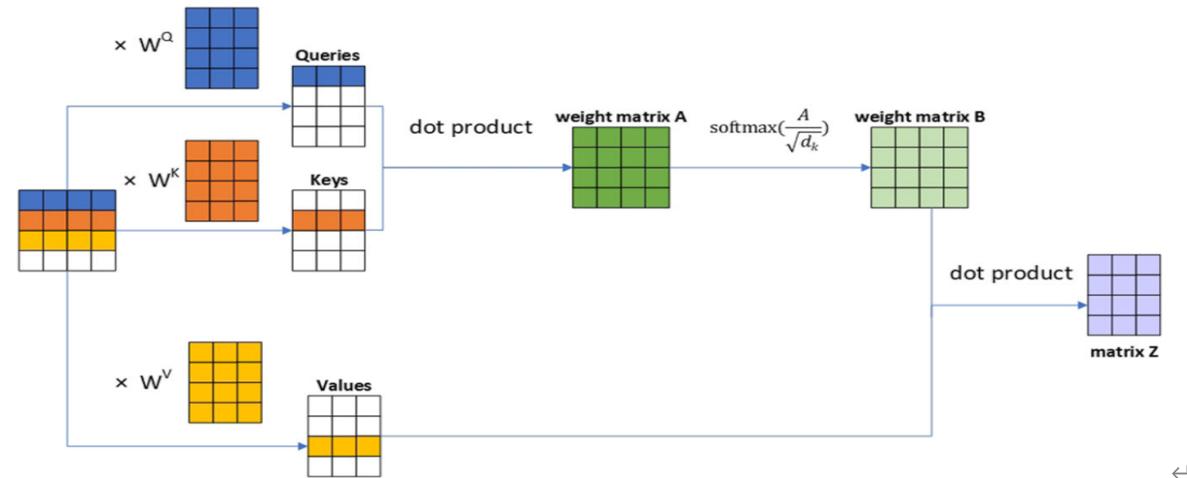
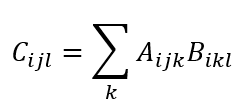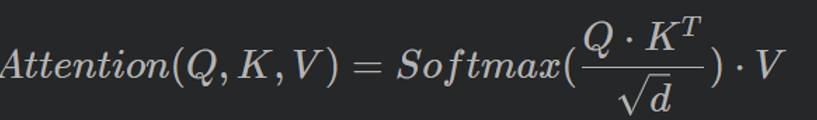使用Swin-Transformer模型实现分类任务
最近几年,Transformer体系结构已成为自然语言处理任务的实际标准,
但其在计算机视觉中的应用还受到限制。在视觉上,注意力要么与卷积网络结合使用,
要么用于替换卷积网络的某些组件,同时将其整体结构保持在适当的位置。2020年10月22日,谷歌人工智能研究院发表一篇题为“An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”的文章。文章将图像切割成一个个图像块,组成序列化的数据输入Transformer执行图像分类任务。当对大量数据进行预训练并将其传输到多个中型或小型图像识别数据集(如ImageNet、CIFAR-100、VTAB等)时,与目前的卷积网络相比,Vision Transformer(ViT)获得了出色的结果,同时所需的计算资源也大大减少。
2021年3月 微软亚洲研究院 发表的论文《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》被评为ICCV 2021 最佳论文!
论文地址:https://arxiv.org/pdf/2103.14030.pdf
项目地址:https://github.com/microsoft/Swin-Transformer
这篇论文的作者主要包括中国科学技术大学的刘泽、西安交通大学的林宇桐、微软的曹越和胡瀚等人。该研究提出了一种新的 vision Transformer,即 Swin Transformer,它可以作为计算机视觉的通用骨干(Backbone)。在CV各应用领域,如分类、目标检测、语义分割、实例分割等都超过基于CNN的网络性能!人们自然会问,为啥能取得如此好的效果?为什么ViT没有取得这么好的成绩?
