class Teacher(Person): '''定义子类Teacher,集成Person类''' def __init__(self,name,age,sex,tch_college,tch_profession): super(Teacher,self).__init__(name,age,sex) self.tch_college=tch_college self.tch_profession=tch_profession #重写方法,显示教师基本信息 def displayinfo(self): #重写父类中displayinfo方法 print("Teacher({},{},{},{},{}))".format(self.name,self.age,self.sex,self.tch_college,self.tch_profession)) |
(2)主程序run_inst.py代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#导入类,格式为:from 包名.模块名 import 类名1,类名2 from createclasses.classes import Student,Teacher def main(): #输入一所大学名称 #实例化Student类 st01=Student("张三丰",30,"男","人工智能学院","图像识别") st02=Student("吴用",24,"男","人工智能学院","图像识别") #调用displayinfo方法 st01.displayinfo() st02.displayinfo() #实例化Teacher类 tch01=Teacher("李教授",40,"男","人工智能学院","自然语言处理") tch01.displayinfo() ##判断是否以主程序形式运行 if __name__=='__main__': main() |
7.9 练习
(1)高铁售票系统
高铁某车厢有13行、每行有5列,每个座位初始显示“有票”,用户输入座位(如9,1)后,按回车,对应座位显示为“已售”。
(2)创建一个由有序数值对(x, y) 组成的 Point 类,它代表某个点的 X 坐标和 Y 坐标。X 坐标和 Y 坐标在实例化时被传递给构造函数,如果没有给出它们的值,则默认为坐标的原点。
(3)创建一个名为User的类,其中包含属性first_name和last_name,还有用户简介通常会存储的其他几个属性。在类User中定义一个名为describe_user()的方法,它打印用户信息摘要;再定义一个名为greet_user()的方法,它向用户发出个性化的问候。
创建用户实例,调用上述两个方法。




















![X=[ x_1,x_2,\ldots,x_n] \tag {2.3}](http://www.feiguyunai.com/wp-content/plugins/latex/cache/tex_f3faacff1adc5bae86068b573ec11d67.gif)
![\left[\begin{matrix} x_1\cr x_2 \cr\vdots \cr x_n\end{matrix}\right]\tag{2.4}](http://www.feiguyunai.com/wp-content/plugins/latex/cache/tex_607faf3f0ef417e04b5be7fcc630a1ea.gif)