第一个问题:
因为Swin Transformer吸收了Transformer的固有优点(如通用性强、并发处理、超长视野等优点,如图1-1所示),同时吸收了CNN的平移不变性、局部性、层次性等优点。
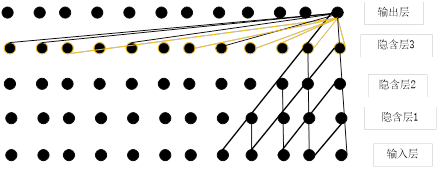
图1-1 卷积神经网络、Transformer架构像素之间的关系
卷积神经网络输出一个像素与输入5个像素点之间建立联系需要经过3个隐含层;而Transformer中输出一个像素点与其他每个像素点建立联系只要一层就可以。
第二个问题:
ViT的计算复杂度没有降低,ViT结构没有层次。如1-2所示:
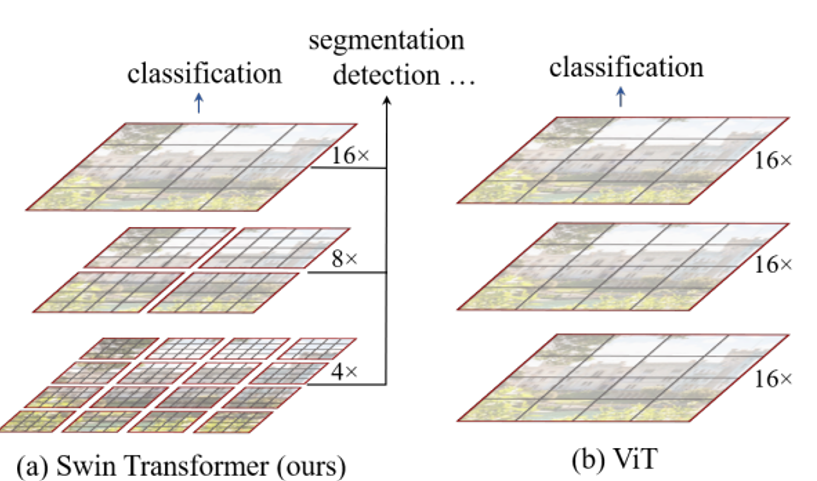
图1-2 Swin Transformer 与ViT层级结构的异同
Swin Transformer是如何实现这些优点的呢?
1、降低计算复杂度:采用局部性,如图1-2所示,把特征图·划分为不重叠的不同尺寸的窗口,计算自注意力时只在这些窗口内。
2、计算在窗口内,但通过窗口shifted方法,可以把相邻窗口的信息连接起来,如图1-3所示。

图1-3 Swin Transformer中windows shifted 的示意图
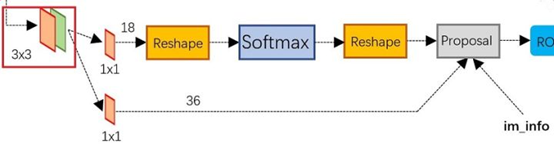
通过Windows shifted后的多头注意力计算简称为SW-MSA的具体计算,window
内的多头注意力计算简称为W-MSA,具体位置可参考图1-4。
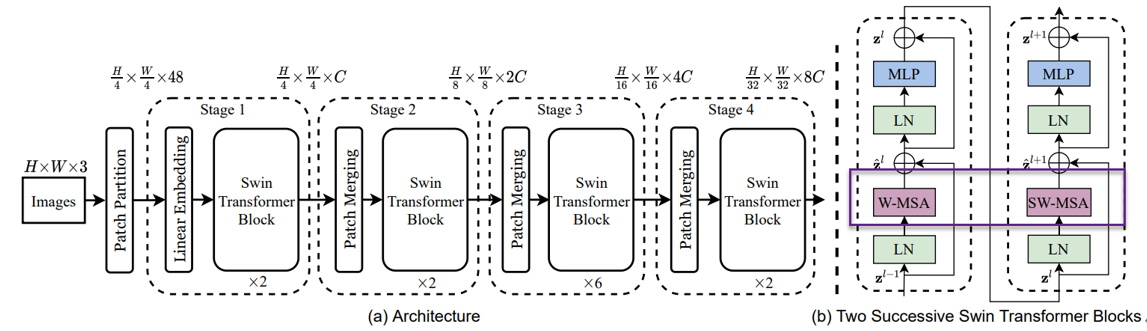
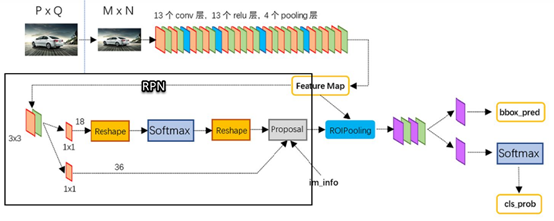
图1-4 Swin Transformer的架构图
这里我们以Swin Transformer为模型,实现对数据CiFar10的分类工作,模型性能得到进一步的提升。以下为用swin-transformer架构实现一个分类任务的详细代码。
1、导入模型
|
|
import os import math import numpy as np import pickle as p import tensorflow as tf from tensorflow import keras import matplotlib.pyplot as plt import tensorflow_addons as tfa from tensorflow.keras import layers %matplotlib inline |
这里使用了TensorFlow_addons模块,它实现了核心 TensorFlow 中未提供的新功能。
tensorflow_addons的安装要注意与tf的版本对应关系,请参考:
https://github.com/tensorflow/addons。
安装addons时要注意其版本与tensorflow版本的对应,具体关系以上这个链接有。
2、定义加载函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
def load_CIFAR_data(data_dir): """load CIFAR data""" images_train=[] labels_train=[] for i in range(5): f=os.path.join(data_dir,'data_batch_%d' % (i+1)) print('loading ',f) # 调用 load_CIFAR_batch( )获得批量的图像及其对应的标签 image_batch,label_batch=load_CIFAR_batch(f) images_train.append(image_batch) labels_train.append(label_batch) Xtrain=np.concatenate(images_train) Ytrain=np.concatenate(labels_train) del image_batch ,label_batch Xtest,Ytest=load_CIFAR_batch(os.path.join(data_dir,'test_batch')) print('finished loadding CIFAR-10 data') # 返回训练集的图像和标签,测试集的图像和标签 return (Xtrain,Ytrain),(Xtest,Ytest) |
3、定义批量加载函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
def load_CIFAR_batch(filename): """ load single batch of cifar """ with open(filename, 'rb')as f: # 一个样本由标签和图像数据组成 # (3072=32x32x3) # ... # data_dict = p.load(f, encoding='bytes') images= data_dict[b'data'] labels = data_dict[b'labels'] # 把原始数据结构调整为: BCWH images = images.reshape(10000, 3, 32, 32) # tensorflow处理图像数据的结构:BWHC # 把通道数据C移动到最后一个维度 images = images.transpose (0,2,3,1) labels = np.array(labels) return images, labels |
4、加载数据
|
|
data_dir = '../data/cifar-10-batches-py' (x_train,y_train),(x_test,y_test) = load_CIFAR_data(data_dir) |
5、定义数据预处理及训练模型的一些超参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
num_classes = 10 input_shape = (32, 32, 3) x_train, x_test = x_train / 255.0, x_test / 255.0 y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) print(f"x_train shape: {x_train.shape} - y_train shape: {y_train.shape}") print(f"x_test shape: {x_test.shape} - y_test shape: {y_test.shape}") plt.figure(figsize=(10, 10)) for i in range(25): plt.subplot(5, 5, i + 1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(x_train[i]) plt.show() |

6、设置一些超参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
patch_size = (2, 2) # 2-by-2 sized patches dropout_rate = 0.03 # Dropout rate num_heads = 8 # Attention heads embed_dim = 64 # Embedding dimension num_mlp = 256 # MLP layer size qkv_bias = True # Convert embedded patches to query, key, and values with a learnable additive value window_size = 2 # Size of attention window shift_size = 1 # Size of shifting window image_dimension = 32 # Initial image size num_patch_x = input_shape[0] // patch_size[0] num_patch_y = input_shape[1] // patch_size[1] learning_rate = 1e-3 batch_size = 128 num_epochs = 100 validation_split = 0.1 weight_decay = 0.0001 label_smoothing = 0.1 |
7、定义几个辅助函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
def window_partition(x, window_size): _, height, width, channels = x.shape patch_num_y = height // window_size patch_num_x = width // window_size x = tf.reshape( x, shape=(-1, patch_num_y, window_size, patch_num_x, window_size, channels) ) x = tf.transpose(x, (0, 1, 3, 2, 4, 5)) windows = tf.reshape(x, shape=(-1, window_size, window_size, channels)) return windows def window_reverse(windows, window_size, height, width, channels): patch_num_y = height // window_size patch_num_x = width // window_size x = tf.reshape( windows, shape=(-1, patch_num_y, patch_num_x, window_size, window_size, channels), ) x = tf.transpose(x, perm=(0, 1, 3, 2, 4, 5)) x = tf.reshape(x, shape=(-1, height, width, channels)) return x class DropPath(layers.Layer): def __init__(self, drop_prob=None, **kwargs): super(DropPath, self).__init__(**kwargs) self.drop_prob = drop_prob def call(self, x): input_shape = tf.shape(x) batch_size = input_shape[0] rank = x.shape.rank shape = (batch_size,) + (1,) * (rank - 1) random_tensor = (1 - self.drop_prob) + tf.random.uniform(shape, dtype=x.dtype) path_mask = tf.floor(random_tensor) output = tf.math.divide(x, 1 - self.drop_prob) * path_mask return output |
8、 定义W-MSA类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 |
class WindowAttention(layers.Layer): def __init__( self, dim, window_size, num_heads, qkv_bias=True, dropout_rate=0.0, **kwargs ): super(WindowAttention, self).__init__(**kwargs) self.dim = dim self.window_size = window_size self.num_heads = num_heads self.scale = (dim // num_heads) ** -0.5 self.qkv = layers.Dense(dim * 3, use_bias=qkv_bias) self.dropout = layers.Dropout(dropout_rate) self.proj = layers.Dense(dim) def build(self, input_shape): num_window_elements = (2 * self.window_size[0] - 1) * ( 2 * self.window_size[1] - 1 ) self.relative_position_bias_table = self.add_weight( shape=(num_window_elements, self.num_heads), initializer=tf.initializers.Zeros(), trainable=True, ) coords_h = np.arange(self.window_size[0]) coords_w = np.arange(self.window_size[1]) coords_matrix = np.meshgrid(coords_h, coords_w, indexing="ij") coords = np.stack(coords_matrix) coords_flatten = coords.reshape(2, -1) relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] relative_coords = relative_coords.transpose([1, 2, 0]) relative_coords[:, :, 0] += self.window_size[0] - 1 relative_coords[:, :, 1] += self.window_size[1] - 1 relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1 relative_position_index = relative_coords.sum(-1) self.relative_position_index = tf.Variable( initial_value=tf.convert_to_tensor(relative_position_index), trainable=False ) def call(self, x, mask=None): _, size, channels = x.shape head_dim = channels // self.num_heads x_qkv = self.qkv(x) x_qkv = tf.reshape(x_qkv, shape=(-1, size, 3, self.num_heads, head_dim)) x_qkv = tf.transpose(x_qkv, perm=(2, 0, 3, 1, 4)) q, k, v = x_qkv[0], x_qkv[1], x_qkv[2] q = q * self.scale k = tf.transpose(k, perm=(0, 1, 3, 2)) attn = q @ k num_window_elements = self.window_size[0] * self.window_size[1] relative_position_index_flat = tf.reshape( self.relative_position_index, shape=(-1,) ) relative_position_bias = tf.gather( self.relative_position_bias_table, relative_position_index_flat ) relative_position_bias = tf.reshape( relative_position_bias, shape=(num_window_elements, num_window_elements, -1) ) relative_position_bias = tf.transpose(relative_position_bias, perm=(2, 0, 1)) attn = attn + tf.expand_dims(relative_position_bias, axis=0) if mask is not None: nW = mask.get_shape()[0] mask_float = tf.cast( tf.expand_dims(tf.expand_dims(mask, axis=1), axis=0), tf.float32 ) attn = ( tf.reshape(attn, shape=(-1, nW, self.num_heads, size, size)) + mask_float ) attn = tf.reshape(attn, shape=(-1, self.num_heads, size, size)) attn = keras.activations.softmax(attn, axis=-1) else: attn = keras.activations.softmax(attn, axis=-1) attn = self.dropout(attn) x_qkv = attn @ v x_qkv = tf.transpose(x_qkv, perm=(0, 2, 1, 3)) x_qkv = tf.reshape(x_qkv, shape=(-1, size, channels)) x_qkv = self.proj(x_qkv) x_qkv = self.dropout(x_qkv) return x_qkv |
9、定义SwinTransformer 模块
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 |
class SwinTransformer(layers.Layer): def __init__( self, dim, num_patch, num_heads, window_size=7, shift_size=0, num_mlp=1024, qkv_bias=True, dropout_rate=0.0, **kwargs, ): super(SwinTransformer, self).__init__(**kwargs) self.dim = dim # number of input dimensions self.num_patch = num_patch # number of embedded patches self.num_heads = num_heads # number of attention heads self.window_size = window_size # size of window self.shift_size = shift_size # size of window shift self.num_mlp = num_mlp # number of MLP nodes self.norm1 = layers.LayerNormalization(epsilon=1e-5) self.attn = WindowAttention( dim, window_size=(self.window_size, self.window_size), num_heads=num_heads, qkv_bias=qkv_bias, dropout_rate=dropout_rate, ) self.drop_path = DropPath(dropout_rate) self.norm2 = layers.LayerNormalization(epsilon=1e-5) self.mlp = keras.Sequential( [ layers.Dense(num_mlp), layers.Activation(keras.activations.gelu), layers.Dropout(dropout_rate), layers.Dense(dim), layers.Dropout(dropout_rate), ] ) if min(self.num_patch) < self.window_size: self.shift_size = 0 self.window_size = min(self.num_patch) def build(self, input_shape): if self.shift_size == 0: self.attn_mask = None else: height, width = self.num_patch h_slices = ( slice(0, -self.window_size), slice(-self.window_size, -self.shift_size), slice(-self.shift_size, None), ) w_slices = ( slice(0, -self.window_size), slice(-self.window_size, -self.shift_size), slice(-self.shift_size, None), ) mask_array = np.zeros((1, height, width, 1)) count = 0 for h in h_slices: for w in w_slices: mask_array[:, h, w, :] = count count += 1 mask_array = tf.convert_to_tensor(mask_array) # mask array to windows mask_windows = window_partition(mask_array, self.window_size) mask_windows = tf.reshape( mask_windows, shape=[-1, self.window_size * self.window_size] ) attn_mask = tf.expand_dims(mask_windows, axis=1) - tf.expand_dims( mask_windows, axis=2 ) attn_mask = tf.where(attn_mask != 0, -100.0, attn_mask) attn_mask = tf.where(attn_mask == 0, 0.0, attn_mask) self.attn_mask = tf.Variable(initial_value=attn_mask, trainable=False) def call(self, x): height, width = self.num_patch _, num_patches_before, channels = x.shape x_skip = x x = self.norm1(x) x = tf.reshape(x, shape=(-1, height, width, channels)) if self.shift_size > 0: shifted_x = tf.roll( x, shift=[-self.shift_size, -self.shift_size], axis=[1, 2] ) else: shifted_x = x x_windows = window_partition(shifted_x, self.window_size) x_windows = tf.reshape( x_windows, shape=(-1, self.window_size * self.window_size, channels) ) attn_windows = self.attn(x_windows, mask=self.attn_mask) attn_windows = tf.reshape( attn_windows, shape=(-1, self.window_size, self.window_size, channels) ) shifted_x = window_reverse( attn_windows, self.window_size, height, width, channels ) if self.shift_size > 0: x = tf.roll( shifted_x, shift=[self.shift_size, self.shift_size], axis=[1, 2] ) else: x = shifted_x x = tf.reshape(x, shape=(-1, height * width, channels)) x = self.drop_path(x) x = x_skip + x x_skip = x x = self.norm2(x) x = self.mlp(x) x = self.drop_path(x) x = x_skip + x return x |
10、抽取特征
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
class PatchExtract(layers.Layer): def __init__(self, patch_size, **kwargs): super(PatchExtract, self).__init__(**kwargs) self.patch_size_x = patch_size[0] self.patch_size_y = patch_size[0] def call(self, images): batch_size = tf.shape(images)[0] patches = tf.image.extract_patches( images=images, sizes=(1, self.patch_size_x, self.patch_size_y, 1), strides=(1, self.patch_size_x, self.patch_size_y, 1), rates=(1, 1, 1, 1), padding="VALID", ) patch_dim = patches.shape[-1] patch_num = patches.shape[1] return tf.reshape(patches, (batch_size, patch_num * patch_num, patch_dim)) class PatchEmbedding(layers.Layer): def __init__(self, num_patch, embed_dim, **kwargs): super(PatchEmbedding, self).__init__(**kwargs) self.num_patch = num_patch self.proj = layers.Dense(embed_dim) self.pos_embed = layers.Embedding(input_dim=num_patch, output_dim=embed_dim) def call(self, patch): pos = tf.range(start=0, limit=self.num_patch, delta=1) return self.proj(patch) + self.pos_embed(pos) class PatchMerging(tf.keras.layers.Layer): def __init__(self, num_patch, embed_dim): super(PatchMerging, self).__init__() self.num_patch = num_patch self.embed_dim = embed_dim self.linear_trans = layers.Dense(2 * embed_dim, use_bias=False) def call(self, x): height, width = self.num_patch _, _, C = x.get_shape().as_list() x = tf.reshape(x, shape=(-1, height, width, C)) x0 = x[:, 0::2, 0::2, :] x1 = x[:, 1::2, 0::2, :] x2 = x[:, 0::2, 1::2, :] x3 = x[:, 1::2, 1::2, :] x = tf.concat((x0, x1, x2, x3), axis=-1) x = tf.reshape(x, shape=(-1, (height // 2) * (width // 2), 4 * C)) return self.linear_trans(x) |
11、构建模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
input = layers.Input(input_shape) x = layers.experimental.preprocessing.RandomCrop(image_dimension, image_dimension)(input) x = layers.experimental.preprocessing.RandomFlip("horizontal")(x) x = PatchExtract(patch_size)(x) x = PatchEmbedding(num_patch_x * num_patch_y, embed_dim)(x) x = SwinTransformer( dim=embed_dim, num_patch=(num_patch_x, num_patch_y), num_heads=num_heads, window_size=window_size, shift_size=0, num_mlp=num_mlp, qkv_bias=qkv_bias, dropout_rate=dropout_rate, )(x) x = SwinTransformer( dim=embed_dim, num_patch=(num_patch_x, num_patch_y), num_heads=num_heads, window_size=window_size, shift_size=shift_size, num_mlp=num_mlp, qkv_bias=qkv_bias, dropout_rate=dropout_rate, )(x) x = PatchMerging((num_patch_x, num_patch_y), embed_dim=embed_dim)(x) x = layers.GlobalAveragePooling1D()(x) output = layers.Dense(num_classes, activation="softmax")(x) |
12、训练模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
model = keras.Model(input, output) model.compile( loss=keras.losses.CategoricalCrossentropy(label_smoothing=label_smoothing), optimizer=tfa.optimizers.AdamW( learning_rate=learning_rate, weight_decay=weight_decay ), metrics=[ keras.metrics.CategoricalAccuracy(name="accuracy"), keras.metrics.TopKCategoricalAccuracy(5, name="top-5-accuracy"), ], ) history = model.fit( x_train, y_train, batch_size=batch_size, epochs=num_epochs, validation_split=validation_split, ) |
13、可视化运行结果
|
|
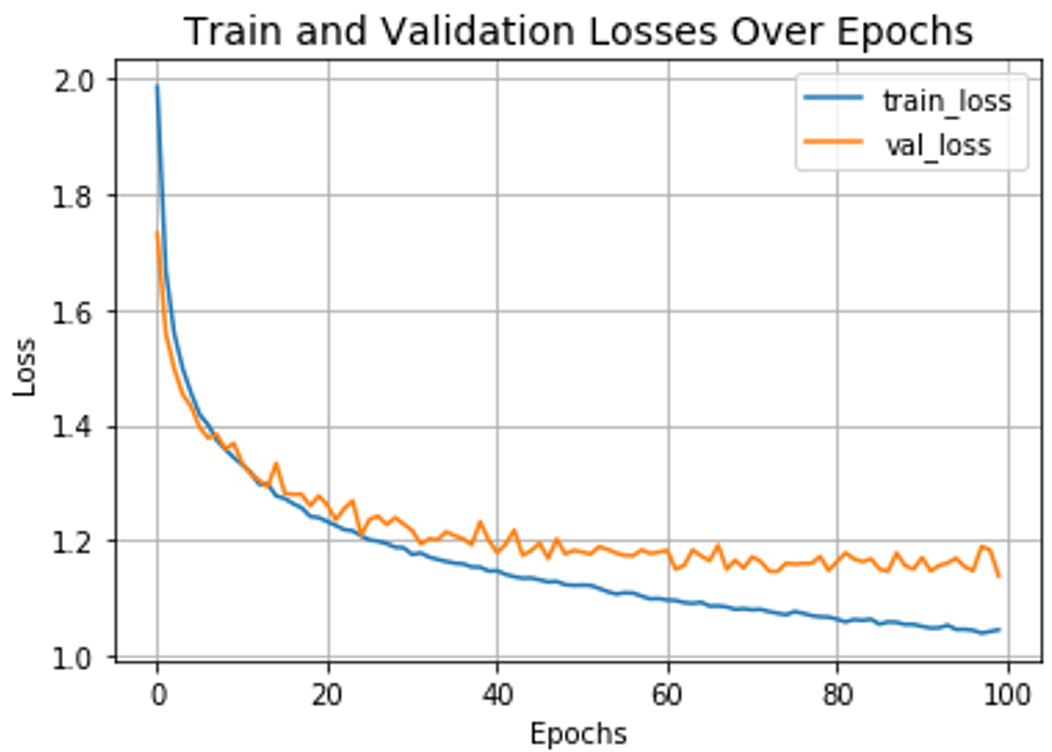
plt.plot(history.history["loss"], label="train_loss") plt.plot(history.history["val_loss"], label="val_loss") plt.xlabel("Epochs") plt.ylabel("Loss") plt.title("Train and Validation Losses Over Epochs", fontsize=14) plt.legend() plt.grid() plt.show() |
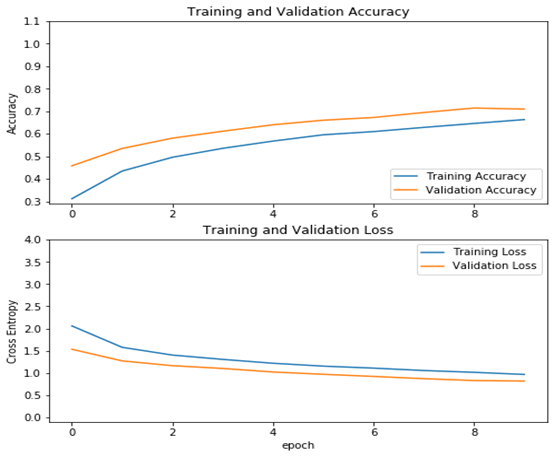
运行结果
14、测试结果
|
|
loss, accuracy, top_5_accuracy = model.evaluate(x_test, y_test) print(f"Test loss: {round(loss, 2)}") print(f"Test accuracy: {round(accuracy * 100, 2)}%") print(f"Test top 5 accuracy: {round(top_5_accuracy * 100, 2)}%") |
15、可视化测试结果
|
|
plt.plot(history.history["accuracy"], label="train_accuracy") plt.plot(history.history["val_accuracy"], label="val_accuracy") plt.plot(history.history["val_top-5-accuracy"], label="val_top5_accuracy") plt.xlabel("Epochs") plt.ylabel("Loss") plt.title("Train and Validation Losses Over Epochs", fontsize=14) plt.legend() plt.grid() plt.show() |

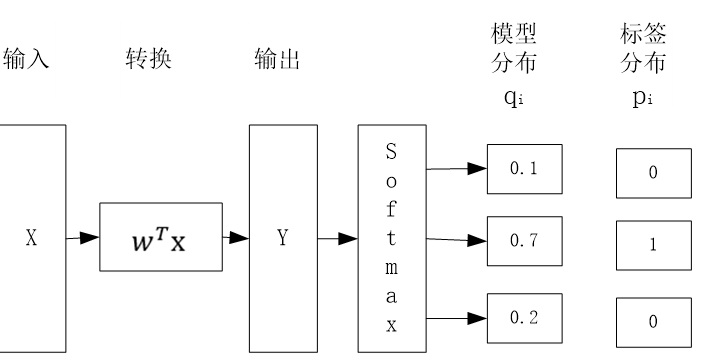


 表示样本i的真实类别为1,否则取0。
表示样本i的真实类别为1,否则取0。 表示样本i属于类别j的预测值或概率值。
表示样本i属于类别j的预测值或概率值。